
[PROLOGUE – EVERYBODY WANTS A ROCK]
[PART I – THERMOSTAT]
[PART II – MOTIVATION]
[PART III – PERSONALITY AND INDIVIDUAL DIFFERENCES]
Reward and punishment is the lowest form of education.
— Zhuangzi
What is the value of a glass of water? Well, it has great value if you’re in the middle of the desert, but not much value at all on the shores of Lake Champlain.
What’s the value of the action, “put on a heavy down coat”? It has positive value if you find yourself in Saskatchewan on January 3rd, but negative value in the Arizona summer.
And what’s the value of taking an outdoor shower in cool water? This one has negative value in Saskatchewan and positive value in Phoenix.
Building a mind around notions of “value” quickly leads you into contradictions.
Let’s say we have a mouse in a cage. We’ve designed the cage to vary wildly in temperature, so by default, the mouse is uncomfortable.
But we’re not monsters. We’ve given the mouse some control over the temperature: two levers, a red one that raises the temperature a bit, and a blue one that lowers it. If the mouse can learn to operate this system, it will be able to maintain a reasonable temperature with little trouble.

How would a mouse do on this task, if God saw fit to grace it with a brain that runs on reward and punishment?
Well, let’s say that first the temperature got too high. The mouse tries the red lever. This makes things even hotter. Clearly the red lever is a punishment! The mouse assigns the red lever a value like [-1] or something. Next the mouse tries the blue lever. This makes the cage less hot. A reward! The blue lever gets a value like [+1].
Because it is rewarding, the mouse presses the blue lever until the cage is a comfortable temperature. Then what happens? That’s right, the mouse keeps pressing the lever! After all, the mouse is trying to seek rewards and avoid punishments, and the blue lever has always been rewarding in the past.
Soon the cage is too cold. Pressing the blue lever becomes a punishment [-1], since it only makes things colder. The mouse slowly updates the value of the blue lever until it reaches [0], at which point it stops pressing the lever.
Then what happens? Well, it doesn’t press the blue lever, because it has an expected value of [0]. And it doesn’t press the red lever either! After all, the red lever still has an expected value of [-1]. In all past experience, pressing the red lever always makes things “worse”.
This system of reward and punishment has left the mouse entirely confused. Its conclusion is that the blue lever has no value, and that the red lever is always a negative experience.
You can try to solve this with awkward kludges, but most of them don’t work. For example, you might have it so that the mouse learns separate values for the levers in separate environments, the idea being that it will learn that the blue lever is rewarding when it’s too warm, and punishing when it’s too cold. But then the mouse will have to learn thousands of different values for each action in thousands of different environments — a separate value for the blue lever when it is sunny, overcast, breezy, when the mouse is bored, when the lab techs are talking too loud, etc.
Worse, the mouse will have no ability to generalize. If it learns that the blue lever is “punishing” when the cage is cold, it won’t be able to apply this knowledge outside that immediate situation. It will not learn to press the blue lever when the cage is too hot, because it has reduced the experience to an abstract number.
Much easier for the mouse to learn what the blue lever does: it lowers the temperature of the cage, which the mouse experiences as a decline in body temperature.
Is this a reward or a punishment? Neither. What is the value of this action? It has none. Value is absurd. Pushing the blue lever has specific rather than general consequences. It is simply a thing the mouse can do, and the mouse learns how the things it can do affect the things that interest it.
The mouse is naturally endowed with systems interested in its body temperature: at least two governors, one dedicated to keeping it from being too hot, the other keeping it from being too cold. The governors pay attention to things that might knock the mouse’s body temperature away from its set points, and actions that can set the body temperature right again. So the governors are very interested in these levers, and quickly learn their uses.
Both the (keep-mouse-from-getting-too) cold governor and the (keep-mouse-from-getting-too) hot governor track the mouse’s body temperature, though they defend different set points. When the mouse pulls the blue lever, there is a change in the mouse’s body temperature. Since both governors control that variable, both of them learn that the action of pulling the blue lever reduces the mouse’s body temperature. When the mouse pulls the red lever, both governors learn that the action of pulling the red lever increases the mouse’s body temperature.
The governors gain the same information, but they use it in different ways. The cold governor knows to vote for pulling the red lever when the mouse is below its target temperature, and to vote against pulling the blue lever when that would drive the mouse below its target temperature. This is implicit in its design. The hot governor knows to vote for pulling the blue lever when the mouse is above its target temperature, and to vote against pulling the red lever when that would drive the mouse above its target temperature.
From this analysis, we think that the mind doesn’t represent “value” at all (compare: The case against economic values in the orbitofrontal cortex (or anywhere else in the brain)). Instead, governors track how actions affect their error signals.
Each governor learns on its own, and keeps some kind of record of what actions increase or decrease the variables it cares about, and by how much. This is itself a complicated process, and we don’t mean to discount it. But governors clearly learn how actions change the world, not whether or not they are “valuable”. There is no reward and no punishment.
Some experiences are consistently “punishing”, like getting hit in the face by a 2×4. But this is incidental, it’s only because the pain governor has strong opinions about damage to the face — the opinion that this value should always be kept very close to zero. So the pain governor will always oppose such hardware-related incidents.
And in fact, even this is not always punishing. If you are born without a pain governor, or your pain governor is temporarily turned off (by drugs, for example), then getting hit in the face by a 2×4 is no longer “punishing”. More like a gentle romp.
And there is nothing at all that is always “rewarding”. Your first donut after a long day at work will be rewarding, but by the 10th donut you will start to find donuts “punishing”. By the 100th donut, anyone would find additional donuts excruciating (ok, almost anyone).
Even with that said, there are still a lot of open questions. It may be, for example, that governors learn more quickly when an action actually corrects their error, compared to when they observe it in a neutral situation.
Imagine it’s 20 °F outside and you go and stand near a campfire. Up to that point you were pretty cold, so your cold governor had a pretty big error. When you walk over to the campfire, your cold governor will be very interested — it will notice that standing near a campfire is a good way to warm up.
But what will your hot governor learn? Hopefully it will learn something. After all, standing near a campfire affects the variable it cares about, body temperature. It would be good for the hot governor to remember this, so it can avoid standing near campfires in the future when it’s hot out. But in this moment, the hot governor’s error is zero. So it’s possible that the hot governor doesn’t learn such a strong lesson about the effect of campfires as the cold governor did.
If some day it is 98 °F outside, and there’s a campfire, will the hot governor remember what it learned? At 98 °F, you are too hot, the hot governor has an error. Will it remember that standing near the campfire will increase your body temperature, and so will increase its error? Or will it have to learn that lesson all over again, because last time you encountered a campfire, it was sleeping, because it had no error.
Similarly, we don’t know if a governor will learn more when its error is bigger. But it seems plausible. If it is 78 °F and you go stand near a campfire, that will increase your hot governor’s error from small to medium, and it will remember that. But if it is 98 °F and you go stand near a campfire, that will increase your hot governor’s error from large to extra large! It seems possible that the hot governor will remember that even more, that increasing an error will be remembered more seriously when the error is already somewhat large.
The Part of the Book with Some Math
We probably won’t have to invent the exact rules that run inside a mouse’s head when it’s learning to manage all those levers. Our guess is that many of these algorithms have already been discovered, in past research on reinforcement learning.
A complete recap of reinforcement learning is beyond the scope of this book, but we can give you a rough sense, and suggest the few tweaks it might need to fit into our new paradigm.
There are many kinds of reinforcement learning algorithms, but the difference between them isn’t our current focus. For today we’ll use Q-learning as our example, a model-free algorithm that uses this update function:
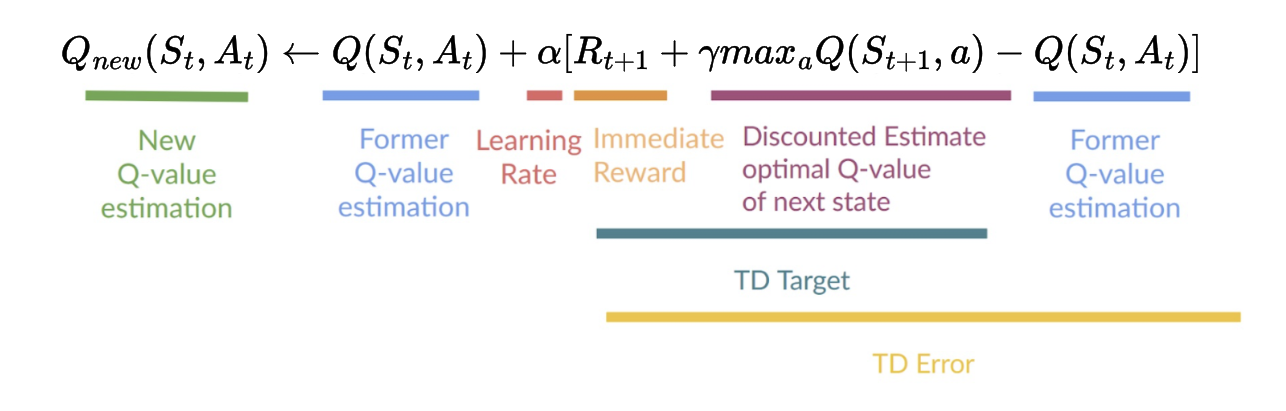
Q-learning works by keeping track of the value of different actions A the agent can take in states S. The function Q(S, A) gives us the value of taking action A in state S.
This update function describes how the value representation of Q(S, A), the current estimate of the value of choosing action A in state S, changes in the light of new evidence.
The core of the equation is very simple. The new Q(S, A) is equal to the old Q(S, A) plus some change (for now ERROR) times a learning rate:
Q_new(S, A) = Q(S, A) + α [ERROR]
The learning rate α is a parameter between 0 and 1 that controls how much the Q-value is updated in each step. If the learning rate is higher, then more weight is given to new information and the mouse learns faster. But it might learn too much from the most recent example, and ignore past experience. If the learning rate is lower, then less weight is given to new information, the mouse learns slower, and updates are more conservative.
Hopefully that makes sense so far. You update the new value based on the old value, adjusting it by some amount, tuned by a parameter that controls whether the update is fast or slow. But what about this error? Let’s break it down.
R_t+1 is the immediate value the animal just experienced after taking action A in state S.
Next we see γ, which is the discount function. This is another parameter between 0 and 1, and this one controls how much future rewards are valued compared to immediate rewards. If γ is close to 1, the agent considers long-term rewards heavily; if close to 0, it focuses mainly on immediate rewards.
The next term, max_aQ(S_t+1,a), is a little trickier but not actually that bad. This looks ahead to the next step (t+1, where t stands for time), so the state we’ll be in next. Then it estimates the maximum value of the possible actions available at that state S_t+1. So this represents the agent’s best estimate of the value of future actions from the next state onward. This is important because if an action puts us in situations that lead to future rewards, we should learn that action is rewarding even if it doesn’t lead to a reward directly; it sets us up for success, which is nearly as good.
Finally, this is subtracted from the current estimate, Q(S, A), because what we want here is to know how far off is the current reward plus expected future rewards from the existing estimate of the value of this action.
Let’s take a few perverse examples that will make this equation transparent. To keep things simple, we’ll assume that the discount function is exactly 1.
Let’s start by considering a situation where we have already learned the correct value. The expected value of action A is 10, and we’ll see that that is perfectly correct. When we take action A in state S, we get a reward of 8, and that puts us in a new state S_t+1 with a maximum expected value of 2. This was all anticipated, so the existing value of Q(S, A) is 10:
NEW = 10 + α(8 + 2 – 10)
This gives:
NEW = 10 + α(0)
So we see that the weight of α doesn’t matter, because the error was zero, and anything multiplied by zero is zero. The organism was entirely correct in its expectations, so there will be no update at all. The reward from this action in this state (including anticipated future rewards) was 10, the old estimate was 10. The new value will be 10, the same as the old value.
But let’s say the estimate is off, and the mouse expected a value of 7 from the action A in state S. Then the function is:
NEW = 7 + α(8 + 2 – 7)
Now the learning rate matters. If the learning rate is 1, then the new estimate of this action in this state will be changed to the exact value of the most recent experience:
NEW = 7 + 1(8 + 2 – 7)
10 = 7 + 1(3)
But this is probably a mistake. It erases all the past experience. Maybe this was an unusually good time in state S to take action A, and we shouldn’t take this good outcome as representative. So instead we can use a more modest learning rate like 0.2:
NEW = 7 + 0.2(8 + 2 – 7)
7.6 = 7 + 0.2(3)
The only change by adding back in the discount rate is that the mouse doesn’t count the full value of the best possible future rewards. They’re only possible — a cheese in the hand and all that. Here’s the same situation with a discount rate of 0.9:
NEW = 7 + 0.2(8 + 0.9(2) – 7)
NEW = 7 + 0.2(8 + 1.8 – 7)
7.56 = 7 + 0.2(2.8)
In summary, Q-learning works by adjusting the Q-value of each action based on immediate rewards and estimated future rewards, gradually refining an estimate for the likely value of each action in each state.
It takes only a simple tweak to adapt this style of algorithm for cybernetics.
Reinforcement learning assumes that each agent has a single value function that it tries to maximize, and that all kinds of value are the same. In this perspective, 2 points from hot chocolate is the same as 2 points worth of high fives.
The cybernetic paradigm rejects that — abstract “rewards” don’t exist. Instead, governors track specific changes. So in this case, an algorithm like Q-learning is running inside each of the governors. The keep-mouse-from-getting-too cold governor is keeping track of what different actions in different states do to its error signal. The keep-mouse-from-getting-too hot governor is keeping track of what different actions in different states do to its error signal.
Each of the governors has its own ledger of the effect of different possible actions, and is keeping track of how each of these actions influences the signal(s) it cares about. Then all the governors get together and vote for their favorite action(s).
Recap
- Building a mind around notions of “value” quickly leads you into contradictions.
- Value is absurd. Behaviors have specific rather than general consequences.
- We think the mind doesn’t represent “value” at all. Instead, governors track how actions affect their error signals. Governors clearly learn how actions change the world, not whether or not they are “valuable”. There is no reward and no punishment.
[Next: DEPRESSION]
