“Alright, gang, let’s split up and search for clues.”
— Fred Jones, Scooby-Doo
This has been our proposal for a new paradigm for psychology.
If the proposal is more or less right, then this is the start of a scientific revolution. And while we can’t make any guarantees, it’s always good to plan for success. So in case these ideas do turn out successful, then: welcome to psychology’s first paradigm, let’s discuss what we do from here.
In looking for a paradigm, we’re looking for new ways to describe the mysteries that pop up on the regular. When a good description arrives, some of those mysteries will become puzzles, problems that look like they can be solved with the tools at hand, that look like they will have a clear solution, the kind of solution we’ll recognize when we see it. Because a shared paradigm gives us a shared commitment to the same rules, standards, and assumptions, it can let us move very quickly.
All that is to say is that if this paradigm has any promise, then there should be a lot of normal science, a lot of puzzle-solving to do. A new paradigm is like an empty expert-level sudoku: there’s a kind of internal logic, but also a lot of tricky blanks that need filling in. So, we need your help. Here are some things you can do.
Experimentation
First, experimentalists can help us develop methods for figuring out how many cybernetic drives people have, what each drive controls, and different parameters of how they work. In the last twosections we did our best to speculate about what these methods might look like, but there are probably a lot of good ideas we missed.
Then, we need people to actually go out and use these methods. The first task is probably to discover all of the different drives that exist in human psychology, to fill out the “periodic table” of motivation as completely as we can. Finding all of the different drives will generate many new mysteries, which will lead to more lines of research and more discoveries.
We will also want to study other animals. There are a few reasons to study animals in addition to humans. First of all, most animals don’t have the complex social drives that humans do. The less social an animal is, the easier it will be to study its non-social drives in isolation. Second, it’s possible to have more control over an animal’s environment. We can raise an animal so that it never encounters certain things, or only encounters some things together. Finally, we can use somewhat more invasive techniques with animals than we can with humans.
Some animals have the bad emotions.
Computational Modeling
Computational models will be especially important for developing a better understanding of depression, anxiety, and other mental illnesses. With a model, we can test different changes to the design and parameters, and see which kinds of models and what parameter values lead to the behaviors and tendencies that we recognize as depression. This will ultimately help us determine how many different types of depression there are, come to an understanding of their etiology, and in time develop interventions and treatments.
Computational models should provide similar insight into tendencies like addiction and self-harm. The first step is to show that models of this kind can give rise to behavior that looks like addiction. Then, we see what other predictions the model makes about addictive behavior, and about behavior in general, and we test those predictions with studies and experiments.
If we discover more than one computational model that leads to addictive behavior, we can compare the different models to real-world cases of addiction, and see which is more accurate. Once we have models that provide a reasonably good fit, we can use them to develop new approaches for treatment and prevention.
Biology and Chemistry
Those of you who tend more towards biology or neuroscience can help figure out exactly how these concepts are implemented in our biology. Understanding the computational side of how the mind works is important, but the possible interventions we can take (like treating depression) will be limited if we don’t know how each part of the computation is carried out in an organism.
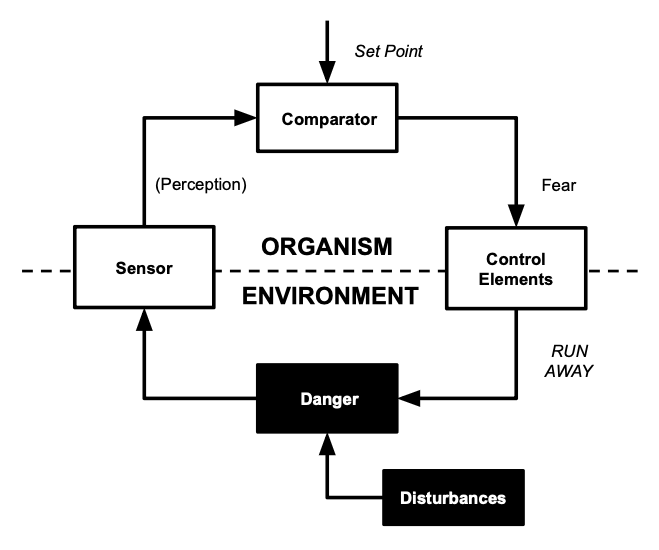
For example: every governor tracks and controls some kind of signal. The fear governor tracks something like “danger”. This is a complicated neurological construct that probably doesn’t correspond to some specific part of biology. But other governors probably track biological signals that may be even as simple as the concentrations of specific minerals or hormones in the bloodstream.
For example, the hormone leptin seems to be involved in regulating hunger. Does one of the hunger governors act to control leptin levels in our blood? Or is leptin involved in some other part of the hunger-control process? What do the hunger, thirst, sleep, and other basic governors control, and what are their set points?
Biologists may be able to answer some of these questions. Some of these questions may even have already been answered in neuroscience, biology, or medicine, in which case the work will be in bundling them together under this new perspective.
Design
Running studies and inventing better methods sounds very scientific and important, but we suspect the most important contributions might actually come from graphic design.
The first “affinity table” was developed in 1718 by Étienne François Geoffroy. Substances are identified by their alchemical symbol and grouped by “affinity”.
At the head of each column is a substance, and below it are listed all the substances that are known to combine with it. “The idea that some substances could unite more easily than others was not new,” reports French Wikipedia, “but the credit for bringing together all the available information into a large general table, later called the affinity table, goes to Geoffroy.”
Here is a later affinity table with one additional column, the Tabula Affinitatum, commissioned around 1766 for the apothecary’s shop of the Grand Duke of Florence, now to be found in the Museo Galileo:
These old attempts at classification are charming, and it’s tempting to blame this on the fact that they didn’t understand that elements fall into some fairly distinct categories. But chemical tables remained lacking even after the discovery of the periodic law.
Russian chemist Dmitri Mendeleev is often credited with inventing the periodic table, but he did not immediately give us the periodic table as we know it today. His original 1869 table looked like this:
And his update in 1871 still looked like this:
It wasn’t until 1905 that we got something resembling the modern form, the first 32-column table developed by Alfred Werner:
They tried a lot of crazy things on the way to the periodic table we know and love, and not all of these ideas made it. We’ll share just one example here, Otto Theodor Benfey’s spiral periodic table from 1964:
When a new paradigm arrives, the first tools for thinking about it, whether tables, charts, diagrams, metaphors, or anything else, are not going to be very good. Instead we start with something that is both a little confused and a little confusing, but that half-works, and iterate from there.
The first affinity table by Étienne François Geoffroy in 1718 was not very good. It was missing dozens of elements. It contained bizarre entries like “absorbent earth” and “oily principle”. And it was a simple list of reactions, with no underlying theory to speak of.
But it was still good enough for Fourcroy, a later chemist, to write:
No discovery is more brilliant in this era of great works and continued research, none has done more honor to this century of renewed and perfected chemistry, none finally has led to more important results than that which is relative to the determination of affinities between bodies, and to the exposition of the degrees of this force between different natural substances. It is to Geoffroy the elder … that we owe this beautiful idea of the table of chemical ratios or affinities. … We must see in this incorrect and inexact work only an ingenious outline of one of the most beautiful and most useful discoveries which have been made. This luminous idea served as a torch to guide the steps of chemists, and it produced a large number of useful works. … chemists have constantly added to this first work; they have corrected the errors, repaired the omissions, and completed the gaps.
It took about two hundred years, and the efforts of many thousands of chemists, to get us from Geoffroy’s first affinity table to the periodic table we use today. So we should not worry if our first efforts are incomplete, or a little rough around the edges. We should expect this to take some effort, we should be patient.
Better tools do not happen by accident. We do not get them for free — someone has to make them. And if you want, that someone can be you.
That’s all, folks!
Thank you for reading to the end of the series! We hope you enjoyed.
We need your help, your questions, your disagreement. Consider reaching out to discuss collaborating, or to just toss around ideas, especially if they’re ideas that could lead to empirical tests. You can contact us by email or join the constant fray of public discussion on twitter.
If you find these ideas promising and want to see more of this research happen, consider donating. Our research is funded through Whylome, a a 501(c)(3) nonprofit that relies on independent donations for support. Donations will go towards further theoretical, modeling, and empirical work.
The researchers recruited fourteen men (mean age: 28 years old) and invited them back to the lab to eat “a homogenous mixed-macronutrient meal (pizza)”. The authors note that “this study was open to males and females but no females signed up.”
They invited each man to visit the lab two separate times. On one occasion, the man was asked to eat pizza until “comfortably full”. The other time, he was asked to eat pizza until he “could not eat another bite”.
When asked to eat until “comfortably full”, the men ate an average of about 1500 calories of pizza. But when asked to eat until they “could not eat another bite”, the men ate an average of more than 3000 calories.
Study Materials
The authors view this as a study about nutrition, but we saw it and immediately went, “Aha! Pizza psychology!”
While this isn’t a lot of data — only fourteen men, and they only tried the challenges one time each — it shows some promise as a first step towards a personality measure of hunger and satiety, because it measures both how hungry these boys are, and also how much they can eat before they have to stop.
When asked to aim for “could not eat another bite”, the men could on average eat about twice as much pizza compared to when they were asked to aim for “comfortably full”. But there was quite a lot of variation in this ratio for different men:
All the men ate more when they were asked to eat as much as they could, than when they were asked to eat as much as they liked. But there’s a lot of diversity in the ratio between those two values. When instructed to eat until they “could not eat another bite”, some men ate only a little bit more than they ate ad libitum. But one man ate almost three times as much when he was told to go as hard as he can.
People have some emotions that drive them to eat (collectively known as hunger), and other emotions that drive them to stop eating (collectively known as satiety). While these pizza measurements are very rough, they suggest something about the relationship between these two sets of drives in these men. If nothing else, it’s reassuring to see that for each individual, the “could not eat another bite” number is always higher.
It’s a little early to start using this as a personality measure, but with a little legwork to make it reliable, we might find something interesting. It could be the case, for example, that there are some men with very little daylight between “comfortably full” and “could not eat another bite”, and other men for whom these two occasions are like day and night. That would suggest that some men’s hunger governor(s) are quite strong compared to their satiety governor(s), and other men’s are relatively weak.
The general principle of personality in cybernetic psychology is “some drives are stronger than others”. So for personality, we want to invent methods that can get at the question of how strong different drives are, and how they stack up against each other. Get in loser, we’re making a tier list of the emotions.
We may not be able to look at a drive and say exactly how strong it is, since we don’t yet know how to measure the strength of a drive. We don’t even know the units. When this is eventually discovered, it will probably come from an unexpected place, like how John Dalton’s work in meteorology gave him the idea for the atomic theory.
But we can still get a decent sense of how strong one drive is compared to another drive. This is possible whenever we can take two drives and make them fight.
Personality psychology be like
Some drives are naturally in opposition — this pizza study is a good example. The satiety governor(s) exist specifically to check the hunger governor(s). Hunger was invented to start eating, and satiety was invented to make it stop. So it’s easy to set up a situation where the two of them are in conflict.
Or somewhat easy. We think it’s more accurate to model the pizza study as the interaction between three (groups of) emotions. When asked to eat until “comfortably full”, the hunger governor voted for “eat pizza” until its error was close to zero, then it stopped voting for “eat pizza”, so the man stopped. That condition was simple and mainly involved just the one governor.
The other condition was more complex. When asked to eat until they “could not eat another bite”, the hunger governor first voted for “eat pizza” until its error was close to zero. Then, some kind of “please the researchers” governor(s) kept voting for “eat pizza” to please the researchers.
At some point this started running up against the satiety governor. The satiety governor tracks something like how full you are, so as the man started to get too full, the satiety governor started voting against “eat pizza”. The man kept eating until the vote from the “please the researchers” governor(s) was just as strong as the vote from the satiety governor, at which point the two votes cancel out and the man could not eat another bite.
This reveals the problem. In one sense, hunger and satiety are naturally in opposition. Hunger tries to make you eat enough and satiety tries to make sure you don’t eat enough too much. But in a healthy person, there’s plenty of daylight between the set points of these two drives, and they don’t come into conflict.
Same thing with hot and cold — the drive that tries to keep you warm is in some sense “in opposition” to the drive that tries to keep you from overheating, but they don’t normally fight. If you have a sane and normal mind, you don’t put on 20 sweaters, then overheat, then in a fit of revenge take off all of your clothes and jump in a snowbank, etc. These drives oppose each other along a single axis, but when they are working correctly, they keep the variable they care about in a range that they agree on. Hunger and satiety, and all the paired governors, are more often allies than enemies.
But any two drives can come into conflict when the things they want to do become mutually exclusive, or even just trade off against each other. Even if you can do everything you want, the drives will still need to argue about who gets to go first. Take something you want, anything at all, and put it next to a tiger. Congratulations, fear is now in conflict with that original desire.
Many people experience this conflict almost every morning:
This is actually a more complicated situation, where the governors have formed factions. The pee governor wants to let loose on your bladder. But your hygiene governor votes against wetting the bed. Together they settle on a compromise where you get up and pee in the toilet instead, since this satisfies both of their goals (bladder relief + hygienic).
But the governor that keeps you warm, the sleep governor (who wants to drift back into unconsciousness), and any other governors with an interest in being cozy, strenuously oppose this policy. They want you to stay in your warm, comfy bed. So you are at an impasse until the bladder governor eventually has such a strong error signal — you have to take a leak so bad — that it has the votes to overrule the cozy coalition and motivate you to get up and go to the bathroom.
The point is, the bladder governor, warmth governor, and sleep governor don’t fundamentally have anything to do with each other. They all care about very different things. But when you have to pee in the middle of the night, their interests happen to be opposed. They draw up into factions, and this leads to a power struggle — one so universal that there are memes about it. And as is always the case in politics, a power struggle is a good chance to get a sense of the relative strength of the factions involved.
If you met someone who said they didn’t relate to this — they always get up in the middle of the night to pee without any hesitation or inner struggle — this would suggest that their bladder governor is very strong, or that their warmth and/or sleep governors are unusually weak. Whatever the case, their bladder governor wins such disagreements so quickly that there doesn’t even appear to be a dispute.
In contrast, if your friend confesses that they have such a hard time getting up that they sometimes wet the bed, this suggests that their bladder governor, and probably their hygiene governor, are unusually weak compared to the governors voting for them to stay in bed.
To understand these methods, we have to understand the difference between two kinds of “strength”.
In general when we say that a drive is strong, we mean that it can meet its goals, it can vote for the actions it wants. This is why we can learn something about the relative strength of two drives by letting them fight — we can present the organism with mutually exclusive options (truth or dare?) and see which option it picks. If we have some reasonable idea which drive would pick which option, we know which drive is stronger from which option is picked.
However! Another way a drive can be strong is that it can have a big error signal in that moment. If you are ravenously hungry, you will eat before anything else. If you are in excruciating pain, you will pull your hand off the stove before doing anything else. This kind of urgency tells us that the current error is big, but it doesn’t tell us much about the governor.
A drive does get a stronger vote when its variable is further off target. But it’s also true that for a given person, some drives seem stronger in all situations.
The normal sense of strength gets at the fact that a governor can be stronger or weaker for a given error. Some people can go to sleep hungry without any problem. For other people, even the slightest hint of appetite will keep them awake. When we talk about someone being aggressive, we mean that they will drop other concerns if they see a chance to dominate someone; if we talk about someone being meek, we mean the opposite.
The current strength of any drive is a function of the size of its current error signal and the overall strength or “weight” of the governor. Unfortunately, we don’t know what that function is. Also, it might be a function of more than just those two things. Uh-oh!
Ideally, what we would do is hold the size of the error constant. If we could make sure that the error on the salt governor is 10 units, and the error on the sweet governor is 10 units, then we could figure out which governor is stronger by seeing which the person would choose first, skittles or olives. This is based on the assumption that the strength of the vote for each option is a combination of the size of the errors and the strength of the governor itself. Since in this hypothetical we know that the strength of the errors is exactly the same, the difference in choice should be entirely the result of the difference in the strength of the governors.
Unfortunately we don’t know how to do that either. We don’t know how to measure the errors directly, let alone how to hold the size of the errors constant.
But we can use techniques that should make the size of some error approximately constant, and base our research on that. The closer the approximation, the better.
The important insight here is that even when we can’t make measurements in absolute terms, we can often make ordinal comparisons. “How strong is this drive” is an impossible question to answer until we know more about how strength is implemented mechanically, but we can make very reasonable guesses about which of two drives is stronger, what order their strengths are in, i.e. ordinal measurements.
We can do this two ways: we can compare one of your drives to everyone else’s version of that same drive, or we can compare one of your drives to your other drives.
Compare One of Your Drives to Everyone Else’s Version of that Same Drive
The first is that we can compare one of a person’s drives to the same drive in other people.
It’s reasonable to ask if your hunger, fear, pain, or shame drive is stronger or weaker than average. To do this, we can look at two or more individuals and ask if the drive is stronger for one of them or for the other.
This will offer a personality measure like: your salt governor is stronger than 98% of people. You a salty boy.
Again, to get a measure of strength, we need to make everyone’s errors approximately constant. One way we can make errors approximately constant is by fully satisfying the drive. So if we identify a drive, like the drive for salt, we can exhaust the drive by letting people eat as much salt or salty food(s) as they want. Now all their errors should be close to zero. Then we can see how long it takes before they go eat something salty again. If someone goes to get salty foods sooner, then other things being equal, this is a sign that their salt governor is unusually strong.
This won’t be perfectly the same, and other things will not be perfectly equal. Some people’s salt error may increase more quickly than others’, like maybe they metabolize salt faster, or something. So after 5 hours without salty foods, some people’s error may be much bigger than others’. But it should be approximately equal, and certainly we would learn something important if we saw one guy who couldn’t go 10 minutes without eating something salty, and someone else who literally never seemed to seek it out.
When we say things like, “Johnnie is a very social person. If he has to spend even 30 minutes by himself he gets very lonely, so he’s always out and spending time with people. But Suzie will go weeks or even months without seeing anyone,” this is a casual version of the same reasoning, and we think it’s justified. It may not get exactly at the true nature of personality, but it’s a start.
When we figure out what the targets are for some governors, we’ll be able to do one better. For example, let’s imagine that we find out that thirst is the error for a governor that controls blood osmolality, and through careful experimentation, we find out that almost everyone’s target for blood osmolality is 280 mOsm/kg. Given the opportunity, behavior drives blood osmolality to 280 mOsm/kg and then stops.
If we measure people’s blood osmolality, we can dehydrate them to the point where their blood osmolality is precisely 275 mOsm/kg. We know that this will be an error of 5 mOsm/kg, because that’s 5 units less than the target. Then we would know almost exactly what their error is, and we could estimate the relative strength of their thirst governor by measuring how hard they fight to get a drink of water.
On that note, it’s possible that a better measure than time would be effort. For example, you could take a bunch of rats and figure out the ideal cage temperature for each of them. Separately, you teach them that pushing a lever will raise the temperature of their cage by a small amount each time they press it.
Then, you set the cage temperature 5 degrees colder than they prefer. This should give them all errors of similar magnitude — they are all about 5 degrees colder than they’d like. Then you give them the same lever they were trained on. But this time, it’s disconnected. You count how many times they press the lever before they give up. This will presumably give you a rough measure of how much each rat is bothered by being 5 degrees below target, and so presumably an estimate of the strength of that governor. If nothing else, you should observe some kind of individual difference.
Compare One of Your Drives to Your Other Drives
The second approach is to ask how your drives compare to each other, basically a ranking. We can look at a single person and ask, in this person, is drive A stronger than drive B?
The main way to do this is to give the person a forced choice between two options, one choice that satisfies governor A, and the other that satisfies governor B. This doesn’t have to be cruel — you can let them take both options, you just have to just make them choose which they want to do first.
This would offer a personality measure like: you are more driven by cleanliness than by loneliness, which is why you keep blowing off all your friends to stay in and scrub your toilet.
There are some drives that make us want to be comfortable and other drives that make us want to be fashionable; there are at least some tradeoffs between comfort and fashion; if you reflect on each of the people in your life, it’s likely that you already know which coalition of drives tends to be stronger in each person.
Every time you see someone skip work to play videogames, refuse to shower even when it ruins all their friendships, blow up their life to have an affair with the 23-year-old at the office, or stay up late memorizing digits of pi, you are making this kind of personality judgment implicitly. People have all kinds of different drives, and you can learn a lot about which ones are strongest by seeing which drives are totally neglected, and which drives lead people to blithely sacrifice all other concerns, as though they’re blind to the consequences.
The Bene Gesserit, a sect of eugenicist, utopian nuns from the Dune universe, use a simplified version of this method in their famous human awareness test, better known as the gom jabbar. Candidates are subjected to extreme pain and ordered not to pull away, at penalty of taking a poisoned needle in the neck. In his success, Paul demonstrates that some kind of self-control governor is much stronger than his pain governor, even when his pain error is turned way up.
“What’s in the box?” “A personality test.”
But no shade to the Bene Gesserit, this is not a very precise measure. By turning the pain governor’s error extremely high, they can show that a candidate has exceptional self-control. But this doesn’t let them see if self-control is in general stronger than pain, because the error gets so huge. To compare the strength of governors, you ideally want the error signals to be as similar as possible.
As before, the best way to get at strength is to take two drives, try to make their errors as similar as possible, and then see which drive gets priority. Other things being equal, that drive must be stronger.
When we were trying to compare personality between people, this was relatively easy. If nothing else, we were at least looking at the same error. We can’t get an exact measure of the error, but we could at least say, both of these people have gone 10 hours without eating, or 20 hours without sleep, or are ten degrees hotter than they find comfortable. These are the same kinds of things and they are equal for both people.
But to compare two governors within a single person, we are comparing two different errors, and we have no idea what the units are. So it may be hard to demonstrate differences between the strength of the governors when those differences are small. If one error is ten times stronger than the other, then we assume that the governor behind that error will win nearly all competitions between the two of them. If one error is 1.05 times stronger than the other, that governor has an edge, but will often get sidelined when there are other forces at play.
But like the common-sense examples above, it should be possible to make some comparisons, especially when differences are clear. For example, if we deprive a person of both sleep and food for 48 hours (with their consent of course), then offer them a forced choice between food and sleep, and they take the food, that suggests that their drive to eat may be stronger than their drive to sleep. This is especially true if we see that other people in the same situation take the option to sleep instead.
If we deprive the person of sleep for 48 hours and food for only 4 hours, and they still choose the food over sleep, that is even better evidence that their drive to eat is stronger than their drive to sleep, probably a lot stronger.
While these methods are designed to discover something inside an individual person, they might also shed some light on personality differences between people. For example, we might find that in most people, the sugar governor is stronger than the salt governor. But maybe for you, your salt governor is much stronger than your sugar governor. That tells us something about your personality in isolation (that one drive is stronger than another), and also tells us something about your personality compared to other people (you have an uncommon ordering of drives).
Return to Pizza Study
The pizza study is interesting because it kind of combines these techniques.
Each person was compared on two tasks — “comfortably full” and “could not eat another bite”, which gives us a very rough sense of how strong their hunger and satiety governors are. If you ate 10 slices to get to “comfortably full” and only 12 slices to get to “could not eat another bite”, your satiety governor is probably pretty strong, since it kicks in not long after you ate as much as you need. (There could be other interpretations, but you get the gist.)
In addition, each person can be compared to all the other people. Some men could eat only a little more when they were asked to get to “could not eat another bite”. But one man ate almost three times as much as his “comfortably full”. This man’s satiety governor is probably weaker than average. There are certainly other factors involved, but it still took a long time before that governor forced him to stop eating, suggesting it is weak.
A final note on strength. The strength of a governor is probably somewhat innate. But it may also be somewhat the result of experience. If someone is more motivated by safety than by other drives, some of that may be genetic, but some of that may be learned. It would not be ridiculous to think that your mind might be able to tune things so that if you have been very unsafe in your life, you will pay more attention to safety in the future.
Even the part that’s genetic (or otherwise innate) still has to be implemented in some specific way. When one of your governors is unusually strong, does that governor have a stronger connection to the selector? Does it have the same connection as usual, but it can shout louder? Does it shout as loud as normal, but it can shout twice as often? We don’t know the details yet, but keep in mind that all of this will be implemented in biology and will include all kinds of gritty details.
Deeper Questions
People can differ in more ways than just having some of their drives be stronger than others. For example, some people are more active than other people in general, more active for every kind of drive. They do more things every single day.
Some people seem to get more happiness from the same level of accomplishment. For some people, cooking dinner is a celebration. For others, routine is routine.
Some people seem more anxious by default. Even a small thing will make them nervous.
These seem like they might be other dimensions on which people can differ, and they don’t seem like they are linked to specific governors.
Studying the strength of the governors is nice because the governors are all built on basically the same blueprint, so the logic needed to puzzle out one of them should mostly work to puzzle out any of the others. The methods used to study one governor should work to study all of them, only minor tweaks required. If you find techniques to measure the strength of one governor, you should be able to use those techniques to measure the strength of any governor.
But other ways in which people differ seem more idiosyncratic. They are probably the result of different parameters that tune features that are more global, each of which interacts with the whole system in a unique and different way. So we will probably need to invent new methods for each of them.
That means we can’t yet write a section on the different methods that will be useful. These methods still need to be invented. And we might only get to these methods once we have learned most of what there is to know about the differences in strength between the governors, and have to track down the remaining unexplained differences between people. But we can give a few examples to illustrate what some of these questions and methods might look like.
Learning
Every governor has to have some way of learning which behaviors increase/decrease their errors. We don’t know exactly how this learning works yet, but we can point to a few questions that we think will be fruitful.
For example, is learning “both ways”?
The hot governor (keeps you from getting too hot) and the cold governor (keeps you from getting too cold) both care about the same variable, body temperature. Certainly if you are too cold and you turn on a gas fireplace, your cold governor will notice that this corrects its error and will learn that turning on the gas fireplace is a good option. So when you get too cold in the future, that governor will sometimes vote for “turn on the gas fireplace”.
But what if you are too hot and you turn on the gas fireplace? Well, your hot governor will notice that this increases its error, and will learn that this is a bad option, which it will vote against if you’re in danger of getting too hot.
What does your cold governor learn in this situation? Maybe it learns the same thing your hot governor does — that the gas fireplace increases temperature. The hot governor thinks that’s a bad outcome, but the cold governor thinks it’s a good outcome. If so, then next time you are cold, the cold governor might vote for you to turn on the gas fireplace.
But maybe a governor only learns when its error is changed. After all, each governor only really cares about the error it’s trying to send to zero. And if that error isn’t changed, maybe the governor doesn’t pay attention. If the error is very small, maybe that governor more or less turns off, and stops paying attention, to conserve energy. Then it might not do any learning at all.
If this were the case, the cold governor shouldn’t learn from any actions you take when you’re too hot, even when these actions influence your body temperature. And the hot governor shouldn’t learn from anything you do when you’re too cold, same deal.
You could test this by putting a mouse in a cage that is uncomfortably hot, and that contains a number of switches. Each switch will either temporarily increase or temporarily decrease the temperature of the cage. With this setup, the mouse should quickly learn which switches to trip (makes the cage cooler) and which switches to avoid (makes the cage even more uncomfortably hot).
Once the mouse has completely learned the switches, then you make the cage uncomfortably cold instead, and see what happens. If the cold governor has also been learning, then the mouse should simply invert its choice of switches, and will be just as good at regulating the cage temperature as before.
But if the cold governor wasn’t paying close attention to the hot governor’s mistakes, then the mouse will have to do some learning to catch up. If the cold governor wasn’t learning from the hot governor’s mistakes at all, then the mouse will be back at square one, and might even have to re-learn all the switches through trial and error.
We definitely might expect the former outcome, but you have to admit that the latter outcome would be pretty interesting.
The Model of Happiness
Or consider the possibility that happiness might drive learning.
This would explain why happiness exists in the first place. It’s not just pleasant, it’s a signal to flag successful behavior and make sure that it’s recorded. When something makes you happy, that signals some system to record the link between the recent action and the error correction.
This would also explain why it often feels like we are motivated by happiness as a reward. We aren’t actually motivated by happiness itself, but when something has made us happy, we tend to do it more often in the future.
Previously we said that happiness is equal to the change in an error. In short, when you correct one of your errors, that creates a proportional amount of happiness. This happiness sticks around for a while but slowly decays over time.
That’s a fine model as a starting point, but it’s very simple. Here’s a slightly more complicated model of happiness, which may be more accurate than the model we suggested earlier. Maybe happiness is equal to the reduction in error times the total sum of all errors, like so:
happiness = delta_error * sum_errors
If happiness is just the result of the correction of an error, then you get the same amount of happiness from correcting that error in any circumstance. But that seems a little naïve. A drink of water in the morning after a night at a five-star hotel is an accomplishment, but the same drink of water drawn while hungry and in pain, lost in the wilderness, is a much greater feat. Remembering the strategy that led to that success might be more important.
If you multiply the correction by the total amount of error, then correcting an error when you are in a rough situation overall leads to a much greater reward, which would encourage the governors to put a greater weight on successes that are pulled off in difficult situations. If you correct an error when all your other errors are near zero, you will get some happiness. But if you are more out of alignment generally — more tired, cold, lonely, or whatever — you get more happiness from the same correction.
This might explain fetishes. Why do so many sexual fetishes include things that cause fear, pain, disgust, or embarrassment? Surely the fear, pain, disgust, and embarrassment governors would vote against these things.
We have to assume that the horny governor is voting for these things. The question is, why would it vote for anything more than getting your rocks off? Why would an orgasm plus embarrassment be in any way superior to an orgasm in isolation?
If learning is based on happiness rather than raw reduction in error, then governors will learn to vote for things that have caused past happiness.
And if happiness is a function of total error, not just correction in the error they care about, governors will sometimes vote for things that increase the total error just before their own error is corrected.
The point is, if happiness is a function of total error, governors will actually prefer to reduce their errors in a state of greater disequilibrium. This doesn’t decrease their error any more than in a state of general calm, but it does lead to more happiness, greater learning, and so they learn to perform that action more often. And in some cases they will actually vote to increase the errors of other governors, when they can get the votes.
The horny governor only cares about you having an orgasm. But since it learns from happiness, not from the raw correction in its error, it has learned to vote for you to become afraid and embarrassed just before the moment of climax, because that increases your total error, which increases happiness. And since the horny governor has the votes, it overrules the governors who would vote against those things.
We don’t know how to quantify any of the factors involved, so we can’t test precise models. There are probably constants in these equations, but we can’t figure those out either, at least not yet.
But we can still make reasonable tests of general classes of models. We can make very decent guesses about whether or not something is a function of something else, and we can probably figure out if these relationships are sums or products, whether relationships are linear or exponential, and so on. For example:
happiness = delta_error
This is the original model we proposed, and it’s the most simple. In this case, happiness is caused when an organism corrects any error, and the amount of happiness produced is a direct function of how big of an error was corrected. Eating a cheeseburger makes you happy because, assuming you are hungry, it corrects that error signal. The cheeseburger error.
Not shown in that equation is the kind of relationship. Maybe it’s linear, but maybe it’s exponential. Does eating two cheeseburgers cause more than twice as much happiness as eating one?
This very simple model has the virtue of being very simple. And it seems like it lines up with the basic facts — eating, sleeping, drinking, and fucking do tend to make us happy, especially if we are quite hungry, tired, thirsty, or horny.
But we should also think about more complex models and see if any of them are any better. For example:
happiness = delta_error * product_errors
In this case, the correction in an error is multiplied not by the sum, but by the product of all other errors. So eating a cheeseburger while tired and lonely will be much more pleasurable than eating a cheeseburger while merely tired or merely lonely.
This seems pretty unlikely just from first glance. If happiness were dependent on the product of your other errors, that seems like it would be pretty noticeable, because the difference between correcting an error while largely satisfied and largely unsatisfied would be huge and thus obvious. But this is also something that you could test empirically and maybe there could be some kind of truth to it.
Is this a better model? Not entirely clear, but it certainly makes predictions that can be compared to parts of life we’re familiar with, and it can be tested empirically. That’s a pretty good start.
Or another example:
happiness = delta_error / sum_errors
Instead of multiplying the correction to produce happiness, this time we tried dividing it. In this case, happiness is smaller when the total amount of error is bigger. So correcting the same error leads to less happiness if you’re more out of alignment.
This one seems right out. The joy we get from a cup of hot chocolate is greater when we are lonely, not less. Living in extremis seems like it should only magnify the satisfaction of our experiences. It’s possible that this doesn’t stand up to closer inspection, but people certainly find the idea intuitive:
Another model of happiness is that happiness is proportional to the TD error in the equation above, or the equivalent in whatever system our brain really uses. The TD error is the difference between the current and projected outcome of the action and the expected outcome of the action. So in this model, we get happiness when something corrects an error by more than the governor expects.
Having an especially great sandwich for the first time feels great. This is because you didn’t know how good it would be. But having the same sandwich for the 100th time isn’t as good, even if it corrects the same amount of error. This is because you anticipated it would be that good, so there’s no TD error. In fact, if the sandwich hits the spot less than usual, you’ll be disappointed, even if it’s still pretty good.
In this model, you’d expect that doing the same enjoyable stuff over and over wouldn’t keep you happy for very long. You’d have to mix it up and try new things that correct your errors.
This model does seem to capture something important. But that said, in real life correcting a big enough error usually creates some happiness. So happiness doesn’t seem like it could be entirely based on how unexpected the correction is. Some amount of happiness seems to come from any correction. But it does seem like more unexpected corrections usually make us more happy.
So this is an example of how we can test general models, even before we can make precise measurements. We can think about classes of models, bring them to their limits, ask how the implications of these models compare to other things we already know about life and happiness, things we experience every day.
Just thinking of these questions mechanically, thinking of them as models, prompts us to ask questions like — What is the minimum amount of happiness? Can happiness only go down to zero, or can there be negative happiness? Is there a maximum amount of happiness? Even if a maximum wasn’t designed intentionally, surely there is some kind of limit to the value the hardware can represent? Can you get happiness overflow errors? What is the quantum of happiness? What are the units? — questions that psychologists wouldn’t normally ask.
Human nature is not a machine to be built after a model, and set to do exactly the work prescribed for it, but a tree, which requires to grow and develop itself on all sides, according to the tendency of the inward forces which make it a living thing.
—John Stuart Mill
The cybernetic paradigm gives you a theory of personality for free.
There are lots of governors in your mind, and some governors are stronger than others. Other things being equal, a stronger governor has more influence over your actions than a weaker governor. It gets more votes and has more of a say when it comes time for your governors to decide what to do.
Someone with an unusually strong hunger governor will seek out food sooner and will spend more effort to get it than someone with an especially weak hunger governor.
Someone with an especially strong status governor will be especially sensitive to changes in their status, and will invest lots of time and effort into status games. Someone with an especially weak status governor will appear almost blind to status, and it will hardly ever influence their behavior.
This provides the cybernetic paradigm’s theory of personality. People differ in many ways, but a particularly important way they can differ is in the strength of each of their different governors/emotions. In the cybernetic paradigm, differences between people are differences between parameters like the setpoints, strength, and sensitivity of their different governors.
To say that one person is more extraverted than another is to say either that their setpoint for social interaction is higher, that they defend the setpoint more aggressively, or that they’re more sensitive to disturbances away from that setpoint. To say that someone is brazen is to suggest that their shame governor is weaker than normal. To say that they are humble says something about the governor that pays attention to status.
Let’s break this down a little further.
First: People can have different setpoints for the same governor. We don’t know what units danger is measured in, but if one person has a danger set point of 5 units and another person has a danger set point of 10 units, the first person will keep themselves much safer than the second person. They will avoid situations where they feel that danger is above 5 units, while the other person won’t be sensitive, won’t feel any fear, until the danger is much higher.
That said, we actually don’t think that most personality differences are differences in setpoints, because the setpoints we know about are pretty similar across different people. Most people defend very similar setpoints for body temperature (about 98.6 °F), very similar setpoints for plasma osmolality (about 280 mOsm/L), very similar setpoints for serum potassium (about 4 mmol/L).
But there are certainly some exceptions. People can defend very different body weights, making some people extremely lean and others extremely obese. And set points can change, so they’re sometimes different even within one person. A fever is a short-term change in the body temperature set point(s). Obesity is a long-term change in the body weight set point(s).
Finally, even if people do defend very similar setpoints across the board, there will always be small differences between their setpoints, which will lead to some differences in personality.
Second: People’s governors can be stronger or weaker when it comes time to negotiate with other governors. When two governors disagree, which one wins?
Mark’s anger governor is especially strong, and gets many more votes than the other governors. So when anger goes up against anything else, it almost always wins. Mark has anger-control issues.
Julie’s fatigue governor is especially weak, and gets many fewer votes than the other governors. So when fatigue goes up against anything else, it almost always loses. Julie often stays up until she is very tired, doing all sorts of activities until she practically collapses. She barely seems aware that she’s tired. Even when she lies down, she often has a very hard time falling asleep. If there’s anything else she has in mind, her fatigue is not strong enough to keep her from thinking of it, then getting up and doing it.
You can describe this in terms of each governor having a different weight, with a weight of 1 meaning average strength. If one of your governors has a weight of 1, then that drive is as strong for you as it is for the average person. Weights above 1 mean the governor is stronger than normal; weights below 1 mean it’s weaker.
If you are born with the weight on your fear governor set to 2, your experience of fear is twice as powerful as normal, it has something like twice the influence over your actions. This makes you very cowardly, since your fear becomes overpowering in situations that other people would find mildly concerning. After all, it has twice as many votes as usual!
If you are born with the weight on your fear governor set to 0.5, your experience of fear is half as powerful as normal, it gets half as many votes as it would normally. This makes you very brave. In situations that other people would find terrifying, your fear barely has enough votes to call a motion.
Third: People’s governors can be more or less sensitive to disturbances. By analogy, a thermostat might have a narrow or a wide acceptable range around the target temperature. Strict sensitivity would mean frequent corrections as soon as the temperature drifted even 0.1 °F away from the set point, while a looser control system would allow more drift before it reacts, with control not kicking in until it was 2-3 °F off target.
This is a natural tradeoff. Strict/aggressive control means you spend more energy, reacting even to small changes and adjusting constantly, but it also means you stay very close to the set point. Loose/sluggish control means you spend more time out of alignment but you also save a lot of energy on not making all these neurotic adjustments. Some things really do need to be kept right at the set point, but other things can be allowed to wander a bit.
We think these three kinds of differences are probably important. But just to show that this isn’t an exhaustive list, here are two more ways that people’s governors might be different.
For example, an important parameter in control systems is gain. A sluggish system applies weak corrections (low gain), meaning it takes longer to reach the target. An aggressive system cranks up corrections harder (high gain), leading to faster changes, but possibly overshooting.
So some governors respond to an error with a big correction all at once, while other governors respond to an error of the same size with many small, incremental corrections. This might look like a personality difference of overreacting or underreacting.
This isn’t the same as sensitivity to disturbances. For example, Julie has a cleanliness governor with low sensitivity and high gain. She lets her apartment get pretty dirty (because of the low sensitivity), but once it’s a certain level of mess, she cleans it all at once, back to a high level of cleanliness (high gain).
Mark also has a cleanliness governor with low sensitivity, but his has low gain. He also lets his apartment get pretty dirty (because of the low sensitivity), but once it’s a certain level of mess, he slowly cleans it bit by bit until it doesn’t bother him anymore (low gain).
A related idea is damping. Some thermostats have a built-in “wait time” after making a correction, which helps prevent the temperature from swinging wildly. If our governors have some kind of damping, this might also vary between people.
With a fear governor set to low damping, you would respond very quickly to danger, but might sometimes freak out over nothing. It might even look like an extreme flinch response. With a fear governor set to high damping, you would respond very slowly and deliberately to new threats — good in some situations, but very bad in others!
All these parameters can combine in some interesting ways. Consider two people who have unusual sugar-governors, but unusual in different ways. Alice has a normal sugar setpoint, but her sugar-governor is unusually strong. Bob has a normal weight on his sugar-governor, but an unusually high sugar setpoint.
Alice’s sugar-governor gets more votes than other people’s. Since it tends to have the votes it needs, from the outside this looks like making sweet foods a priority. She always eats her sweets first. But if you kept a close measure of how much sugar she’s eating, you’d see that it’s actually the same amount as the average person, because her set point is the same.
Bob’s sugar-governor gets the normal amount of votes, but aims for a higher setpoint. For a given level of desire, Bob doesn’t prioritize sugar more than other people. But if you keep track over the long term, he does consume more sugar to reach that higher set point.
The upshot is that there are at least as many personality dimensions as there are emotions, and each of these personality dimensions are linked to the “settings” of a particular emotion.
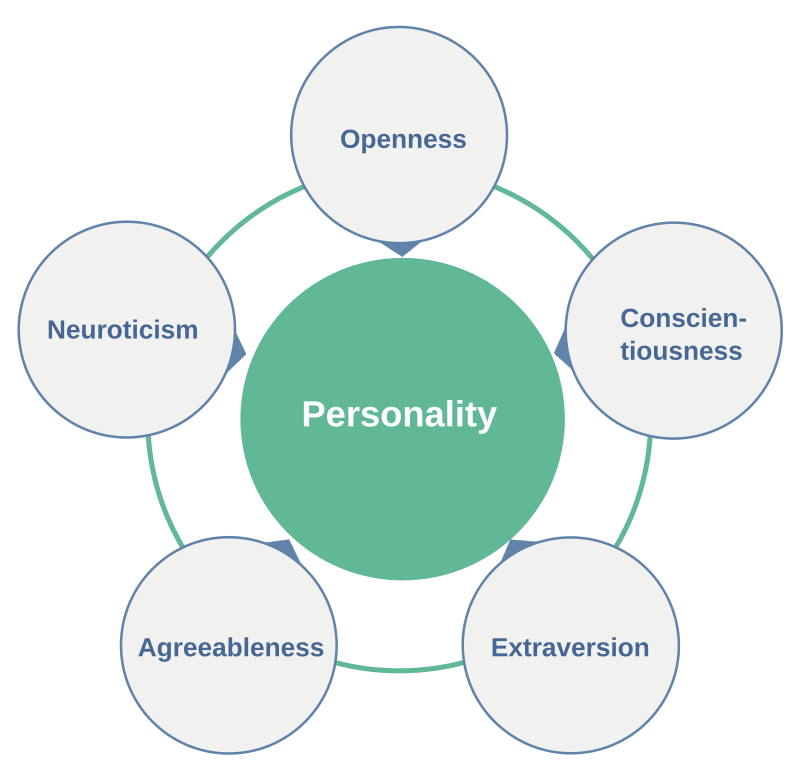
This theory comes from statistical analysis. When you have people rate themselves and others on a wide variety of adjectives, and then apply various statistical techniques, you usually end up with five clusters of adjectives. Over time people settled on a set of labels for those clusters: openness, conscientiousness, extraversion, agreeableness, and neuroticism.
It’s not hard to see how these might map on to various emotions. For example, extraversion is probably a rough measure of the strength of various social emotions.
But the Big Five has some problems as a theory. The first one is fundamental — the Big Five are an abstraction, not a model. We all have a casual sense of what it means to be neurotic, we know what kind of superficial behavior to expect from someone described with this word, but the theory doesn’t say anything about the mechanisms that cause someone to behave in a neurotic way. It caps out at being able to record that one measure is correlated with another measure. It can neither explain, nor in any meaningful way can it predict. (For more about these problems, see The Prologue.)
Rather short of a wiring diagram
In addition, the method psychologists used to come up with these five factors is limited.
The Big Five were discovered through a method called factor analysis, a statistical approach that searches for clusters of correlated variables and hypothesizes factors that might account for the patterns it finds. Psychologists collected large sets of descriptive adjectives like “friendly” and “bashful” and had people rate how well the adjectives applied to themselves or others. Then they used factor analysis to estimate how these ratings co-occurred. This usually gave a solution of five factors — five clusters of adjectives that tended to be highly correlated within the clusters.
But language doesn’t capture all of the true personality differences, or at least doesn’t capture all of them to the same degree.
There are some terms, like “salt tooth” and “sweet tooth”, which hint at recognition of the fact that in some people the salt-hunger governor is unusually strong, and in other people the sugar-hunger governor is unusually strong. But these terms aren’t as much a part of our language as dimensions like “does this person spend lots of time around other people” or “is this person reliable”, which come out into the factors of “extraversion” and “conscientiousness”.
This is for social-historical reasons — at the moment, our culture cares a lot about communicating whether or not a person is sociable and/or reliable, and cares very little about their preferences for sweet or salty foods. Compare this to how Ancient Greek and Latin both had lots of different words for different kinds of shields. In their culture, the kind of shield you used said a lot about where you fit in society, so they had terms to make these distinctions. But in our culture no one cares what kind of shield you use, so modern English does not.
Different times and cultures will have different priorities, and will want sets of words that help them describe variation in the drives they care about the most. There’s still variation in the drives they don’t care about as much, but since they don’t care about that variation, they won’t talk about it, so they won’t need any words for it.
The fear governor is real, and martial cultures of the past had many ways to talk about differences in how someone responds to fear. How you responded to fear was very relevant in these cultures, it came up a lot. But today we are safe most of the time and these differences rarely matter, so the words we’ve inherited from such times, like brave and cowardly, are too few to pull their own group in a factor analysis. (You could get more by adding archaic terms like dauntless, plucky, valiant, doughty, aweless, and orped, but these probably don’t go in the surveys.)
The Icelandic language, on the other hand, which has changed much less than English over the centuries, still retains several words for these concepts — huglaus, óframur, ragur, blauður, deigur, all these mean something like “fearful” or “cowardly”. And on the opposite side, Icelandic has about a dozen words for “brave”.
But even though English doesn’t give them dozens of adjectives apiece, emotions like cold, tiredness, needing to pee, etc. all have personality dimensions just the same. Some people are driven more by the need to keep warm, and some barely notice the cold. Some people are driven by their bed. For some people, when nature calls, you must answer.
The seven deadly sins are a bit judgy as a personality measure, but they had it a little better. Gluttony and sloth are clearly ways to talk about individual differences in things like hunger and tiredness. And lust is, if anything, one of the most notable personality dimensions. How could you possibly explain Aella’s personality without mentioning that she is much, much hornier than average? On the opposite side, having a weight on this governor near zero would lead to asexuality, so being asexual should also be understood as part of personality.
Individual Differences
There are also some differences that are not linked to the emotions and drives, that don’t reflect the settings on different governors.
For example, people can also be different in the parameters of motivation we described in Part II; like the gate threshold, i.e. the minimum number of votes to make an action happen. If you have a higher gate threshold, you are more likely to just sit there and less likely to do anything, every action needs a larger number of votes just to activate. If you have a lower gate threshold, you are constantly jumping around, every time an action gets any votes, you do it. Similarly, to say that someone is decisive is to imply something about the parameters of their selector, not their governors.
One underrated individual difference is being a night owl versus being a morning lark (sometimes called your chronotype). The dimension is related to sleep, but doesn’t seem like a parameter of the drive for sleep (probably?). Instead it’s a tendency or preference for when sleep will occur.
Some people are certainly more curious than others. But curiosity may not be an emotion, because it doesn’t seem to be satisfying a drive to send a signal to some specific target.
Another difference is taste preference. Certainly some tastes, like those for salt or fat, are nutritive, necessary for survival, and therefore probably controlled by a governor. But some taste preferences may not come from the drives, they may just be variation. Chunky and creamy peanut butter have almost exactly the same nutritional profile, but some people prefer one to the other. The same goes for preferences for smells — there is probably not a lavender-smell governor, but some people still like the smell of lavender more than others.
If these preferences really are preferences, and aren’t attached to drives, we’ll be able to tell because they will not be exhausted like drives are. Even someone who likes salt very much will eventually eat enough salty food and will stop eating it for a while. Their salt drive will send its error signal to zero and then be satisfied. But someone who likes the smell of lavender shouldn’t get satisfied by it in the same way, their preference should be mostly constant.
The reason for these differences is the same as for any kind of differences: diversity. It’s not just random chance; it is by design, because: bees.
How do the bees decide how many of them should be fanning? … There’s no communication, but as the ventilation gets worse in the hive, more and more bees start fanning their wings. How would you design bees to solve this problem? You don’t want every bee fanning their wings 24/7 or they’re wasting time, but a nice ratio of ‘bees fanning’ to ‘bees not fanning’ that adapts in order to hit your ventilation criteria.
When Huber examined the fanning problem, he came up with an elegant theory. He suggested that bees are differentially sensitive to noxious smells. So as the noxious smells get worse, the sensitivity threshold of more and more bees is reached, and more of them begin fanning until ultimately the entire hive is fanning.
If everyone in your village has the same set point for danger, then as danger increases, for a long time no one takes any precautions, and then at some point everyone flips over and starts fortifying the town all at once. This is kind of a nuts way to do things.
It’s better to have some diversity. If there’s only a little danger, a small number of villagers are stockpiling food and reinforcing the town walls. As the danger increases, more and more villagers attend to the safety of the town. This is actually its own form of control system.
The same thing goes for preferences. If everyone in your band of hunter-gatherers falls asleep exactly at dusk and rises at dawn, then you are all defenseless at the same time. But if some of you are morning larks and some of you are night owls, then someone is always awake to tend the fire and watch for saber-toothed tigers.
Now apply the same reasoning to taste and smell. If everyone in your town has identical tastes, then they will all eat pretty much the same food; if that food becomes rotten, everyone gets sick at once. Better to have variation in food preferences so you’re eating different things. Then if some food goes bad, only some of you get sick. Avoid a single point of failure.
To sum up, differences in the strength of different governors are a major part of personality, though not the only part. There are also various other individual differences, including simple preferences.
Sex Differences
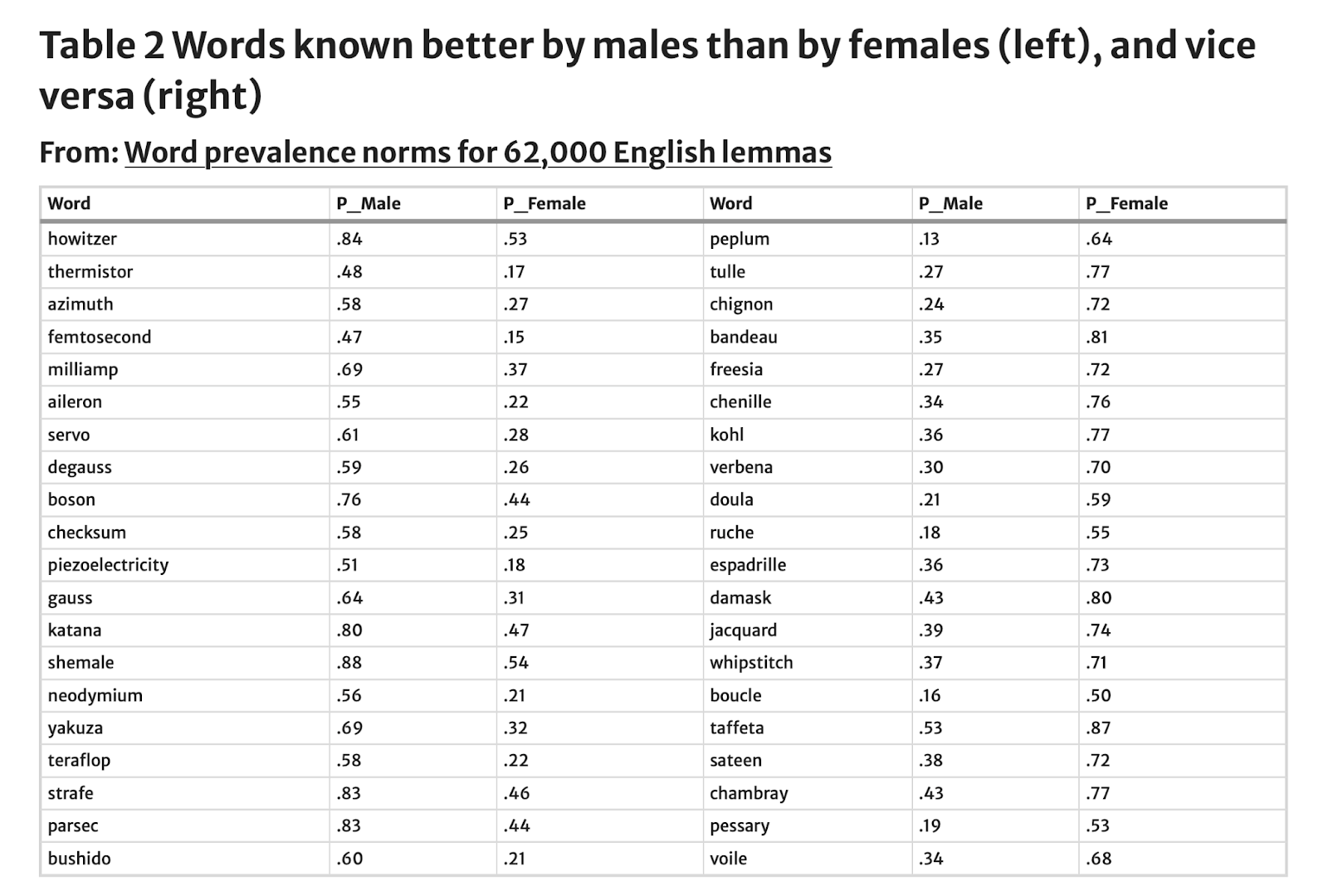
Academic psychologists claim they can’t find any clear mental differences between the sexes (mostly; for the nuanced version of things, see here). But here’s one: the huge and obvious differences in the desire to play certain kinds of video games.
About half of gamers are women. But a few genres are overwhelmingly played by men. In particular, men are much more interested in tactical shooters like ARMA 3, and in grand strategy paint-the-map games like Europa Universalis. These games are about violent competition and domination, so this pattern may point to the existence of something like a “need to dominate” emotion.
Looking closer, the experience of shooters and strategy games are quite different, suggesting that there might actually be two separate dominance-related emotions that tend to be much stronger in men than in women. Let’s consider these drives one at a time.
The experience of a tactical shooter is shooting people in the head; it’s about as close as you can get these days to crushing your enemies, seeing them driven before you, and hearing the lamentations of their women. You may be wondering whether people really have a drive for such a thing, especially if you don’t play tactical shooters. But there’s good evidence that many people do. As one example, the subreddit r/CombatFootage (TAKE CARE IN CLICKING, CONTAINS DISTURBING COMBAT FOOTAGE) has 1.7 million members. Top videos on the subreddit get thousands of likes and hundreds of comments. For comparison, r/vegan also has 1.7 million members. Some people really want to see this stuff.
In contrast, grand strategy games are abstract and bloodless, lovingly referred to as spreadsheet simulators. These don’t seem like they could be about personal, physical domination, since they don’t even simulate that. But they’re not pacifistic — they do a very good job simulating the experience of forcing other societies to make concessions, become your vassals, and so on.
Between the two genres, there’s plausibly one dominance emotion about personally thrashing your enemies, and another dominance emotion about being in charge of organizing the logistics of thrashing — something like social domination, or having your group dominate other groups.
Paradox games!
We see something similar in the list of words known better by males than by females, and vice versa. Men are much more likely to know words like howitzer, katana, and bushido (not just military terms, but historical military terms) while women are much more likely to know words like peplum, chignon, and damask (fabric and hairdressing terms). The authors of this paper characterize the result as, “gender differences in interests (games, weapons, and technical matters for males; food, clothing, and flowers for females)”.
even more spreadsheets
The list suggests that on average men tend to have stronger dominance emotions and women tend to have stronger decorative emotions, or perhaps hygienic emotions (in the sense that being properly dressed is hygiene).
We are of course talking about average differences. There are plenty of women with strong dominance emotions, and plenty of men with strong decorative emotions. (And women may in fact have higher tuning on a different set of dominance emotions.) But on average there seems to be some difference.
We don’t care about the cause — differences could be the result of socialization, of nature, or both. Or something else. But there do seem to be average personality differences between the sexes, which make perfect sense when you think of personality as differences in the strength of different governors.
It’s also worth considering if sex differences we think of as physiological might actually be psychological. Women typically feel colder than men — this might be biological, something to do with their body size or metabolic rate. But it could also be psychological, something to do with the set point or strength of their cold governor.
Psychiatry
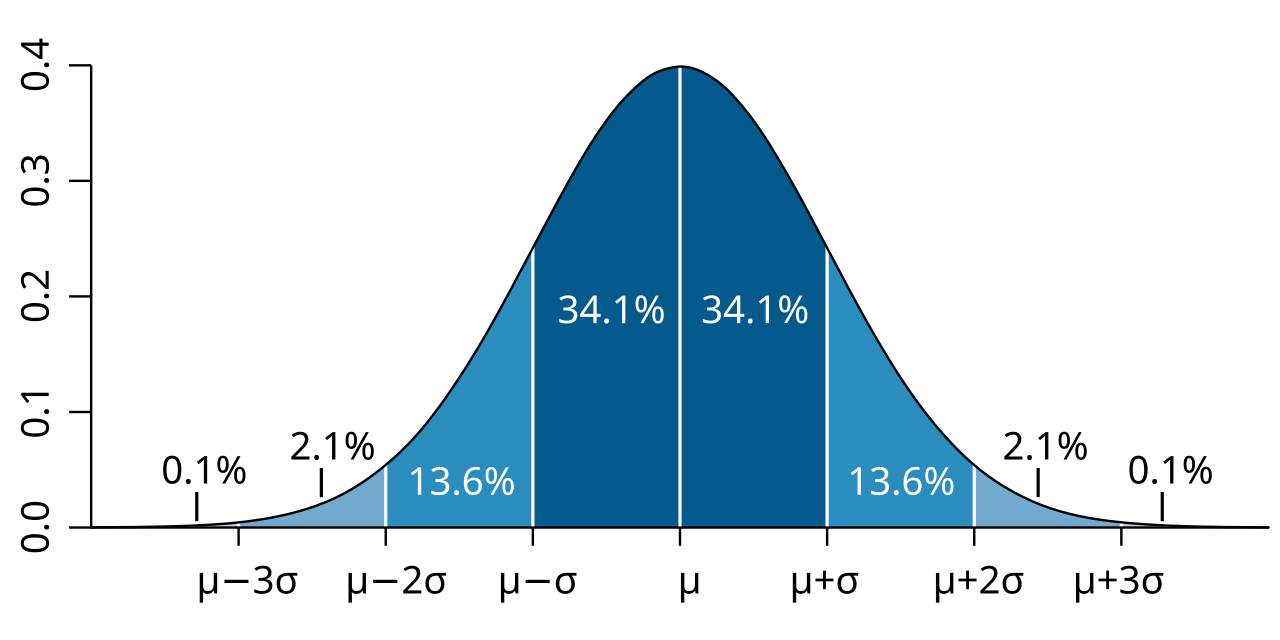
Like most biological attributes, the strength of our governors probably falls on a normal distribution. The majority of people will have a fairly usual weight on each governor. But in rare cases, weights will be set incredibly high or incredibly low.
Since we have no idea what the units are for “strength of a governor”, as before we will just say that 1 is the population average. Having a weight of 0.5 on a drive means it is half the strength of the population average, and having a weight of 2 on a drive means it is twice the strength of the population average.
If you set the weight on a governor to 0, we call this a “knockout”. It’s functionally equivalent to not having that drive at all, because when the weight on a governor is 0, the governor gets no votes.
For example, take Alex Honnold, sometimes called “the World’s Greatest Solo Climber”. Alex enjoys climbing sheer cliffs without a rope, an experience so terrifying that many people can’t even stand to watch the videos. When neuroscientists put Honnold through an fMRI and showed him terrifying and gruesome pictures, they found that his brain is intact — he does have an amygdala — but he has almost no fear response.
Whatever the exact biological issue might be — whether he was born that way, or if he’s somehow turned down the fear governor through training and exposure — Honnold appears to be someone with a fear knockout. The weight on his fear governor is set very close to zero.
In cybernetic psychology, a lot of psychiatric conditions look, in a literal sense, like personality disorders. Personality is largely made up of differences in the weights on a person’s various governors. Personality disorders occur when some of those weights are not merely different, but set extremely low or extremely high.
Consider fear. Most people are somewhat concerned about things some of the time. They have a weight on their fear governor around 1. If you set the weight on “fear” to 10, they will instead be very concerned about things lots of the time. That looks a lot like paranoia.
This is a good spot to point out that a cybernetic system has multiple parts and can be broken in many ways. Let’s take the fear governor as an example.
You can break the input function, so it perceives danger as being higher than it otherwise would. This will cause paranoia. You can change the fear governor’s set point to a very low level of danger, so it reacts to even very small amounts of danger. This will cause paranoia. You can damage the output function, so that it thinks that large interventions are appropriate for small amounts of danger. This will cause paranoia. Or you can change how many votes the fear governor gets in the parliament of the mind. Again, this will cause paranoia.
These changes may present slightly differently, but notice how even though these are four different problems with the fear governor, you end up seeing basically the same behavior in every case. Among other things, this makes diagnosis and treatment quite tricky. You have at least four disorders, with categorically different causes, yet nearly identical presentation.
This also offers a plausible model for conditions like autism and psychopathy. Both appear to be congenital abnormalities in various emotions — conditions that happen when you are born with a couple of your emotions unusually strong or weak.
“Autism” seems to be a label that we apply to people who have very low weights, or complete knockouts, on some of their social emotions.
“Psychopathy” seems to be a label that we apply to people who have very low weights or knockouts on a different set of social emotions, especially when combined with high weights on emotions like anger or need for dominance.
As you can tell from our hedging, we suspect these categories are poorly-formed. There probably isn’t “a disorder” that can be identified with autism. It’s just a word, an abstraction that we use to refer to various personality types that are similar in the sense that they have low weights on certain social emotions. (See the Prologue for more on this.)
Autism and psychopathy are often framed as deficiencies, but you can also see them as deficiencies in some things combined with superabundances in other things.
We tend to call people “psychopaths” not when they merely lack in fear or compassion, but when a lack of fear or compassion are combined with unusually strong drives for status and dominance.
People tend to be considered autistic not when they merely lack a drive for status, but when this is combined with unusually strong interest in social rules and an unusually strong drive for compassion. People get confused about this. You often hear things like, “people who are autistic don’t understand social conventions”. But actual people who are autistic seem to believe things like, “if you eat a non-prime number of chicken nuggets you’re breaking the rules”.
It’s not clear if these are specific “disorders”, or just the extremes of normal personality variation. Some people have stronger social emotions than others. When the weights on your social emotions are 0.7, nobody cares, you just seem kind of introverted. But when some of your weights are 0.5 or lower, maybe they start calling you autistic.
Same thing for psychopathy. The lower your social weights are, and the higher your aggression and dominance weights, the more likely people are to call you a psychopath. But there’s not a bright line. It’s more like height than blood type. Type O and type AB blood are categorically different, but there’s no objective point at which you become “tall” or “short”, those are relative.
Recap
People differ in many ways, but a particularly important way they can differ is in the strength of each of their different governors/emotions. In the cybernetic paradigm, personality is the result of differences between parameters like the setpoints, strength, and sensitivity of different governors.
People can have different setpoints for the same governor.
People’s governors can be stronger or weaker when it comes time to negotiate with other governors. When two governors disagree, which one wins?
People’s governors can be more or less sensitive to disturbances.
People’s governors can have different amounts of gain, applying weak corrections or strong corrections.
People’s governors can have different amounts of damping.
The Big Five are an abstraction, not a model.
The Big Five were discovered through a method called factor analysis, a statistical approach that searches for clusters of correlated variables and hypothesizes factors that might account for the patterns it finds.
Psychologists collected large sets of descriptive adjectives like “friendly” and “bashful” and had people rate how well the adjectives applied to themselves or others. Then they used factor analysis to estimate how these ratings co-occurred. This usually gave a solution of five factors.
But language doesn’t capture all personality differences, or at least doesn’t capture all of them to the same degree.
There are also some individual differences that are not linked to the emotions and drives, like your chronotype or your taste preferences.
The reason to have personality differences is the same as for any kind of differences: diversity.
It’s better to have diversity. If there’s only a little danger, a small number of villagers are stockpiling food and reinforcing the town walls. As the danger increases, more and more villagers attend to the safety of the town.
Remember: bees!
There appear to be large sex differences in the strength of some of the governors.
Many psychiatric conditions are probably personality disorders, the result of the weights on a person’s various governors being set extremely low or extremely high.