People make a lot of claims about digestion, nutrition, and diet on the internet. … It is helpful, then, to have a heuristic to tell the iconoclastic geniuses apart from the grifters and bullshitters.
I end up with a pretty similar strategy to what I do when I see or hear random claims about finance (e.g. on Twitter.) I keep some questions in my head that test basic understanding, then either ask the person or, if I feel like I have enough data, imagine how they would answer. …
Some of these questions have objectively correct answers, others are more of an opportunity to say something stupid that hopefully, the person you’re talking to will pass up. “I don’t know” is a wonderful answer.
SovietRxiv — Translating forgotten Soviet research papers into English.
The Independent Science Society is testing if good science can be done the ol’ fashioned way — at home and in your free time.
Doing science means hypothesising and testing the natural world. This requires a lot less than people think. Most scientists in history worked independently. They worked outside of formal institutions, and often part-time. We think more people should be doing this.
“Since time immemorial, man has sought to destroy Florida. But people may not realize how close the United States once came to severing that cursed peninsula from the mainland and liberating us all.” Visualizing the Past (Part Four)
The big news in blogging this month is Inkhaven 2 (sponsored by WordPress dot com). The first Inkhaven happened back in November 2025, and this one is even more. Wow.
This time, about 55 residents (it’s hard to count exactly since some staff members are also ~residents) published one blog post of at least 500 words every day all 30 days of April, and only one person failed to publish each day before midnight! Some people even managed to consistently post more than once a day. Wow again. The organizers will likely be running another Inkhaven in autumn 2026, so if this has you feeling curious, you can express your interest here.
Below is a list of some of the Inkhaven blog posts we liked a lot. We can’t claim that these are the best, or even our favorite posts. Some of our favorite posts, we have almost certainly forgotten to list here. There are simply too many. And the list is biased towards posts that came out early in Inkhaven, because we are still working to catch up on the more than 1,500 posts and more than 800,000 words produced. But all that said, here’s a selection:
Other highlights from Inkhaven include Speedhaven, “a one-night speed-writing competition at Inkhaven Fair, 25 April 2026” where “writers raced the clock; the audience picked the winners.” You can read the entries on the archive, including a riff on one of the best memes of all time: Bottomless Pit Supervisor Performance Review.
We should also announce the third issue of our science zine THE LOOP. It is available here, and what’s more, this and all previous (and future) issues are now available on THE LOOP SITE at looploop.blog — enjoy! For commentary on one submission, you may also like conq’s piece In the Loop.
Finally, blogger and statistician Andrew Gelman weighs in on Inkhaven: Blogging and writing style. We are tickled by some of his descriptions, such as: “I started to read the very first post, Kill Yourself Cave, by Remy, but then halfway through some sort of ad popped up and I couldn’t read the rest–I guess I’d need to buy some sort of subscription?”
This April will see the return of Inkhaven, a blogging residency program where you have to write and publish at least 500 words a day, every day, for a whole month, or they feed you to the hounds kick you out. As bloggers who mostly write 10,000-plus-word effortposts, this format is both fascinating and alienating to us. We’ve never written only 500 words in our lives.
While Inkhaven has been a big success, the format isn’t naturally conducive to effortposts (long, detailed, well-researched posts that clearly took significant time and effort to write). For example, consider this reflection from one resident, Amanda From Bethlehem:
I came to Lighthaven with a draft folder full of half-finished pieces that I wanted to take across the finish line. A lot of them were effortposts that needed extensive revisions. I struggle with procrastination and perfectionism, so I figured that Inkhaven would be the perfect environment for me.
…
The problem with effortposts is that they took a long time to write. Even if I already had a draft. Especially if I already had a draft, which I showed to Scott Alexander during his Office Hours, and he (very politely) ripped it to shreds right before my eyes, and then I had to completely re-write it.
…
If you’re interested in doing the next Inkhaven, don’t expect to get very many effortposts out the door.
This was a frequent comment. A post of ~500 words is good practice and builds important skills, like finishing and shipping, but many of the best and most famous blog posts are effortposts. Many people would like to write or finish more of them, it’s a natural aspiration. One of the organizers, Ben Pace, even considered in his retrospective the idea of a “Weekhaven”:
What might a ‘Weekhaven’ look like?
Each week, you write a single, 3,500+ word effortpost
Writers could spend whole days reading and doing research, without writing.
It would have more narrative arc to the week. Currently an idea is brought up today, discussed, and published same day. In Weekhaven, they’d get feedback on it multiple times at different levels of development.
Editing would be more of a process; you could take a finished essay and restructure it, or re-write whole sections.
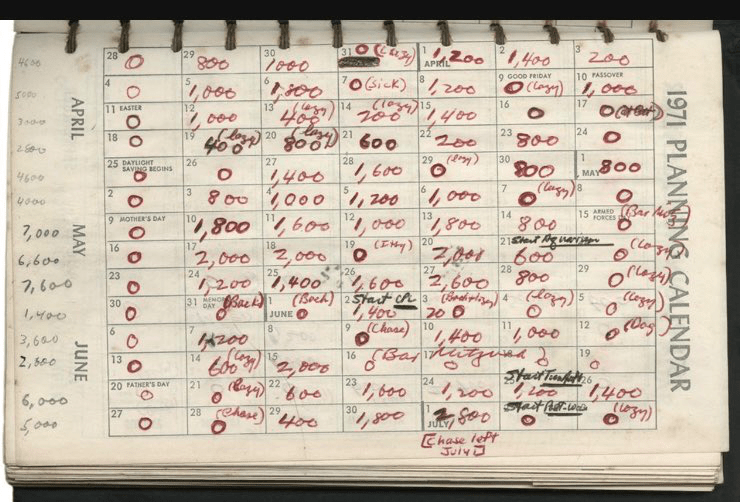
But there may not be a need for such a drastic change in format. After all, even great works are produced in smaller chunks. Robert Caro, who produces biographies of truly monumental length, aims for a mere 1,000 words per day, as seen on this calendar:
So here’s a suggestion for how to produce effortposts while still getting 500 words out the door every day no problem. We call it effortscaffolding.
Each day, wake up and work on your effortpost until a specific time, let’s say 5 pm. After that point, no more working on your effortpost. Instead, write a reflection about what you did that day and where the piece is at. This will almost certainly come to 500 words. If you’re a programmer, think of it as a slightly long git commit, a snapshot of the effortpost at that point in time. That’s your post for the day, publish it.
Or if you prefer, you can start the day by writing about the current state of the effortpost, and what you plan to work on that day. This will also almost certainly come to 500 words, and you can publish that. Or write and publish both.
If you’re really stuck, write the reflection as an email to a friend who’s interested in the topic. Or pull them up on Discord and literally tell them about it until you reach 500 words. Have them ask you questions about the project to draw out more ideas. (Or just write 500 words of questions to yourself.) Then copy your Discord messages into a document and publish that. Boom, done.
This concept is also a nice fit for Inkhaven because of the “firehose problem”. One post of >500 words a day creates a real firehose of writing, and even if they truly adore you, most readers don’t want to get 30 emails in one month. So Inkhaven suggested you could choose to only send a small number of your posts as email updates, and not send the others.
These scaffolding posts would be good ones not to send. Only true diehard readers will want to see them, and anyone who does choose to read them will get the pleasure of living slightly in the future, knowing about the effortpost before it drops.
It’s not even a waste of prose, because you can mine your daily reflections for material and roll that into the effortpost itself. If you have one big idea that you want to think about, or one big problem that you want to solve, you can write 500-word posts about the idea/problem all month long and then stitch ‘em together at the end.
Honestly, effortscaffolding might be good practice for effortposts in general. A daily roadmap and/or reflection will probably help you think about the effortpost more clearly. The sense of progress is good for morale. And people love dev diaries. Plus they’re just interesting artifacts.
you can expect the typical PI to be very reluctant to fire you for doing a different mix of research than they expected. They may express displeasure in a variety of ways, but as long as you’re producing results, you’ll probably have a long runway of PI annoyance before any disciplinary action takes place.
This website hosts the complete unrevised edition of Dale Carnegie’s masterpiece How to Win Friends and Influence People. … We use the unrevised edition because we believe the revised edition (the revisions were done by Carnegie’s relatives after his death) forcefully makes the language of the book gender neutral and politically correct and takes away from the originality of the work.
(WARNING: includes graphic images of a man performing cranial surgery on himself with a dentist’s drill. DO NOT ATTEMPT AT HOME.)THROUGH THE BLIND HOLE. Amazingly, this story appears to be true.
Why Everyone Loves Japan — “Even more astonishing than my interview with Kodansha is the fact that to this day, I have not met a single Japanese person who has heard of the word ‘weeb’.”
We simply do not know what a human being who has read a billion books looks like, if it is even feasible, so an immortal who has read a billion books feels about as smart as a human who has read a few dozen.
Strategy means sticking to what matters the most. On the science front, that’s getting results and writing about them. And so I try to spend most of my science time on this. These are the only things that matter. And so if I’m not doing either, I question why. … To reiterate – doing science means learning about the world, then communicating the results. That’s the ultimate end point, so it’s the thing I try to spend the most time on.
We don’t often think about statistics as being in the same category as a microscope. But if you think about it, it’s a tool (built with math rather than physical engineering) that enables us to observe phenomena in the world that are invisible with the naked eye. … Statistics is a powerful instrument, but like any instrument, it provides evidence that then needs interpretation to infer what’s going on with the underlying phenomena – it doesn’t generate truth directly. Look at the X-ray crystallography image of DNA: it’s nowhere near obvious that you’re looking at a double helix. Statistics is the same. The problem is that many people – both practitioners using the tool and people listening to them – treat it as some kind of oracle.
The first time I had the sense that I really needed a green vegetable, it shocked me. It was a new feeling. I’d had cravings before—the standard kind, for carbs and sweets and salty crunchy junk—and this was similar, but it was also distinct. There was a subtlety to it, a strength without the familiar urgency of carb addiction. Make no mistake: I’d always enjoyed green vegetables. But even in the deepest depths of my finals week burrito marathons, I’d never once craved them.
In a hostile information environment, you want surface, NOT solve.
…
If the blind spot light stops working, you might think it was safe to turn.
If your fact checker made an error, you might update your world model with the error.
Reliance on these kinds of signals I think is worse than not having a signal at all. If I know that I do not know (whether there is a car there), I am forced to manually turn my head, or be more careful as I turn.
This month, there was Inkhaven. A total of 41 residents published one piece of writing of at least 500 words every single day for the 30 days of November. That’s a lot of essays, blog posts, poems, short stories, and long-ass tweets. As a result we cannot claim that the few entries below are the best, or even our favorites. We have not remotely read all of them, or even as many as we would like. So all we will claim is, this is a selection:
For the psychologists in the room, we’d like to first call your attention to croissanthology’s replication of psych classic Loftus & Palmer (1974), or the “do people say that cars were going faster when they hear they ‘smashed’ into each other as opposed to hit/bumped/etc.” study. The materials were put together in just a few hours, and with (special thanks to) Aella helping to recruit participants, croissanthology soon 10x’d the original sample size (446 vs 45 in the original), and did not find any evidence for the supposed effect — in fact, it trended in the opposite direction. This study isn’t perfect, but it sure is evidence against the original claim. And if people do think the original claims were right, we’d love to see other replications.
A good software engineer interested in supporting better psychology research could probably do a lot of good work contributing features to these frameworks. PsychoPy for example seems to support all sorts of fancy things like eye tracking however you require custom code or hacks in order to set up a simple “rate this statement from 1-5” multiple choice scale
There was a Renaissance natural historian named Ole Worm who had a pet great auk and proved that lemmings didn’t appear out of thin air. (h/t Georgia Ray)
When the Tofurky research division is working on new alternative protein products, they tend to worry about taste. They tend to worry about appearance. And they tend to worry about texture.
If they’re making an alternative (i.e. no-animals-were-harmed) turk’y slice, they want to make it look, smell, and taste like the real thing, and they care about proper distribution of fat globules within the alt-slice.
But here’s a hot take, might even be true: people don’t mainly eat food for the appearance. After all, they would still eat most foods in the dark. They don’t mainly eat foods for the texture, the taste, or even for the distribution of fat globules. People eat food for the nutrition.
Who’s hungry for a hot take?
This is why people don’t eat bowls of sawdust mixed with artificial strawberry flavoring, even though we have invented perfectly good artificial strawberry flavoring. You could eat flavors straight up if you wanted to, but people don’t do that. You want ice cream, not cold dairy flavor #14, and you can tell the difference. This is a revealed preference: people don’t show up for the flavors.
A food has the same taste, smell, texture, retronasal olfaction, and general mouthfeel when you start eating it as when you finish. If you were eating for these features, you would never stop. But people do stop eating — just see how far you can get into a jar of frosting. The first bite may be heavenly, but you won’t get very deep. The gustation features of the frosting — taste, smell, etc. — don’t change. You stop eating because you are satisfied.
Assuming you buy this argument, that the real motivation behind eating food is nutrition, then why do people care about flavor (and appearance, and texture, etc.) at all? We’re so glad you asked:
People can detect some nutrients as soon as they hit the mouth: the obvious one is salt. It’s easy to figure out if a food is high in sodium; you just taste it. As a result, it’s easy to get enough salt. You just eat foods that are obviously salty until you’ve gotten enough.
But other nutrients can’t be detected immediately. If they’re bound up deep within the food and need to be both digested and absorbed, it might take minutes, maybe hours, maybe even longer, before the body registers their presence. To get enough of these nutrients, you need to be able to recognize foods that contain these nutrients, even when you can’t detect them from chewing alone.
This is where food qualities come in. Taste and texture are signs you learn that help you predict what nutrients are coming down the pipeline. Just like how you learn that thud of a candy bar at the bottom of a vending machine predicts incoming sugar. The sight of a halal van predicts greasy food imminently going down your drunk gullet. How you learn that the sight of the Lays bag means that there is something salty inside, even though you can’t detect salt just from looking at it. You also learn that the taste of lentils means that you will have more iron in your system soon, even if you can’t detect the iron from merely putting the lentils in your mouth.
To give context, this is coming from the model of psychology we described in our book, The Mind in the Wheel. In this model, motivation is the result of many different drives, each trying to maintain some kind of homeostasis, and the systems creating the drives are called governors. In eating behavior, different governors track different nutrients and try to make sure you maintain your levels, hit your micros, get enough of each.
There’s still a lot we don’t know about this, but to give one example we’re confident about, there’s probably one governor that makes sure you get enough sodium, which is why you add salt to your food. There’s also at least one governor that keeps track of your fat intake, at least one governor clamoring for sugar, probably a governor for potassium. Who knows.
Governors only care about hitting their goals. Taste and texture are just the signs they use to navigate. And this is where the problem comes in.
Consider that for all its flaws, turkey is really nutritious. Two slices or 84 grams of turkey contains 29% of the Daily Value (DV) for Vitamin B12, 46% of the DV for Selenium, 49% of the DV for Vitamin B6, and 61% of the DV for Niacin (vitamin B3).
Tofurkey is not. As far as we can tell, it doesn’t contain any selenium or B vitamins. Not clear if it contains zinc or phosphorus either. Maybe this is wrong, but at the very least, it doesn’t appear that Tofurkey are trying to nutrition-match. And that may be the key to why these products are still not very popular. If you try to compete with turkey on taste and texture, but people choose foods based on nutrition, you’re gonna have a problem.
This is just one anecdote, but: our favorite alternative protein is Morningstar Farms vegetarian sausage links. And guess what food product contains 25% DV of vitamin B6, 50% DV of niacin, and 130% DV of vitamin B12 per two links? Outstanding in its field.
In the Vegan War Room
We believe this has strategic implications. So please put on your five-star vegan general hat, as we lead you into your new imagined role as commander of the faithful.
General, as you may be aware, the main way our culture attempts to change behavior is by introducing conflict. We attempt to make people skinny by mocking them, which pits the shame governor against the hunger governors. We control children by keeping them inside at recess or making them stay after class, which pits the governors that make them act up in class against the governors that make them want to run around with their friends. Or we control them by saying, no dessert until you eat your brussel sprouts.
This is an unfortunate holdover from the behaviorists, who once dominated the study of psychology. In behaviorism, you get more of what you reward, and less of what you punish. Naturally when they asked themselves “how to get less of a behavior?” the answer they came up with was “punish!” But this is a fundamentally incomplete picture of psychology. Reward and punishment don’t really exist — motivation is all about governors learning what will increase or decrease their errors. While you can decide to pit governors against each other, this approach has serious limitations. It just doesn’t work all that well.
First of all, conflict between governors is experienced as anxiety. So while you can change someone’s behaviour by causing conflict, you’ll also make them seriously anxious. This is fine, we guess, if you hate them and want them to feel terrible all the time. But it’s more than a little antisocial.
Anyone who’s the target of punishment will see what is happening. They don’t want to feel anxious all the time, and they especially don’t want to feel anxious about doing what to them are normal, everyday things. If you try to change their behavior in this way, they will find you annoying and do their best to avoid you, so you can’t create so much conflict inside them. Imagine how much less effective this strategy is, compared to finding a method of convincing that people don’t avoid, or that they might even actively seek out.
On top of this, conflict dies out without constant maintenance. In the short term you can convince people that they will be judged if they have premarital sex, but this lesson will quickly fade, especially if they see people getting busy without consequence. The only way to keep this in check is to run a constant humiliation campaign, where people are reminded that they will be shamed if they ever step out of line. This is expensive, neverending, and, for the obvious reasons, unpopular. Scolding can work in limited ways, but nobody likes a scold.
Many attempts to convince people to become vegan, or even to simply eat less meat, follow this strategy — they try to make people eat less meat by taking the governors that normally vote for meat-eating (several nutritional governors, and perhaps some other governors, like the one for status) and opposing them with some other drive.
You can tell people that they are bad people for eating meat, you can say that they will be judged, shamed, or ostracized. You can tell them that eating meat is bad for their health or bad for the environment. This might even be true. But just because it’s true doesn’t mean it’s motivating. This strategy won’t work all that well. It only causes conflict, because the drives that vote against eating meat will be strenuously opposed by the drives that have always been voting to eat meat to begin with.
But you don’t need to fight your drives. Better to provide a substitute.
No one takes a horse to their dentist appointments anymore. Cars are just vegan carriages; hence “horseless carriage”. We used to kill whales for oil. We don’t do that anymore, and it’s not because people became more compassionate. It’s because whale oil lamps got beat out by better alternatives, like electric lighting. People substitute one good for another when it is either strictly better at satisfying the same need(s), or better in some way — for example, not as good, but much cheaper, or much faster, or much more convenient.
Whale oil lamps burned bright, but with a disagreeable fishy smell. Imagine if in the early days of alternative lighting, they had tried to give whale oil substitutes like kerosene or electric lights the same fishy smell, imagining that this would make it easier to compete with whale oil. No! They just tried to address the need the whale oil was addressing, namely light, without trying to capture any of the incidental features of whale oil. They offered a superior product, or sometimes one that was inferior but cheaper, and that was enough to do the job. We don’t run whale ships off Nantucket any more.
So if you want people to eat less meat, if you want more people to become vegan, you shouldn’t roll out alternative turkey, salami, or anything else. You should provide substitutes, competing superior products, that satisfy the same drives without any reference to the original product. Ta-daaaa.
No one eats yogurt because they have an innate disposition for yogurt. Instead, they eat it because yogurt fulfills some of their needs. If they could get those needs met through a different product, they probably would, especially if the alternative is faster / easier / cheaper.
For the sake of illustration, let’s say that turkey contains just three nutrients, vitamins X, Y, and Z.
If you make an alternative turkey that matches the real thing in taste and texture, but provides none of the same nutrients, then despite the superficial similarity, you’re not even competing in the same product category. It’s like selling cardboard boxes that look like cars but that can’t actually get you to work — however impressive they might look, they don’t meet the need. People will not be inclined to replace their real turkey with your alternative one, at least not without considerable outside motivation. You will be working uphill.
Making a really close match can actually be counterproductive. If an alternative food looks/tastes/smells very similar to an original food, but it doesn’t contain the same nutrition, this is basically the same as gaslighting your governors. And the better the taste match, the more confusing this is.
Think about it from the perspective of the selenium governor. You’re trying to encourage behaviors that keep you in the green zone on your selenium levels, mostly by predicting which foods will lead to more selenium later. But things have recently become really confusing. About half the time you taste turkey flavor and texture, you get more selenium a few hours later. The other half of the time, you encounter turkey flavor and texture, but the selenium never arrives.
By eating alternative proteins that taste like the “real thing”, you end up seriously confusing your governors, with basically no benefit.
We recently tried one of these new vegan boxed eggs. It did have the appearance of scrambled eggs, and it curdled much like scrambled eggs. It even tasted somewhat like scrambled eggs. But the experience of eating it was overall terrible. Not the flavor — the deep sense that this was not truly filling, not a food product. Despite simulating the experience of eggs quite closely, we did not want it. Maybe because it was not truly nutritious.
If you make an alternative turkey that contains vitamins X, Y, and Z, you will at least be providing a real substitute. People will have a natural motivation to eat your alternative turkey. But if you do this, you’re still in direct competition with the original turkey. You’re in its niche, it is an away game for you and a home game for turkey. You have to convince the consumer’s mind that your alt-turkey is worth switching to, and that takes a lot of convincing. People prefer the familiar. Unless the new product is much better in some way, they won’t switch.
If you are trying to replicate turkey, you need to make a matching blob that matches real turkey on all the dimensions people might care about. A product exactly like that is hard to make at all, and forget about doing it while also being cheap, available, and satisfying. This is why it’s an uphill battle, you’re trying to meet turkey exactly.
Those of us who have never tasted tukrey are in ignorance still, our subconscious has no idea that turkey slices would be a great source of vitamin X. We’re not tempted. But people who have tried turkey before have tasted the deli meat of knowledge, and there’s no losing that information once you have it. Vitamin X governor gets what vitamin X governor wants, so these people will always feel called to the best source of vitamin X they’re aware of. You’ll never convince the vitamin X governor that turkey is a bad source of vitamin X; you’ll get more mileage out of giving it a better way to get what it wants!
So instead of shaming, or offering mock meats, the winning strategy might be to just come up with new, original vegan foods that are very good sources of vitamins X, Y, and/or Z. Just make vitamin X drinks, vitamin Y candies, and vitamin Z spread. If you don’t try to mimic turkey, then you’re not in competition with turkey in any way. You don’t need to convince people that it’s better than turkey — you just need to convince them that it’s nutritious and delicious. Why try to copy turkey when you can beat it at its own game?
You don’t need alt-turkey to be all turkey things to all turkey people. As long as people get their needs covered in a way that satisfies, they’ll be happy.
It seems like it would be easier to make a good source of phosphorus, than to make a good source of phosphorus PLUS make it resemble yogurt as much as possible. Alternative proteins that try to mimic existing foods will always be at a disadvantage in terms of quality, taste, and cost, simply because trying to do two things is harder than doing one thing really well. You’ll lose out on a lot of tradeoffs.
If we created new food products that contain all the nutrients that people currently get from meat, except tastier, cheaper, or even just more convenient, people would slowly add these foods to their diet. Over time, these foods would displace turkey and other meats as superior substitutes, just like electric lights replaced gas lamps, or like cell phones eclipsed the telegraph. Without even thinking about it, people will soon be eating much less meat than they did before. And if these new foods are good enough sources of the nutrients we need, then in a generation or two people may not be eating meat at all. After all, meat is a bit of a hassle to produce and to cook. Not like my darling selenium drink.
We see this already in some natural examples. Tofu is much more popular in countries like China, Korea, Japan, where it is simply seen as a food, than it is in the US, where it is treated as a meat substitute. You don’t frame your substitute as being in the same category as your competitors unless you really have to. That’s just basic marketing.
We have a friend whose family is from Cuba. She tells a story about how her grandmother was bemused when avocado toast got really popular in the 2010s. When asked why she found this so strange, her grandmother explained that back in Cuba, the only reason you would put avocado on your toast was if you were so dirt poor you couldn’t afford butter. It was an extremely shameful thing to have to put avocado on your toast, avocados grew on trees in the back yard and were basically free. If you were so very poor as to end up in this situation, you would at least try to hide it.
In Cuba, where avocado was seen as a substitute for butter, it was automatically seen as inferior. But when it appeared in 2010s America in the context of a totally new dish, it was wildly popular. And in terms of food replacement, avocado is a stealth vegan smash hit, way more successful than nearly any other plant-based product. It wasn’t framed that way, but in a practical sense, what did avocado displace? Mostly dairy- and egg-based spreads like butter, cream cheese, and mayonnaise. There may be no other food that has led to such an intense increase in the effective amount of veganism, even if the people switching away from these spreads didn’t see it that way. They just wanted avocado on the merits.
This product space is usually thought of as “alternative proteins”. Which is fine, protein is one thing that everyone needs. But a better perspective might be, “vegan ways to get where you’re going”. And just because some of these targets happen to be bundled together in old-fashioned flesh-and-blood meat, doesn’t mean they need to be bundled together in the same ways in the foods of the future.







{kind=link}