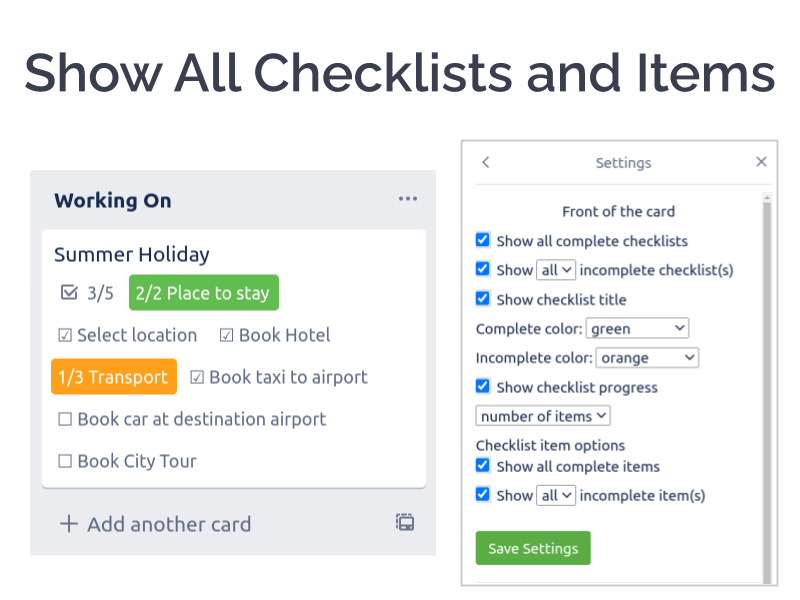
Scientific research today relies on one main protocol — experiments with control groups and random assignment. In medical contexts, these are usually called randomized controlled trials, or RCTs.
The RCT is a powerful invention for detecting population-level differences across treatments or conditions. If there’s a treatment and you want to know if it’s more effective than control or placebo, if you want to get an answer that’s totally dead to rights, the RCT is hard to beat. But there are some problems with RCTs that tend to get swept under the rug.
Today we aim to unsweep.
First, RCTs are seen as essential to science, but in fact they are historically unusual. RCTs were first invented in 1948, so most of science happened before they were even around. Galileo didn’t use RCTs, neither did Hooke, Lavoisier, Darwin, Kelvin, Maxwell, or Einstein. Newton didn’t use RCTs to come up with calculus or his laws of motion. He used observations and a mathematical model. So the idea that RCTs and other experiments are essential to science is ahistorical and totally wrong.
If you were to ask doctors what findings they are most sure of, they would almost certainly include “smoking causes cancer” in their list. But we didn’t discover this connection by randomly assigning some people to smoke a pack a day and other people to abstain, over the course of several years. No. We used epidemiologic evidence to infer a causal relationship between the presumed cause and observed effect.
Second, the RCT is only one tool, and like all tools, it has specific limitations. It’s great for studying population-level differences, or treatments where everyone has a similar response. But where there is substantial heterogeneity of treatment, the RCT is a poor tool and often gives incoherent answers. And if heterogeneity is the main question of interest, it’s borderline useless.
Put simply, if people respond to a treatment in very different ways, an RCT will give results that are confusing instead of clarifying. If some people have a strong positive response to treatment and some people have no response at all, the RCT will distill this into the conclusion that there is a mild positive response to treatment, even if no individual participant has a mild positive response!
Also, RCTs are like, way inefficient. To test for a moderate effect size, you need several dozen or several hundred participants, and you can test only one hypothesis at a time. Each time you compare condition A to condition B, you find out which group does better. Maybe you want to see if a dose of 2 mg is better than a dose of 4 mg. But if there are a dozen factors that might make a difference, you need a dozen studies. If you want to test two hypotheses, you need two groups several dozen or several hundred participants, for three you will need at least three groups, et cetera.
Third, RCTs don’t take advantage of modern cheap computation and search algorithms. For example, in the 1980s there was some interest in N=1 experiments for patients with rare cancers. This was difficult in the 1980s because of limited access to computers, even at research universities. But today you could run the same program on your cell phone a hundred times over. We’d be better off making use of these new insights and capabilities.
Recent Developments
Statistics is young, barely two hundred years at the outside. And the most familiar parts are some of the youngest. Correlation was invented in the 1880s and refined in the 1890s. It’s not even as old as trains.

Turns out it is kinda easy to make new tools. The RCT is important, but it isn’t rocket science. A new century requires new scientific protocols. The 21st century is an era where communication is prolific and computation is cheap, and we should harness this power.
Since the early days, science has been based on doing experiments and sharing results. Researchers collect data, develop theories, and discuss them with other likeminded weirdos, freaks, and nerds.
New technology has made it easier to do experiments and share results. And by “new technology”, we of course mean the internet. Just imagine trying to share results without email, make your data and materials public without the OSF or Google Drive or Dropbox, or collaborate on a manuscript by mailing a stack of papers across the country. Seriously, we used to live like that. Everyone did.
People do like the internet, and we also hear that they sometimes use it. Presumably a sensible, moderate amount. But just like the printing press, which was invented in 1440 but didn’t lead to the Protestant Reformation until 1517, the internet (and related tech like the computer and pocket computer, or “call phone”) has not yet been fully leveraged.
Let’s Put on our Thinking Caps
This is all easy enough to say, but at some point you need to consider how to come up with totally new research methods.
We take three main angles, which are historical, analogical, and tinkering. Basically: Look at how people came up with new methods in the past. Look at successful ideas from other fields and try applying them to science. And look at the different ideas and see what happens when you expose them to nature.
We begin with close reads and analysis of the successful development of past protocols (for example, the scientific innovation around the cure for scurvy).
We develop new scientific protocols by analogy to successful protocols in other areas. For example, self-experiments are somewhat like debugging (programmers in the audience will be familiar with suspicion towards stories of “well, it worked on MY setup”). The riff trial was developed in analogy to evolution.
Finally, we deploy simple versions of these protocols as quickly as possible so that we can tinker with them and benefit from the imagination of nature. This is also somewhat by analogy to hacker development methods, and startup concepts like the minimum viable product. We try out new ideas as soon as they are ready, and all of our work is published for free online, so other people can see our ideas and tinker with them too.
Here are some protocols we’ve been dreaming about that show exceptional promise:

N=1
The idea of N = 1 experiments / self-experiments has been around for a while, and there are some famous case studies like Nobel Laureate Barry Marshall’s self-administration of H. Pylori to demonstrate its role in stomach ulcers and stomach cancer. But N = 1 protocols have yet to reach their full potential.
There’s a lot of room to improve this method, especially for individuals with chronic illnesses/conditions that bamboozle the doctors. N = 1 studies have particular considerations, like hidden variables. You can’t just slap on a traditional design, you need to think about things like latency and half-life. And many of the lessons of N = 1 generalize to N of small.
Community Trial
The Community Trial is a protocol that blurs the line between participant and researcher. In these trials, an organizer makes a post providing guidelines and a template for people to share their data. Participants then collect their own data and send it to the organizer, who compiles and analyzes the results, sharing the anonymized data in a public repository.
Data collection is self-driven, so unlike a traditional RCT, participants can choose to measure additional variables, participate in the study for longer than requested, and generally take an active role in the study design.
Unlike most RCTs, community trials allow for rolling signups, and could be developed into a new class of studies that run continuously, with permanently open signups and an ever-growing database of results with a public dashboard for analysis.
We first tested this with the Potato Diet Community Trial (announcement, results), where 209 people enrolled in a study of an all-potato diet, and the 64 people who completed 4 weeks lost an average of 10.6 lbs. Not bad.
Reddit Trials
There’s a possible extension of the community trial that you might call a “Reddit Trial”.
In this protocol, participants in an online community (like a subreddit) that all share a common interest, problem, or question (like a mystery chronic illness) come together and invent hypotheses, design studies, collect data, perform analysis, and share their results. As in a community trial, participants can take an active role in the research, measure additional variables, formulate new hypotheses as they go, etc.
People seem to think that a central authority makes things better, but we think for design and discovery that’s mostly wrong. You want the chaos of the marketplace, not the rigid stones of the cathedral. Every bug is shallow if one of your readers is an entomologist.
This could be more like a community trial, where one person, maybe even a person from outside the community, takes the lead. But it could also be very different from a community trial, if the design and leadership is heavily or enormously distributed. There’s no reason that rival factions within a community, splintering over design and analysis, might not actually make this process better.
We already wrote a bit about similar ideas in Job Posting: Reddit Research Czar. And none other than Patrick Collison has come to a closely-related conclusion in a very long tweet, saying:
Observing some people close to me with chronic health conditions, it’s striking how useful Reddit frequently ends up being. I think a core reason is because trials aren’t run for a lot of things, and Reddit provides a kind of emergent intelligence that sits between that which any single physician can marshal and the full rigor of clinical trials.
… Reddit — in a pretty unstructured way — makes a limited kind of “compounding knowledge” possible. Best practices can be noticed and can imperfectly start to accumulate. For people with chronic health problems, this is a big deal, and I’ve heard lots of stories between “I found something that made my condition much more manageable” all the way to “I found a permanent cure in a weird comment buried deep in a thread”.
… Seeing this paper and the Reddit experience makes me wonder whether the approach could somehow be scaled: is there a kind of observational, self-reported clinical trial that could sit between Reddit and these manual approaches? Should there be a platform that covers all major chronic conditions, administers ongoing surveys, and tracks longitudinal outcomes?
We think the answer is: obviously yes. It’s just up to people to start running these studies and learning from experience. We’re also reminded of Recommendations vs. Guidelines from old Slate Star Codex.
Riff Trials
The Riff Trial takes a treatment or intervention which is already somewhat successful and recruits participants to self-assign to close variations on the original treatment. Each variation is then tested, and the results reported back to the organizers.
This uses the power of parallel search to quickly test possible boundary conditions, and discover variations that might improve upon the original. Since each variation is different, and future signups can make use of successful results, this can generate improvements based on the power of evolution.
We tested this protocol for the first time in the SMTM Potato Diet Riff Trial, with four rounds of results reported (Round 1, Round 2, Round 3, Retrospective).
This has already led to at least one discovery. While we originally thought that consuming dairy would stop the potato diet’s weight loss effects, multiple riff trials demonstrated that people keep losing weight just fine when they have milk, butter, even sour cream with their potatoes. Consuming dairy does not seem to be a boundary condition of the potato diet, as was originally suspected. This also seems to disprove the idea that the standard potato diet works because it is a mono-diet, boring, or low-fat. How can it work from being a mono-diet, boring, or low-fat if it still works when you add various dairy products, delicious dairy products, and high-fat dairy products?

There are hints of other discoveries in this riff trial too, like the fact that the diet kept working for one guy even when he added skittles. But that’s still to be seen.
“Bullet-Biting”
In most studies, people have a problem and want the effect to work. If it’s a weight loss study, they want to lose weight, and don’t want the weight loss to stop. So participants are hesitant to “bite the bullet” and try variations that might stop the effect.
This creates a strong bias against testing which parts of the intervention are actually doing the work, which elements are genuinely necessary or sufficient. It makes it much harder to identify the intervention’s real boundary conditions. So while you may end up with an intervention that works, you will have very little idea of why it works, and you won’t know if there’s a simpler version of the intervention that would work just as well; or maybe better.
We find this concerning, so we have been thinking about a new protocol where testing these boundaries is the centerpiece of the approach. For now we call it a “bullet-biting trial”, in the sense that it guides researchers and participants to bite the bullet (“decide to do something difficult or unpleasant in order to proceed”) of trying things that might kill the effect.
In this protocol, participants first test an intervention over a baseline period, to confirm that the standard intervention works for them.
Then, they are randomized into conditions, each condition being a variation that tests a theoretical or suspected boundary condition for the effect (e.g. “The intervention works, but it wouldn’t work if we did X/didn’t do Y.”).
For example, people might suspect that the potato diet works because it is low fat, low sugar, or low seed oils. In this protocol, participants would first do two weeks of a standard potato diet, to confirm that they are potato diet responders. No reason to study the effect in people who don’t respond! Then, anyone who lost some minimum amount of weight over the baseline period would be randomized into a high-fat, high-sugar, or high-seed-oil variant of the potato diet for at least two weeks more. If any of these really are boundary conditions, and stop the weight loss dead, well, we’d soon find out.
By randomly introducing potential blockers, you can learn more about how robust an intervention truly is. Maybe the intervention you’ve been treating so preciously actually works just fine when you’re very lax about it! More importantly, you can test theories of why the intervention works, since different theories will usually make strong predictions about conditions under which an intervention will stop working. And this design might help us better understand differences between individuals — it may reveal that certain variations are a boundary condition for some people, but not for others.