
A few people have asked us why we didn’t preregister the analysis for our potato diet study. We think this shows a certain kind of confusion about what preregistration is for, what science is all about, and why we ran the potato diet in the first place.
The early ancestor of preregistration was registration in medical trials, which was introduced to account for publication bias. People worried that if a medical study on a new treatment found that the treatment didn’t work, the results would get memory-holed (and they were probably right). Their fix was to make a registry of medical studies so people could tell which studies got finished as planned and which ones were MIA. In this sense, our original post announcing the potato diet was a registration, because it would have been obvious if we never posted a followup.
Pre-registration as we know it today was invented in response to the replication crisis. Starting around 2011, psychologists started noticing that big papers in their field didn’t replicate, and these uncomfortable observations slowly snowballed into a full-blown crisis (hence “replication crisis”).
Researchers began to rally around a number of ideas for reform, and one of the most popular proposals was preregistration. At the time, many people saw preregistration as a way to save the foundering ship that was psychological science (and all the other ships that looked like they were about to spring a leak).
Calls for preregistration can be found as early as 2013, in places like this open letter to The Guardian, and on the OSF, where people were already talking about encouraging the use of preregistration with snazzy badges like this one:

But despite the early enthusiasm, preregistration is not a universal fix. It has a small number of use cases and those cases are specific. Part of being a good statistician is knowing how to preregister a study and knowing when preregistration applies, and it doesn’t apply all that broadly. We think preregistration has two specific benefits — one to the research team, and one to the audience.
We’ve preregistered studies before, and in our experience, the biggest benefit for researchers is that preregistration encourages you to plan out your analysis in advance. When you do a study without thinking far enough ahead, you sometimes get the data back and you’re like oh shit how do I do this, I wish I had designed the study differently. But by then it’s too late. Preregistration helps with this problem because you have to lay out your whole plan beforehand, which helps you make sure you aren’t missing something obvious. This is pretty handy for the research team because it helps them avoid embarrassing themselves, but it doesn’t mean much for the reader.
The main benefit the audience gets from preregistration is that preregistration makes it clear which analyses were “confirmatory” and which were “exploratory”. Some analyses you plan to do all along (“confirmatory”; no it doesn’t make any sense to us either), and some you only do when you see the data and you’re like, what is this thing here (“exploratory”; you are Vasco da Gama).

This is ok by itself because it does sort of help against p-hacking, which is one of the big causes of the replication crisis. When you do a project, you can analyze the data many different ways, and some of these analyses will look better than others. If you do enough analyses, you’re pretty much guaranteed to find some that look pretty good. This is the logic behind p-hacking, and preregistration makes it harder to p-hack because you theoretically have to tell people what analyses you planned to do from the get-go.
(This only works against p-hacking that comes about as the result of an honest mistake, which is possible. But there’s nothing keeping real fraudsters from collecting data, analyzing it, picking the analysis that looks best, THEN “pre”-registering it, and making it look like they planned those analyses all along. And of course the worst fraudsters of all can just fabricate data.)
But here’s something they don’t always tell you: p-hacking is only an issue if you’re doing research in the narrow range where inferential statistics are actually called for. No p-values, no p-hacking. And while inferential statistics can be handy, you want to avoid doing research in that range whenever possible. If you keep finding yourself reaching for those p-values, something is wrong.
Statistics is useful when a finding looks like it could be the result of noise, but you’re not sure. Let’s say we’re testing a new treatment for a disease. We have a group of 100 patients who get the treatment and a control group of 100 people who don’t get the treatment. If 52/100 people recover when they get the treatment, compared to 42/100 recovering in the control group, it’s hard to tell if the treatment helped, or if the difference is just noise. You can’t tell with just a glance, but a chi-squared test can tell you that p = .013, meaning there’s only a 1.3% chance that we would see something like this from noise alone. In this case, statistics is helpful.
But it would be pointless to run a statistical test if we saw 43/100 people recover with the treatment, compared to 42/100 in the control group. You can tell that this is very consistent with noise (p > .50) just by looking at it. And it would be equally pointless to run a statistical test if we saw 98/100 people recover with the treatment, compared to 42/100 in the control group. You can tell that this is very inconsistent with noise (p < .00000000000001) just by looking at it. If something passes the interocular trauma test (the conclusion hits you between the eyes), you don’t need to pull out the statistics.
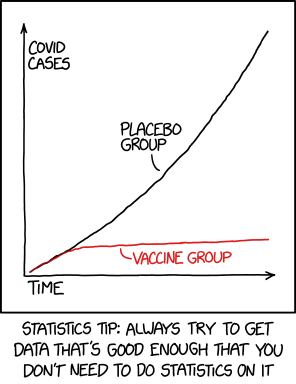
If you’re looking at someone else’s data, you may have to pull out the statistics to figure out if something is a real finding or if it’s consistent with just noise. If you’re working with large datasets collected for unrelated reasons, you may need techniques like multiple regression to try to disentangle complex relationships. Or if you specialize in certain methods where collecting data is expensive and/or time-consuming, like fMRI, you may be obliged to use statistics because of your small sample sizes.
But for the average experimentalist, you can get a sense of the effect size from pilot studies, and then you can pick whatever sample size you need to be able to clearly detect that effect. Most experimentalists don’t need p-values, period.
Better yet, you can try to avoid tiny effects, to study effects that are more than medium-sized, bigger than large even. You can choose to study effects that are, in a word, ginormous.

And it’s not like we really care about a simple distinction between working and not-working. The Manhattan Project was an effort to build a ginormous bomb. If the bomb had gone off, but only produced the equivalent of 0.1 kilotons of TNT, it would have “worked”, but it would also have been a major disappointment. When we talk about something being ginormous, we mean it not just working, but REALLY working. On the day of the Trinity test, the assembled scientists took bets on the ultimate yield of the bomb:
Edward Teller was the most optimistic, predicting 45 kilotons of TNT (190 TJ). He wore gloves to protect his hands, and sunglasses underneath the welding goggles that the government had supplied everyone with. Teller was also one of the few scientists to actually watch the test (with eye protection), instead of following orders to lie on the ground with his back turned. He also brought suntan lotion, which he shared with the others.
Others were less optimistic. Ramsey chose zero (a complete dud), Robert Oppenheimer chose 0.3 kilotons of TNT (1.3 TJ), Kistiakowsky 1.4 kilotons of TNT (5.9 TJ), and Bethe chose 8 kilotons of TNT (33 TJ). Rabi, the last to arrive, took 18 kilotons of TNT (75 TJ) by default, which would win him the pool. In a video interview, Bethe stated that his choice of 8 kt was exactly the value calculated by Segrè, and he was swayed by Segrè’s authority over that of a more junior [but unnamed] member of Segrè’s group who had calculated 20 kt. Enrico Fermi offered to take wagers among the top physicists and military present on whether the atmosphere would ignite, and if so whether it would destroy just the state, or incinerate the entire planet.
The ultimate yield was around 25 kilotons. Again, ginormous.
Studying an effect that is truly ginormous makes p-hacking a non-issue. You either see it or you don’t. So does having a sufficiently large sample size. If you have both, fuggedaboudit. Studies like these don’t need pre-registration, because they don’t need inferential statistics. If the suspected effect is really strong, and the study is well-powered, then any finding will be clearly visible in the plots.

This is why we didn’t bother to preregister the potato diet. The case studies we started with suggested the effect size was, to use the current terminology, truly ginormous. Andrew Taylor lost more than 100 lbs over the course of a year. Chris Voigt lost 21 lbs over 60 days. That’s a lot.
If people don’t reliably lose several kilos on the potato diet, then in our minds, the diet doesn’t work. We are not interested in having a fight over a couple of pounds. We are not interested in arguing about if the p-value is .03 or .07 or whatever. If the potato diet doesn’t work huge, we don’t want it. Fortunately it does work huge.
(We didn’t report a test of significance for the potato diet because we don’t think inferential statistics were needed, but if we had, the relevant p-value would be 0.00000000000000022)
What ever happened to looking for things that… work really well. No one has academic debates over whether or not sunscreen works. No one argues about penicillin or the polio vaccine. There was no question that cocaine was a great, exciting, very wonderful local anesthetic. When someone injects cocaine into your cerebrospinal fluid, you fucking know it.
We pine for a time when spirits were brave, men were men, women were men, children were men, various species of moths were men, dogs were geese, and scientists tried to make discoveries that were ginormously effective. Somehow people seem to have forgotten. Why are we looking for things that don’t barely work?
Maybe statistics is to blame. After all, stats is only useful when you’re just on the edge of being able to see an effect or not. Maybe all this statistics training encourages people to go looking for literally the smallest effects that can be detected, since that’s all stats is really good for. But this was a mistake. Pre-statistics scientists had it right. Smoking and lung cancer, top work there, huge effect sizes.
We know not everything worth studying will have a big effect size. Some things that are important are fiddly and hard to detect. We should be on the lookout for drugs that will increase cancer survival rates by 0.5%, or relationships that only come out in datasets with 10,000 observations. We’re not against this; we’ve done this kind of work before and we’ll do it again if we have to.
There’s no shame in tracking down a small effect when there’s nothing else to hunt. But your ancestors hunted big game whenever possible. You should too.
Good hunting.

There is a third reason to pre-register your study: it makes it easier to run prediction markets about it.
LikeLiked by 1 person
good point, this is a third reason
LikeLike
So your argument is that your study was exploratory and therefore preregistration was inappropriate, but because your results were significant enough you can discard the exploratory nature of the study and present the study’s results/conclusions as if the study was confirmatory?
LikeLike
you’re welcome to consider all the potato diet analyses exploratory if you like
LikeLike
Preregistering is still a good idea, even if you don’t plan to do any significance testing. There are still lots of decisions to be made when analyzing data (e.g. outlier detection, coding responses, etc.), and it’s good practice to make as many of those decisions as you can *before* you ever look at the data collected. But of course, this is most important for studies with small samples sizes, small effect sizes, large measurement errors, and/or high variation. Also more important when the data isn’t openly shared.
LikeLike
A bigger issue that preregistration solves is the problem of multiple comparisons. Basically, if you analyze the same data set 100 different ways (or to test 100 different hypotheses) with a significance level of 0.05, then you’ll get about 5 positive results just by random chance. If you then only tell people those 5 positive results, you can make it look like you found something significant when you’ve actually just amplified random noise.
LikeLike
Sort of. The thing is that p-hacked results abnormally cluster just below .05 — if you have a large enough sample size and/or you’re studying powerful enough effects, anything with p-value in the range .05 > p > .001 is almost certainly p-hacked (to an approximation; you can do math to get a more precise estimate).
Anything with .05 > p > .04 is probably p-hacked regardless of sample size.
LikeLike
If you are solely interested in effect sizes, “hacking” can still occur. For example, what if one analysis suggests an effect size of, say, d = 1.0 (p < .001) but another suggests an effect size of d = 1.5 (p < .001). Both are significant, but a larger vs. moderate effect speaks to whether people should adopt the potato diet. The confidence intervals may overlap.
LikeLike
good thing the effect size for the potato diet was d = 2.28 then
LikeLike
I get the sense that many of the commenters above are more interested in playing the game of science — and demonstrating their skill at knowing the rules of that game — than in explaining the world. Good on you slime moldies for cutting through to the heart of the matter and actually making progress on an important issue. I look forward to your further work in this area.
LikeLike
I wrote a longish comment but I am not sure if went through. Short TLDR:
All the diets claim ginormous effect sizes, especially those without experiments run outside controlled conditions. Seems unlikely they would all work. Relevant paper: “The piranha problem: Large effects swimming in a small pond”
Click to access piranhas.pdf
LikeLike