
Previously in this series:
N=1: Introduction
History
Single-subject or single-case research designs date back to at least the 1980s — though as you can see from the sparse Wikipedia page, they haven’t gotten that much attention. While the idea of single-subject research is good, the execution tends to be crap.
The simplest single-subject design is the “ABA” design, where you have a few control days (“A”), a few days on the treatment (“B”), and then you go back to the control (“A”). See for example this figure from the University of Connecticut:
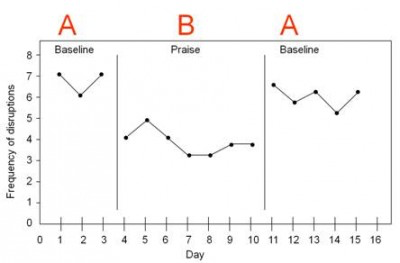
In this case, we can see that “frequency of disruptions” (from a target student) is high in the first baseline A block, goes down for a while in the B block (“praise”), and goes back up when they switch back to A.
The ABA design is better than nothing. It’s better than a case study, because at least there’s some experimental control. But it just doesn’t give us all that much information. They have 15 days of data, sure, but only three phases. This is really more like a sample size of three (not that a sample size of 15 is all that much more compelling).
Some sources might recommend the more advanced ABAB approach…

…but ABAB isn’t all that convincing either. Is that a change in the periods of “positive attention”, or just a random walk? It’s pretty hard to tell.
The ABA approach is what Seth Roberts used to argue that his “butter mind” protocol was effective, i.e. that eating more butter made him smarter. Take a look at this ABA graph from one of his self-experiments:
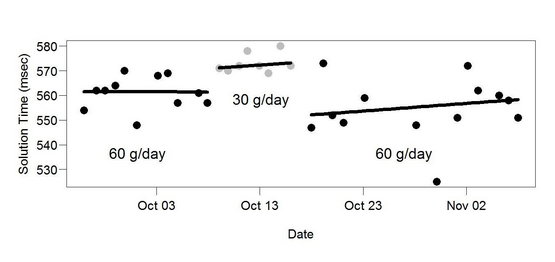
Again, this is vague at best. Yes, it took him longer to do arithmetic problems on 30 g/day butter than on 60 g/day butter. But the change is not very distinct, the three periods clearly overlap, it’s not clear if the periods were randomly determined, etc. And most of all, the sample size is just not very large — we can do better than drawing strong conclusions from a mere three intervals.
You shouldn’t totally discount these simple designs. Starting here can be fine (see for example Allan Neuringer’s self-experiments). Simplicity is important, and if you’re doing early stage exploratory work, going with a study design that’s easy has obvious benefits. If you don’t see any difference with this simple approach, you can move on to something else. If you do see a difference in the ABA, and you want to demonstrate that difference in a more convincing way, then you can expand it into a true within-subjects study.
There’s nothing wrong with Seth’s butter ABA — it’s just that it looks like the start of something, rather than a conclusion. If he wanted to really convince people, he should have spun that off into a longer self-experiment.
Within-Subjects Approach
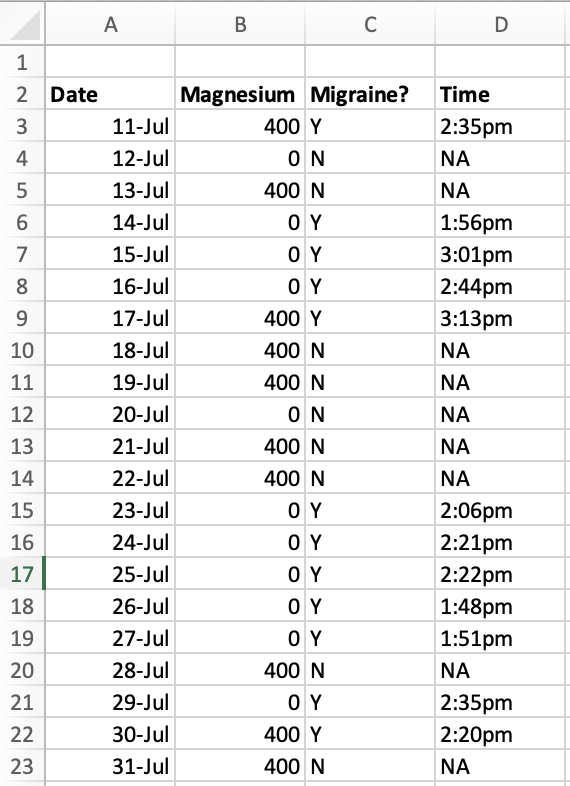
Emily is a woman in her late 20s who gets migraines on a regular basis. She usually gets hit with a migraine in the middle of the afternoon, and they happen almost every day. Emily has been tracking her migraines for a long time, and has determined that each day there’s an 80% chance that a migraine will descend on her at about 2:00 pm, ruining the rest of her afternoon.
Emily has recently noticed that if she takes 400 mg magnesium in the morning, it’s much less likely she’ll have a migraine that afternoon. This isn’t a sure thing — she still gets migraines on days when she takes the magnesium — but it seems like it’s less than 80%.
One way for Emily to get some support for this hypothesis would be for her to run a simple AB self-experiment. She could take no magnesium for two weeks, then take 400 mg magnesium every morning for two weeks, and see if it makes a difference for her migraines. If she gets migraines 80% of the time in weeks where she’s taking no magnesium and only 40% of the time in weeks where she’s taking 400 mg magnesium, that seems like evidence that the magnesium is helping.
And it is evidence, but it’s on the weak side. Depending on how you slice it, the effective sample size here is two — just one fortnight with magnesium, and one fortnight without. You shouldn’t draw strong conclusions here for the same reason that you shouldn’t draw strong conclusions from a study with one person in the experimental group and one person in the control group. There’s just not that much evidence.
With small sample sizes, there are too many alternative explanations, it’s too easy to fool yourself. Maybe she started taking magnesium in the springtime, and the increased daylight is the real reason her migraines improved. Or she just started a new job two months ago, and it took her two months to stop grinding her teeth, which happened to align with the switch over to magnesium. Or her detergent manufacturer switched to a new supplier for fragrances. Or maybe her mailman’s cat, which she’s allergic to, ran away last week. It could be almost anything.
To account for these problems, Emily can just go ahead and get a larger sample size. She can use a random number generator to randomly assign days to either take magnesium or not take magnesium, and then follow that random assignment.
With the addition of these two small steps, she can now use a normal within-subjects experimental approach. Let’s imagine she finds that there’s an 80% chance of developing a migraine on days when she takes no magnesium, and a 30% chance of developing a migraine on days when she takes 400 mg magnesium. She can demonstrate this difference to an arbitrary level of precision, just by running the trial for more days.
Even if the difference is much more subtle — perhaps a 75% chance of a migraine with 400 mg magnesium and 80% without — with enough days, she can still show to an arbitrary level of confidence that the magnesium has the observed effect FOR HER, however small that effect might be.
This wouldn’t provide any evidence that magnesium will work for anyone ELSE’s migraines. But even if it doesn’t generalize at all to anyone else, Emily can get as much evidence as she wants that it’s really doing something for her. And that still helps the community, because it shows that the treatment works at least sometimes, for some people.
This is different from a traditional case study. Even though it’s looking at just one person, it uses experimental techniques. Compared to a traditional experiment, you sacrifice external validity (will this generalize to anyone other than this one person?) but you still get the same level of statistical rigor and you can still clearly infer causality.
And with this design, you should be able to use standard within-subjects statistical approaches. A sample size of just one is unusual even for a within-subjects study, but not entirely unheard of.
This approach is under-used in the internet research community (though Scott Alexander did one here and Gwern did one with LSD). Lots of people are online sharing tips and tricks on things they think might help their reflux/migraines/IBS/heart palpitations/executive function/etc. This is good, but it’s hard to know which recommendations are solid and which are just random chance.
If you run a within-subject self-experiment, you can do something incredible for your community. It may not help everyone, but you can demonstrate whether it works for you. Publish your null results too — if you suspect that caffeine triggers your reflux, but under close inspection the hypothesis falls apart, report that shit!
We should emphasize that N = 1 studies falsify a very specific kind of null hypothesis: that an intervention cannot work. If the intervention works for you, that just shows that the intervention can work.
It might not work for anyone else, and with N = 1 you have a much higher chance that one person will do something idiosyncratic that makes it look like the intervention was successful, when in fact it was the idiosyncratic thing doing all the work. For example, maybe on days you take magnesium, you always take it with a big glass of lemonade. It turns out the lemonade is what’s helping your symptoms, not the magnesium, and this wouldn’t be apparent from the data, because the lemonade and the magnesium are confounded.
If you want to go above and beyond, you can get a couple friends and do an even more compelling test with only a few people. As long as you all do multiple trials, your effective sample size from a statistical standpoint can still be arbitrarily large. With more people, we have greater certainty that there isn’t something weird confounded with the experimental variable (but never 100%). Every chronic illness subreddit should be generating research pods of 2-10 people, and testing the treatments they think are worth investigating.
Limitations
Even with better randomization, however, these designs still have a lot of limitations.
For a start, they’re limited by the speed of your research cycle. For example, repeated-measures studies won’t work very well for studying obesity, because people tend to lose and gain weight pretty slowly. It may take months to lose and then regain weight, so it’s hard to study weight gain with this method. If you have to randomize periods of months, it will take you a full year to get a sample size of 12. In comparison, headaches would be easier to study, since they come and go daily or even hourly, and you could randomize your treatment on much shorter timescales.
Worse, for some treatments we don’t know what the appropriate timescales will be. Let’s return to Emily and her migraines. If magnesium works on the order of weeks rather than days, she will have to randomly assign weeks rather than days, which means it will take seven times longer to reach an equivalent sample size. But how can she know in advance whether to use periods of days or of weeks?
If a cure is too powerful, or has long-lasting effects, that actually makes it harder to study. If magnesium cures Emily’s migraines for a month, she’ll have to wait a month between randomization cycles, and it will take her years to get a decent sample size.
Similarly, this kind of protocol may not be able to detect more complicated relationships. If Emily’s body builds up a reservoir of extra magnesium over time, this may be difficult to model and might throw off the clarity of the experiment. Or if her body gets more aggressive about clearing the excess magnesium from her system, the magnesium will have less effect over time, and will have even less effect on trial runs where she has multiple magnesium blocks one after another. These designs have a lot to offer, but they’re not going to get us very far in the face of genuinely complex problems.
Another downside of this approach is that Emily has already found a treatment she likes. Probably she would like to take magnesium every day and get as few migraines as possible, but to do this within-subjects self-experiment, she has to try going off the magnesium multiple times over the course of several months, to make sure it really works. We think it’s often worth it to know for sure, but it isn’t easy to stop a treatment that seems to be working.
Finally, the big limitation is that you can only use this approach if you’ve already identified a treatment that you suspect might work for you. If you’re sick and you don’t have any leads, this method can’t help you figure out what to try. It’s only good for testing or confirming hypotheses — it can’t give you any new ones, can’t narrow down a list of cures or triggers out of the huge number of things that might possibly be making you sick.

Interesting! I’d never thought about doing randomized trials on oneself.
LikeLike