The current model of nutrition science is that nutrition is a struggle of mind over body. You just need to find the discipline to completely ignore your instincts, to avoid what you enjoy and restrict all the stuff you like. The more you like it, the more you should probably restrict it. You should ignore and suppress the signals your body is sending you and do exactly the opposite instead.
What if we flip that on its head, and assume that your mind is silly while your body is wise? Notice what feels good, things you enjoy and respond well to, then ramp up those?
This seems to have worked well for both Elizabeth Van Nostrand and ExFatLoss (and his participants so far). Elizabeth eats all the watermelon she wants, and in her own words, her health is “obviously doing much better” than before. ExFatLoss loves cream, eats almost nothing but cream, and is currently down more than 50lbs.
Our potato diet came from a similar place. Seeing all the case studies where people lost a ton of weight did pique our interest. But we also just love potatoes, and we were kind of curious if we could eat nothing but potatoes and never get tired of them. Turns out, we pretty much can. Even after months of dedication, we still love potatoes. And so do many of our participants:
(16832193) I was quite surprised that I didn’t get tired of potatoes. I still love them, maybe even more so than usual?!
(57875769) My wife and I went out to eat with a friend and I expected to use today as a cheat day, but honestly potatoes sounded like the best thing on the menu so I ordered hash browns and french fries. The hash browns were very filling on their own so I didn’t eat many of the fries.
When it comes to chronic illnesses, most people try to find ways to avoid the pain. This is because pain bad, and no pain, good.
But we worry that avoiding pain is good in the short term but bad in the long term; penny wise and pound foolish.
If you’re worried that pizza makes you bloated, it’s good common sense to try to avoid pizza. But it’s bad science. Past a certain point, avoiding pizza tells you nothing. To learn something more, you have to bite the bullet.
Better to wait for a day when you feel great, no bloating at all, and then intentionally go and eat pizza, and see what happens. Or each afternoon you feel good, flip a coin, and eat pizza when it comes up heads. Do this a couple of times. If you do this, you should be able to see if pizza is really a reliable trigger for your bloating.
There are two reasons to do this. The first is — what is it about pizza that makes you bloated? If you can show that pizza is a trigger, you can start doing empirical splits. Buy the same pizza and flip a coin. If it’s heads, scrape off the cheese and tomato and just eat the bread. If it’s tails, toss the bread and just eat the cheese and tomato scraped off into a bowl. Which makes you bloated? If it’s the cheese and tomato, separate them and do the same thing.
In the old days, psychology was dominated by the school of behaviorism.
Behaviorism taught that mental states like thoughts and feelings are unworthy of study, and possibly don’t exist.
Behaviorists also thought that animals are born without anything at all in their brains, that the mind at birth is a blank slate, and that everything an animal learns to do comes from pure stimulus-response learning built up over time. Turns out, this is wrong.
At some point in the 1950s, a guy named John Garcia was irradiating Sprague-Dawley rats for his job at the U.S. Naval Radiological Defense Lab, like you do, when he noticed something weird. The rats who had been exposed to low levels of gamma radiation were eating and drinking less than usual, and groups that had been exposed to radiation the most times ate and drank the least.
Garcia thought that the rats might be learning to associate their food and water with the nausea from radiation exposure. After all, rats have no concept of ionizing radiation, so from their point of view, they were going about their day as normal when they suddenly started feeling nauseous for no clear reason. They might reasonably wonder if it was something they ate. In particular, he noticed that the rats wouldn’t drink out of the plastic bottles they were used to, but were happy to drink out of unfamiliar glass bottles. Garcia thought that maybe the plastic bottles gave the water a particular taste that the rats had learned to avoid.
So in a series of experiments, Garcia tried exposing rats to different kinds of stimuli to see what they would learn. He discovered two surprises that called the whole behaviorist concept into question.
First, he discovered that if a rat was exposed to radiation (making it nauseous) after encountering a new food, it would quickly learn to reject the food, even if the radiation came hours later.
This contradicted the understanding at the time of how conditioning worked — behaviorists thought that you had to present the unconditioned stimulus (nausea) immediately after the conditioned stimulus (the new food), or the animal wouldn’t learn to associate the two. But Garcia found that learning could occur even if the rat got sick well after eating a new food.
Rats would instantly associate nausea with whatever food they had most recently eaten, and had no problem doing so. If he made them sick after giving them Cheetos, they would learn to reject Cheetos forever. But the rats simply could not learn to associate their nausea with any other kind of stimulus. It didn’t matter if the stimulus was bright lights, or an annoying buzzer. No matter how many times Garcia flashed lights at them, the rats never learned to associate their nausea with the lights.
Everyone knows it’s mice that like cheetos, anyways
On the flipside, when he gave the rats electric shocks instead of exposing them to radiation, they would learn to be afraid of the lights and sounds. But no matter how many times he shocked them after eating, the rats would never learn to associate food or water with getting shocked.
This was another big pie in the face of behaviorism. Learning was supposed to be purely stimulus-response, and you were supposed to be able to teach an animal to do just about anything by pairing a behavior with the right reward or punishment. But Garcia’s rats seemed to be hard-wired to associate nausea (from radiation) with what they ate or drank, and similarly hard-wired to associate pain (from electric shocks) with what they saw or heard, and not to associate these things with anything else.
This was confusing to the behaviorists, but makes perfect sense if you think about evolution for even one second. In the real world, rats become nauseous when they eat spoiled food, so it’s important for a rat to associate nausea with things they recently ate. Any rat that doesn’t learn this will be dead, so eventually all rats are born prepared to make these food-nausea associations. Even though Garcia’s rats had been born in a laboratory and had never eaten a bit of ham left out in the sun for too long, they still came with an overwhelming bias to associate a feeling of nausea with whatever they most recently ate.
Similarly, pain is associated with sights and sounds, like the sight of an owl or the sound of a fox; or specific locations, like parts of the forest where predators are common. So rats are born ready to associate pain with things like weird noises or flashing lights. The idea that pain might be related to food, on the other hand, never crosses their minds.
…[cats’] lack of trainability apparently has an exception, Bradshaw states: food can trigger learning of powerful associations even hours after consumption. This would make sense as an anti-bad-food defense, but unfortunately, this is yet another maladaptation in the modern context: “…this mechanism occasionally has unexpected consequences: a cat that succumbs to a virus may then go off its regular food even after it has recovered, because it has incorrectly associated the illness with the meal that happened to precede it.”
More generally this is called conditioned taste aversion, and it occurs in most mammals — though maybe not vampire bats, since they eat only one thing that never spoils, and being put off their food would be a guaranteed death sentence.
(Some researchers did a version of Garcia’s study where they compared vampire bats with closely related species of bats that eat more than one thing, and while the other bats learned to avoid new flavors that were paired with nausea, vampire bats didn’t learn to associate new flavors with nausea when they were fed different kinds of flavored blood. Just imagine being that researcher on a first date; “Oh, what do I do at work? Yeah, I’m the guy who injects vampire bats with a 1% weight/volume lithium chloride solution to make them nauseous, it’s not much but it’s a living!”)
II.
Humans are also mammals, so we might have the same tendency. Maybe when we feel nauseous, or sick, or even just kind of weird, we assume it’s something we ate or drank.
Wikipedia thinks this is the case, claiming, “even something as obvious as riding a roller coaster (causing nausea) after eating the sushi will influence the development of taste aversion to sushi,” but doesn’t offer any citations. We suppose you could run this study on your own with a few sushi meals and a season’s pass to INSERT LOCAL THEME PARK.
People often suspect that their chronic illnesses have food triggers, different kinds of food or drink that will bring on an attack or generally make them feel like crap. But if our brains are hard-wired to pick out food-based explanations for feeling ill, maybe we tend to latch onto the idea of some food trigger causing our illness, even when food has nothing to do with it.
When our ancestors felt nauseous, it was usually because they had eaten the wrong kind of frog, so we come with a strong bias towards assuming that a random feeling of sickness is connected to something we ate. We don’t assume it has anything to do with the awesome glowing rocks we found in that sweet cave.
Such a cool rock, right? Oh hold on I have to lie down I feel terrible, must have been the goat’s milk I had for lunch
This worked well up until 3000 BC, but since then humans have discovered and invented lots of new things that can make you sick, most of which are not foods.
In general this should make us more skeptical of food triggers (and food-related triggers like packaging), especially if your chronic complaint is anything related to nausea, anything that feels like an illness, or anything digestive.
Food can still make you sick, and there are for sure some real food triggers out there. But the lesson here is that your instincts will tell you that your random sickness is caused by what you ate, even if it’s actually caused by something completely different. If you were one of Dr. Garcia’s rats, you would never have guessed that you were being hit with gamma radiation. You’d be all like, “it must be some chemical in those nasty plastic bottles.”
The biggest limitation of an N=1 experiment is external validity. If you run enough trials on yourself, you can show that some intervention does or doesn’t have an effect on you to basically any degree of certainty that you want. But this will never provide much evidence that the same intervention will have the same effect, or any effect, on anyone else.
People are all human and have roughly the same human biology, it’s true. In the higher animals, decapitation is more or less guaranteed to be lethal; people generally like eating sugar and hate eating asphalt. But once you move beyond the fundamentals of biology, most other bets quickly are off.
An unspoken assumption of the self-experiment discussion (including our posts on the subject) is that there are exactly two kinds of research — self-experiments, and large trials. These occupy the sample size slices of N = 1 and N ≥ 30, respectively. The self-experiment and case study are assumed to be a single subject; and with few exceptions, most people don’t trust a survey or RCT with anything less than 30 participants.
But there are two problems with this perspective. The first is that this is a false dichotomy. There isn’t a point where N = 1 turns into N = small, and there’s no sample size where you go from having a collection of case studies to having a trial. Going from N = 29 to N = 30 does nothing in particular, and there is no other threshold that stands out as being at all distinct (except N = 0 to N = 1, of course). A bigger sample size always means more information and better external validity, with no discontinuity.
The second problem is that if N = 1 is at all good (and we think that it is), then N of small has to be better.
Anything that is good with an N of 1 will be better with an N of 2-10. With N of small, you get more data, more quickly. One person doing random daily trials over the course of a week will create 7 data points. Three people doing random daily trials over the course of a week will create 21 data points. Small-group analysis is a little more complicated, but the data can be handled by a standard linear mixed model (here’s an example that involves dragons).
With N of small, you get more diversity of participants and more diversity of responses, quickly drawing the fangs from the problem of external validity. You will be able to get some sense of whether the intervention works differently for different people. If you have five participants, it will be easy to see if they are all responding the exact same way, if they are responding somewhat differently, or if some of them are having huge responses while others feel nothing at all.
The only question is one of cost. Because while the biggest limitation of N = 1 is external validity, the biggest benefit is that it’s cheap in important ways. With N = 1, you don’t need anyone’s permission to start your study — you can just go do it. You don’t pay any coordination costs, costs which are easy to miss up front but can be quite a drag if you’re not careful. These factors help make self-experiments cheap.
But we think scaling up is usually worth it — or at least, once you have some promising N = 1, scaling to N of small usually makes sense. It’s the logical next step. And since there’s no real distinction between a single case study, a small collection of case studies, and a trial of 100 people, it’s also the logical next step on the path towards an RCT or other large trial.
So while this series has focused on true N = 1 self-experiments, the real wins for the future may be in N = 2-10 studies where people grab a couple of friends and run a self-experiment together. Remember kids, friendship is the most powerful force in the universe.
And it’s not at all unprecedented, since this is how we approached our community trials; we looked at a couple of case studies, and then used N of small to do the pilot testing.
For the potato diet, we started with case studies like Andrew Taylor and Penn Jilette; we recruited some friends to try nothing but potatoes for several days; and one of the SMTM authors tried the all-potato diet for a couple weeks.
For the potassium trial, two SMTM hive mind members tried the low-dose potassium protocol for a couple of weeks and lost weight without any negative side effects. Then we got a couple of friends to try it for just a couple of days to make sure that there weren’t any side effects for them either.
For the half-tato diet, we didn’t explicitly organize things this way, but we looked at three very similar case studies that, taken together, are essentially an N = 3 pilot of the half-tato diet protocol. No idea if the half-tato effect will generalize beyond Nicky Case and M, but the fact that it generalizes between them is pretty interesting. We also happened to know about a couple of other friends who had also tried versions of the half-tato diet with good results.
We think that in all of these cases, N of small was much more convincing than N = 1 would have been. With two people, it’s much less likely that the effect is a fluke. Even if it works for one person and not for the other, that’s still evidence that we shouldn’t expect the effect to be entirely consistent; we should expect more ambiguity. And for something where the risks are unclear, like with potassium, two people going through without any side-effects is much more reassuring than one.
Peter has a bad reaction to melons. Every time he eats melon, he gets sick right away, and he often throws up.
We can say that Peter’s reaction to melon has low latency. When it happens, it happens right away. No waiting about.
Mark also has a bad reaction to melons. But because of a complex series of biochemical interactions, when Mark eats melon, he doesn’t get sick right away. He gets sick about three days (72 hours) later, when he suddenly starts to feel very ill, and then often throws up.
We can say that Mark’s reaction to melon has high latency. It happens, but it always takes a long time to kick in.
Peter and Mark have basically the same reaction to melon. Both have the same symptoms — nausea, sickness, and vomiting. Both reactions happen for sure every time — they are both equally reliable. The only thing that’s different is the latency.
b. Different and the Same
Though their reactions are nearly identical, Peter and Mark end up with very different experiences of their sensitivity.
Peter quickly learns that melon is a trigger. After all, he gets sick right away. He just makes sure to avoid melon and goes about his life with no additional air of mystery.
Mark, on the other hand, is plagued with random, crippling nausea. He sometimes gets sick, and it always seems to be for no reason. This is because it’s hard to remember what you were eating exactly 72 hours ago (for example, take a moment to try to remember what YOU were eating 72 hours ago). So for Mark, the connection is very obscure. He may never figure it out.
Both of these relationships would become equally obvious in a self-experiment. As long as you were tracking melon consumption and looking for relationships over a long enough time frame, you would see that Peter gets sick right after every dose of melon, and Mark gets sick exactly 72 hours after every dose of melon.
Perfect 100% reliability would make this pretty obvious once you noticed it. You don’t need a huge sample size to pick up on a relationship that is 100% reliable, which is why Peter quits melons after getting sick just a few times.
The big difference is whether the relationship jumps out at you or not. Low-latency relationships are obvious; the close proximity of cause and effect highlights the correct hypothesis and draws immediate attention to the relationship, where it can quickly be confirmed. Peter can just eat more melon and immediately get corroborating evidence if he wants to confirm his theory. The relationship is intuitive; you know it when you see it.
c. Cause and Effect
High-latency relationships are much harder to spot, even if they are equally reliable. The separation of cause and effect means that the connection may never come to mind.
To even be able to pick up on this in a self-experiment, you would have to know in advance that you should be tracking how much melon you are eating. And this is the hard part. The hard part is not demonstrating the relationship. At 100% reliability, that’s easy. The hard part is picking up on what to track.
This is somewhat in contrast to our normal concerns in research. Normally we worry about sample size and the quality of our measures. But Mark doesn’t need a big sample size. He doesn’t need any measures other than “got sick” and “ate melon”. All he needs is to consider melon as a possible cause of his nausea, and to consider looking for relationships with a latency of at least 72 hours. Easier said than done.
d. Reliability in Real-World Relationships
Of course, most real-world relationships are not 100% reliable. Few things work every time. But it’s concerning how a little latency can hide an otherwise blatant relationship, and it makes us wonder how many connections we all miss because of relatively small delays in onset.
Zero latency (eat melon, immediately puke) is easy to figure out. These relationships become obvious after just a few trials.
In comparison, 72-hour latency is very hard to figure out. Most people are not looking for relationships with such a long delay, and even if you were, you would be hard pressed to figure out the cause.
You can’t just keep a food journal and look 72 hours back — you don’t know how long the latency is, so you don’t know how far back to look! And if the latency varies at all (e.g. always between 60-80 hours later), it gets even harder.
This makes us wonder how much latency we can handle before connections stop being obvious. It may not take much. Coffee -> heartburn with an hour delay, that seems pretty doable. We think you would figure that one out pretty quickly. But with a four hour delay? Eight hours? Twelve? This would be much more difficult. It would start to look more like, “heartburn around dinnertime / going to bed, especially on weekdays”. That sounds hard to puzzle out.
Latency also makes it harder to get a big sample size. With a latency of less than 5 minutes, Peter can easily do eight trials (eat some melon and face the consequences) in a single day. Mark can’t do that. He has to wait 72 hours to get the results from his first trial, except it’s worse than that, because he doesn’t know how long he has to wait for the results to come in.
If he wants to make sure not to cross the streams, he needs to devote three whole days (though again, he doesn’t actually know in advance how much time he has to dedicate) to each trial, so he needs 3 * 8 = 24 days to do the same number of “eat melon and find out” trials that Peter can easily do in an afternoon, if he’s willing to get sick that much in a single day.
II. Half-Life
a. Creamer
Jo has a bad reaction to one of the additives in her office’s tiny cups of dairy creamer (henceforth: “creamer”). Every time she uses one of the tiny cups, she gets very tired about 30 minutes later. Fortunately, Jo’s kidneys happen to handle the additive really well, and two hours after she takes the creamer, she has cleared all of the additive out of her system, and stops feeling unusually tired.
We can say that the additive has a short half-lifein Jo’s system, and that the symptoms (fatigue) have a short half-life as well. They don’t stick around for long, things quickly go back to baseline.
Lily works in the same office and has the exact same reaction to the same additive in the office’s tiny cups of dairy creamer. Every time she uses one of the tiny cups, she gets very tired about 30 minutes later. But through a random accident of biology, Lily’s body doesn’t clear the additive from her system nearly as quickly as Jo’s does. The additive sticks around for a long time, and Lily keeps feeling tired all week. If she takes some creamer on a Monday, she’s just getting over it on Sunday afternoon.
We can say that the additive has a long half-lifein Lily’s system, and that the symptoms (fatigue) have a long half-life as well. They stick around for a long-ass time, and it takes forever for her to feel normal again.
b. Puzzling it Out
Much like a long latency, a long half-life makes this problem much harder to puzzle out, even when the two cases are otherwise identical.
Jo has it easy. If she comes to suspect the creamer, she has a lot of options. She can try taking creamer some mornings and not other mornings. She can try taking the creamer at different times of day and seeing if the fatigue also kicks in at different times. She can even take the creamer multiple times in the same day. Since the symptoms clear out after just two hours, she’s quickly back to baseline and is ready for another trial. If she wants to compare different brands of creamer to see if there’s a difference, she can get a pretty good sample size in a weekend. It’s easy for her to collect lots of data.
Lily has it really hard. If she comes to suspect the creamer, she is in a real bind, and most of the traps are invisible. If she tries taking the creamer some mornings and not other mornings, her results will be a mess, because as soon as she takes it one morning, she is fatigued all week. It will look like the creamer has no effect at all, since on days when she doesn’t take the creamer, she is still fatigued from any creamer she took in any of the previous seven days. A day-by-day self-experiment would show no effect, even though this is totally the wrong conclusion.
To detect any effect, Lily needs to test things in blocks of weeks, instead of blocks of days or hours. Each Monday, either take the creamer or not, and see how tired she is that week. But you can see how hard it would be for her to figure out this design — how is she supposed to know in advance that she needs to study this problem in blocks of a full week? She has a lot less flexibility; you might say that her research situation is much less forgiving.
Half-and-Half-Life
Even if Lily does pin down the right research design, it still takes her much longer to get the same amount of data. Randomly assigning creamer or no creamer each morning, Jo can get 28 data points in four weeks, which is enough data to detect a strong relationship if there is one. Meanwhile, in four weeks Lily would get only four datapoints, not enough to be at all convincing.
If the relationship is weaker (e.g. only a 50% chance of becoming fatigued), things are even worse. Jo can get a sample size of 100 or 200 days if she has to; it would be a pain, but she could make it happen. But for Lily to get a sample size of 100 weeks would take two years.
c. Thought it Worked for a While 🙂
Lots of people try something, feel like it works great, and then later when they do a more rigorous self-experiment or just keep trying it, they feel that the effect wears off. Must have just been excitement over trying a new thing.
For example, back in early 2020 Scott Alexander put out a report describing his experience with Sleep Support, a new (at the time) product by Nootropics Depot. His sleep quality isn’t great, so he decided to give this new supplement a shot, and reported miraculous results:
The first night I took it, I woke up naturally at 9 the next morning, with no desire to go back to sleep. This has never happened before. It shocked me. And the next morning, the same thing happened. I started recommending the supplement to all my friends, some of whom also reported good results.
“I decided the next step was to do a randomized controlled trial,” he says. To make a long story short, the RCT found no difference at all in any measure of sleep quality. “My conclusion is that the effect I thought that I observed – a consistent change of two hours in my otherwise stable wake-up time – wasn’t real. This shocked me. What’s going on?”
Scott chalks this up to the placebo effect, which is certainly possible. But another possibility is that Sleep Support did work great at first but was no longer detectable (for whatever reason) by the time he set up the RCT. Obviously if this is true, it would be hard to study; but it does perfectly match Scott’s experience, which is otherwise (as he says) shocking and somewhat confusing.
If you have any experience with chronic illness or biohacking or anything similar, then you know that “thought it worked for a while” is a very common story. When this happens, the assumption is usually that you were fooling yourself the first time around. But consider:
Vitamin C cures scurvy, so if you have scurvy, the first few doses of vitamin C are great! But after that, vitamin C has basically no effect, because you no longer have scurvy. You have been cured. Looking at this data (huge increases in wellbeing on the first few days, but after that, nothing), the research team concludes that the original reports were somehow mistaken.
No! It’s just that the vitamin C helped and then it had done all it could! It had a huge effect! That effect was just all up front!
This exact scenario should pop up all over the place. If you are iron deficient, the first few doses of iron will have some effect. After that, they will have no effect. If you are B12 deficient, the first few doses of B12 will have some effect. After that, they will have no effect. Et cetera.
This is because the body is able to keep reserves of all of these substances. As long as you’ve been getting enough vitamin C, you can go for 4 weeks without any vitamin C at all before you start getting scurvy (in reality it usually takes more like 3 months, because most people don’t go entirely cold turkey on vitamin C). Same goes for iron and B12 — your body is able to keep reserves of these substances, so as long as you get enough, you should be set for a while.
To put this back in the terms of this essay, we would say that these positive effects have a long half-life. Positive effects with a long-half life face exactly the same issues as negative effects with a long-half life — you have to make sure you take the half-life into account when designing a study, and use long enough study periods, otherwise your data will be confused and misleading.
This same point applies to a lot of treatments, actually. Assuming you have an infection, antibiotics will show a big effect up front and then nothing after that. But we don’t take this to mean that antibiotics have no effect, oops we thought it worked for a while, guess we were wrong.
This isn’t a problem for things with no reservoir. For example, as far as we can gather, zinc isn’t really stored in the body long-term. So most effects of zinc will (probably) have a short half-life. If you need more zinc, you can just take it on a given day and see the effects.
Supplementing anything with a large reservoir (or other positive effect with a long half-life) may not be suitable for a self-experiment, because it will show a strong effect in the first few days and no effect after that. Aggregated over 30 days or whatever, this will look like no effect or a weak effect. Clearly this is the wrong interpretation.
And the longer you run the self-experiment for, the smaller the effect will appear! If you do a 10-day self-experiment with antibiotics, and they have an effect on the first two days, then you will find that this looks like 2/10 days show an effect, which will probably average out to a small effect. But if you kept going for 100 days, you would see that 2/100 days show an effect, which will average out to basically no effect at all.
This is the opposite of our normal assumption about sample sizes, that a larger sample size will always get us a more meaningful, accurate estimate. This assumption simply isn’t true if we’re dealing with a treatment that has a long half-life.
So consider the half-life of positive effects too.
III.
Broadly speaking, triggers have some delay in the onset of their symptoms, and those symptoms stick around for some span of time.
Having a high latency or a long half-life makes a relationship much harder to notice, and harder to study. Having both, it gets even worse.
Perhaps Bob is allergic to dairy, or whatever. It gives him hives, but with a latency of two days, and they persist for four days. Bob will be walking around with random hives, and not much hope of finding out why.
He might come to suspect the true cause if he happens to cut out dairy for a while and the hives go away for good. But if someone challenged him on this — or if Bob, being a good scientist, decided he wanted to run a self-experiment to demonstrate the hive-causing effect — he would be hard pressed to get convincing formal evidence.
Bob wouldn’t know in advance to look for a latency of two days and persistence of four days. If he did something reasonable, like randomly assign each day as dairy or non-dairy, the results would look like zero effect. On most days when he took no dairy, he would have hives anyways, because of the long half-life. On most days when he did take dairy, he would also have hives, because they stick around so long. The few “no hive” days would be in the random periods where he hadn’t had any dairy several days ago; but those days might well be days when he was assigned to drink dairy. So it would look like a wash, even though it’s actually a very reliable relationship.
Bob would have to do something that seems totally unreasonable, like structure the trial in 6-day segments to account for these delays. If he did this right, the 2-day wait and 4-day stay would become entirely obvious. But how is he supposed to know in advance that he has to use this totally weird study design?
People like to argue about whether obesity is a disease. Does it require treatment, or is it more of a social problem? But obesity isn’t a disease. It’s clearly a symptom.
Think about it like this. Fatigue is a symptom, and it’s a symptom of many things. Fatigue can be a symptom of everyday decisions — you can be fatigued because you stayed up until 3 AM last night playing Octodad: Dadliest Catch. It can be a symptom of substances, like alcohol or Benadryl. It can be a symptom of conditions, like anemia or concussion. And fatigue can be a symptom of diseases, like mononucleosis, Parkinson’s, or lupus.
Similarly, a person can be obese for a number of different reasons. Obesity is a symptom of many different conditions. You can be obese because of a brain injury. You can be obese because of a thyroid issue. You can be obese because you’re taking a drug like haloperidol or olanzapine. And while there’s still a lot of dispute over the source of the global obesity epidemic, you can be obese because of whatever cause(s) are causing that.
II.
Things get confusing when you try to treat a symptom like a disease.
Think about fatigue. If your friend is tired from playing video games until the wee hours of the morning, the correct treatment is for them to play video games while pretending to fill out spreadsheets at work, like a normal person. If they’re fatigued from drinking merlot or taking Benadryl, the only real option is to have them wait until the drug wears off (or take an upper, but that’s not really recommended). If they’re anemic, then they need to get more iron. Et cetera.
Similarly, we don’t know how to treat the general obesity we see in the obesity epidemic. But we do have treatments for obesity caused by thyroid disorders or brain tumors. And we shouldn’t be shocked if treatments that work for obesity caused by thyroid disorders don’t work for the obesity caused by brain tumors, or don’t work for the widespread obesity we see today.
Because a symptom can have many different causes, just looking at the symptom won’t always tell you the cause. And if you don’t know the cause, then you may not know the right treatment, because you don’t know the etiology; you don’t know how the cause connects to the symptom, at what points you can intervene, and what kinds of interventions might be helpful.
This is pretty bad — even when there’s a finite list of possible causes, it’s hard to look at a symptom and figure out which of its causes are responsible.
III.
Many chronic illness symptoms are nonspecific. Per Wikipedia:
Nonspecific symptoms are very general and thus can be associated with a wide range of conditions. In other words, they are not specific to (not particular to) any one condition. Most signs and symptoms are at least somewhat nonspecific, as only pathognomonic ones are highly specific. But certain nonspecific signs and symptoms are especially nonspecific and especially common. They are also known as constitutional symptoms when they affect the sense of well-being. They include unexplained weight loss, headache, pain, fatigue, loss of appetite, night sweats, and malaise.
This means that people who are diagnosed with the same chronic illness could have similar experiences, similar symptoms, with entirely different causes. If you have headache/pain/fatigue, you might reasonably assume that someone else with headache/pain/fatigue has the same illness, and that it was caused by the same thing. You might assume that the same treatments will work for both of you, that your illness would have the same cure.
But headache/pain/fatigue are all nonspecific — they can all be caused by a zillion [sic] different things. So someone who shares your exact symptoms may have the exact same experience but for totally different reasons. If this is the case, the treatments that work for one of you may not help at all for the other.
(Even worse, palliative treatments will tend to work for both of you, since they treat the symptoms directly, and this will make the two conditions seem even more similar. But curative treatments that work for one of you won’t work for the other, since your conditions have different root causes.)
Let’s consider migraines. Migraines can definitely be caused by hormones. Some people have migraines only during certain parts of their period (about 7-14% of women, according to Wikipedia), or only when pregnant. Migraines can also be caused, or at least partially caused, by triggers like stress or certain foods.
But there are also people who get random mystery migraines on a regular basis, with no apparent trigger. Presumably these are caused by something, but it’s not something obvious like stress or hormonal cycles or being pregnant. So clearly migraines are a symptom, not a disease — they can be caused by several different things.
All this to say that finding the “cause” of migraines may be the wrong framing. There may be no more single cause of migraines than there is a single cause of car accidents. Some accidents happen because the driver wasn’t paying attention (and many people think of this as prototypical). But some accidents happen because the road is icy. Some accidents happen because the driver had a seizure and lost control of the car. Some accidents happen because the vengeful spouse of the man you killed in El Paso 15 years ago has finally tracked you down and cut your brake lines.
Not that we would know anything about that! We’ve never been to El Paso, officer, we swear.
There is no single cause of car accidents. They are more like a symptom. All car accidents look much the same — broken glass, tire marks, people yelling. Most car accidents have similar proximal causes — unless it was an intentional ramming, it happened because someone lost control of their vehicle. But despite these apparent similarities, car accidents can have wildly different original causes. They happened for different reasons.
Consider chronic fatigue syndrome (CFS). Most people assume that CFS is a disease, and that everyone with CFS has it for the same reason, that there is a single cause. But maybe CFS is more like a symptom (obviously “syndrome” is literally in the name). If so, the search for the “cause” of CFS is a mug’s game, since it is caused by many different things. If you go around assuming there is one cause of CFS, one etiology, you are going to end up very confused.
Or consider irritable bowel syndrome (IBS). Most people seem to be aware that IBS is not really a single diagnosis, and probably is a term used to describe all sorts of different, unrelated things. E.g. “Some people just have trouble with their stomachs. When they have trouble and we don’t know what is causing it, we just call it IBS. So you have IBS.” Even so, the label kind of implies that there is a similarity of some sort, and suggests that maybe there will be some similarity of treatment and of cure. But this may be misleading.
If nothing else, the shared label means that all these people are likely to end up in the same groups or the same communities “for people with IBS”. If someone makes a post like “this treatment cured my IBS”, you can be sure other people will respond with, “well it didn’t cure *my* IBS”. This is guaranteed to be the source of a lot of confusion.
We think that most unsolved chronic illnesses are probably like this — most of them are probably different diseases with different causes that happen to look very similar.
Compare it to the anthropic principle if you like — diseases that present in a consistent way and have a single cause are easy to figure out, so they tend to be cured and don’t tend to be on the list of unsolved chronic illnesses. But diseases where a number of very different causes present very similarly will be quite hard to figure out, and are likely to remain mysterious for a long time. So things that are unsolved and have been unsolved for a while are more likely to have multiple causes.
(Though even simple illnesses with precise single causes, like scurvy, can be devilishly difficult to figure out, so take this argument with a grain of salt.)
IV.
Single-subject (aka N=1) research can be really powerful. But when it comes to cases like this, you have to be very careful. Even if you do a very rigorous single-subject experiment, and provide strong evidence that some treatment works for you, you’ve only really provided evidence that it works FOR YOU. It may not work for anyone else.
If the treatment that works for you doesn’t work for most other people with your diagnosis, that’s actually somewhat informative. We can see why some people would find it discouraging, but it suggests that the illness you have “in common” is actually two different illnesses, or at least two substantially different presentations. That means it gets us one step closer, a small step but a step even so, to figuring out what is going on with your illness, and maybe getting a cure or treatment for everyone.
If you end up with Treatment A that works for 20% of people with your condition, and Treatment B that works for 50%, and there’s basically no overlap, you’re off to a great start. You can start looking for anything that the Treatment A people have in common that’s never found in the Treatment B group, and vice-versa. If you find something (“holy cow, everyone who liked Treatment A has Irish heritage!”), you can start directing people to try the treatment that’s most likely to work for them.
Even if you find nothing in common within the groups, you’re still in good shape. There are only two treatments, and we know that Treatment B works for more people. Newcomers can start by trying B, and if that doesn’t work, they can try A next. If neither work, then they are in the other 30% with no discovered treatment. But it’s still progress in general, and you can start putting your efforts towards finding treatments C, D, E, etc.
It may be tempting to jump ahead and start looking for differences now, before we have treatments that distinguish between various groups, and there is some merit in this idea. If we find that half of people with IBS tend to have bloating with no reflux, and the other half tend to have reflux with no bloating (or whatever), that’s a pretty interesting sign, and will probably end up being useful.
But this approach doesn’t usually seem to work.[1] Probably this is because clustering by symptoms isn’t useful; or when it is useful, it will already be obvious. Different causes can present with identical symptoms, as we’ve been discussing. But IDENTICAL causes can also sometimes present with DIFFERENT symptoms! There’s no royal road, no way to cut this knot for sure. You just have to be careful.
The real enemy here is the confusion (lit. fusion together of different things; “(transitive) To mix thoroughly; to confound; to disorder.”). Talking about “having CFS” or “having IBS” is handy, but when it comes to diagnostics, more detail is better. You may be surprised to discover that someone with the same diagnosis as you has almost nothing else in common. And even when you have every symptom in common, don’t confuse this for a common cause. Your friend may also have migraines, but don’t be shocked when the thing that worked for you doesn’t work for her.
Remember that car crashes all have similar presentation. In true diagnostic fashion, they usually show three or more of the following symptoms: broken glass, injured driver(s), skid marks, bent fenders, police on scene, plastic debris on the road, etc. Take two Geico and call me in the morning.
it’s ok, this lizard is a doctor
If you only did an analysis of symptoms, you might think that all car crashes have the same cause. An analysis of symptoms would suggest just one group. But we know that’s not the case — car crashes can happen for many different reasons, and even car crashes with very different causes will usually have very similar symptoms.
Maybe if you are a genius detective and you know just what to look for, you can tell them apart — maybe a car crash caused by a seizure will show signs of uncontrolled driving well before the point of impact, while a car crash caused by excessive speed will have longer, straighter skid marks on the blacktop. But you certainly won’t be able to discover the different causes of car crashes by going down a checklist of “was there broken glass?”, “were there skidmarks?”, “were the drivers injured?”, etc.
If you add in criteria like “how long were the skidmarks?” you might get closer. But you’d have to understand the causes well enough to add that question in the first place.
ENDNOTES:
[1]: If you know of any examples of looking at a disease, looking for patterns in its symptoms, and finding that it is really two diseases (or something similar), we’d be interested to hear about that, since we can’t think of any examples where this approach has worked.
Many chronic illnesses are much more common in women than in men. IBS is about 2-2.5 times more common in women than in men; migraines are about 2-3 times more common; chronic fatigue is about 4 times more common.
This is pretty weird, and more than a little mysterious. And it’s doubly weird that the ratio is pretty similar — each of these examples is about 3 times more common in women than in men.
Normally this gender gap, if it is addressed at all, is written off as a biochemical difference (e.g. here). But another possibility is that gender is just a proxy for body size (e.g. here). If some chronic illnesses are caused by exposure to irritants, heavy metals, or other contaminants, smaller people will generally have more of a response to the same level of exposure, and women on average are smaller than men.
If this is the case, it should be possible to detect if gender is a proxy for body size in some chronic illnesses. If body size is what really matters and gender is just a proxy, larger-than-average women will be underrepresented and smaller-than-average men will be overrepresented. Basically, once you know someone’s height and weight (and maybe % body fat), their gender shouldn’t give you any further information about their likelihood of getting sick.
II.
We can show this with some simulations.
Here’s a simulation of 10,000 men and 10,000 women. The men have an average height of 69 inches with a standard deviation of 3 inches, and the women have an average height of 64 inches with a standard deviation of 3 inches.
Let’s start by seeing what things look like if the greater prevalence of women is the result of something like hormone levels, and body size has nothing to do with it. In this case, the men all have a 1% chance of getting the illness, and the women have a 3% chance. Height doesn’t factor in at all. So when you look at the distribution of heights of men and women in the group of people with the chronic illness, it looks something like this:
As you can see, three times as many women have the illness as men do, but otherwise the distributions are quite generic. These are basically just subsets of the distributions for each gender. They should be normally distributed and should generally look similar to one another, except that there are more women than men and the two groups have different average heights.
Now in comparison, we can consider what the data would look like if gender is just acting as a proxy for height, and there are more women with chronic illness only because they are shorter on average.
Here’s another simulation of 10,000 men and 10,000 women, with the same distributions for height. Without getting into the exact model,[1] this is what it looks like if height is the only thing that determines if you get sick, and shorter people are much more likely to get sick:
Again we see that there are about three times more women than men, even though this time, gender doesn’t have a direct effect. In this simulation, height is the only thing influencing who gets the illness, but the difference in average height is enough to make it so that there are three times as many women as men.
While it’s not clear from just eyeballing the distributions, there are signs in the data that height is driving this difference. For example, about 1% of women are 70 inches or taller in the height-based simulation (compared to about 2.2% in general) and about 9% of men are 63 inches or shorter (compared to about 2.2% in general). This seems like a clear sign that height is the actual thing that determines who gets sick.
III.
Since we don’t know what the real-world dynamics would look like, it’s not clear what you would see in real-world data. It could just be that people with the chronic illness would be shorter on average than people without — American women are about 64 inches tall on average, so it would be interesting if the average height on a chronic illness subreddit was just 61 inches (though you might want to account for age and ethnicity). If the effect was strong or nonlinear enough, there might be a noticeable skew in the data instead. Or you might see the underrepresentation of larger-than-average women and overrepresentation of smaller-than-average men that we describe above.
You could conceivably detect this kind of difference with normal survey methods, as long as you got a large enough sample size. To our mind, evidence that height (or possibly weight, you would want to collect both) explains why women are much more likely to have a chronic illness would be evidence that the chronic illness in question is caused by some kind of contaminant, since other causes shouldn’t be so sensitive to body size. If anyone wants to help collect this data for their community, please contact us.
[1]: The probability of a simulated person getting sick was proportional to 82 inches minus their height in inches, cubed. That is to say, in this model someone who is 56 inches tall was 17,576 times more likely to get sick than someone who is 81 inches tall. These numbers mean nothing, we pulled them out of our ass.
Our psychology is focused on behavior. We focus on behavior because we want to figure out what actions we can take to influence the world around us. But a focus on our actions can also make us superstitious.
The classic example is from a BF Skinner study, where he put a bunch of pigeons in a box and dropped in food at random intervals. Instead of realizing that the food drops were random, the pigeons assumed that they were somehow responsible and tried to figure out what they had done to make the food appear.
Whatever they were doing at the time the food dropped, they tried again. A pigeon who had just turned counterclockwise when the food arrived would turn counterclockwise again and again. When more food eventually did arrive, the counterclockwise-turning was validated. “The experiment might be said to demonstrate a sort of superstition,” wrote Skinner. “The bird behaves as if there were a causal relation between its behavior and the presentation of food, although such a relation is lacking.” [1]
Compare this to a rat confronted with a set of buttons, trying to figure out which of the buttons give food and which give painful electric shocks. Unlike the pigeons, the rat is faced with a deterministic system where her actions lead directly to reward and punishment, so her focus on behavior is justified and leads to a correct understanding of the system. The pigeon is faced with a random system where his actions have nothing to do with the arrival of food, so his focus on behavior is pointless and leads only to superstition and confusion.
so cute though!
II.
We worry this is a common problem in chronic illness. Let’s say that Mary develops chronic fatigue syndrome (CFS). She is proactive and wants to solve the problem, so she comes up with a plan of 26 different treatments, which we’ll call A, B, C, D, and so on. Maybe A is “cut out dairy”, B is “walk 20 minutes every day”, etc. but the specific plans don’t really matter. She starts implementing each plan for two weeks, first plan A, then plan B, etc.
But Mary is working from the wrong assumption. She thinks her chronic fatigue comes from something she’s doing or not doing. In short, she thinks it comes from her behavior. This is a common assumption because our psychology is focused on behavior — we look for things we are doing right or doing wrong. But what really happened is that last month she bought a bag of rice that was grown in a field that was contaminated with cadmium, and developed low-level cadmium poisoning, which is entirely responsible for her chronic fatigue. Cutting out dairy or walking to the corner store won’t do a thing, because the cadmium is the only cause of her illness. None of the interventions she has planned will help.
But the cadmium is slowly being cleared from her system by natural means at the same time as she works her way through the 26 treatments. What happens is this: Mary reaches treatment L (“take omega-3 supplements”) just as the cadmium in her system drops below critical levels, and Mary is immediately “cured”.
Since her symptoms stop almost immediately after starting treatment L, Mary assumes that the omega-3 supplements are what cured her, and continues taking them indefinitely. In reality, the omega-3 supplements do nothing for her — as long as her cadmium levels are low, she doesn’t have CFS, and if she ever gets exposed to high enough levels of cadmium again, her chronic fatigue will come right back.
III.
What Mary should do is she should run a self-experiment with the omega-3 supplements. She should randomly assign some weeks to be on omega-3 supplementation, and some weeks to be off. If she did this, she would quickly find that the omega-3 makes no difference to her chronic fatigue.
It’s understandable why she doesn’t try this — she is worried that if she stops taking the omega-3, her chronic fatigue will come back, and she doesn’t want to risk it. Also, we suspect she wants a world that makes mechanical sense (“I just needed to take more omega-3”) rather than a world where she randomly gets sick and there’s nothing she can do to stop it. It’s hard to blame her for that.
This is how the focus falls on behavior and misses hidden variables. By “behavior”, we mean actions that are directly under people’s control. Eating more or less of something, getting up earlier or later, trying more or different kinds of exercise, and so on. By “hidden variables” we mean essentially any variable you wouldn’t normally think of, especially one not connected to your actions. For example, heavy metals in your drinking water, additives in your food, viruses you contracted from your friends, air pollution from forest fires hundreds of miles away, mold in your ceiling, or things you’re exposed to at work.
Most of these hidden variables can be influenced by your actions, but they’re not the kinds of behaviors that come to mind. You can always quit your job, but for most people, that doesn’t come to mind as a possible treatment for their illness. You can cut out spinach or dairy, because “eat less dairy” is psychologically simple — but “consume less sulfites” isn’t a clear action for most people because “foods with sulfites” isn’t a category to most people. They may not always know which foods contain sulfites, and they may not know what sulfites are.
Does this look like the face of mercy?
IV.
This is what chronic illness looks like for Mary as an individual. At the group level, things look somewhat different.
If a chronic disease is caused by a hidden variable (like cadmium randomly being in some foods but not others), you should see something like this: People get sick for apparently no reason. They all try many different treatments, and most treatments don’t seem to work for anyone. Sometimes a treatment will seem to work for a bit, but then it will unexpectedly stop working. Whenever you feel like you start to get a firm grip on things, all the rules you learn go out the window. However, there are many individual stories of trying some new treatment and suddenly being cured. Unfortunately, the cures in all of these stories are entirely different treatments, and the cures that work for one person never seem to work for anyone else.
And this does sound like what we see in many chronic illnesses, which makes us suspect that some chronic illnesses are being caused by a hidden variable. It could be contamination in food, water, or air, like our hypothetical Mary’s experience with cadmium. But it could also be any other unexpected variable that doesn’t have to do with personal behavior. For example, it could be the result of a virus, or an allergy to something in your household, or a curse put on you by the local witch. When taken as a group, chronic illness communities look exactly how we would expect them to look if the illnesses were caused by some hidden variable, and that makes us suspect that they are caused by some hidden variable.
Naturally this makes us wonder if there is any way to figure out what these hidden variables might be, assuming you believe they exist. The fact that they are hidden does make it inherently tricky, but we have a couple of ideas, here they are.
TRY BIG ELIMINATIONS
Your chronic illness may be triggered by something in your environment (your home, work, local food, local water, etc.). To test this, you can change as much of your environment as possible all at the same time, for example by taking an extended trip to Nepal.
If you start feeling better or your symptoms disappear, this strongly suggests that something in your home environment is causing your illness. If you don’t feel any better, it suggests that your symptoms 1) aren’t caused by your environment, 2) are caused by elements of your environment that you brought with you (e.g. your clothes, your shampoo), or 3) are caused by elements of your environment that are common to both your home and Nepal (car exhaust?).
Your chronic illness might also be triggered by something you eat. To test this, you can change as much of your diet as possible all at the same time, for example by trying the potato diet, where you eat essentially nothing but potatoes. The potato diet is good because potatoes are simple, contain no additives, and are more or less nutritionally complete. Many people can survive happily on nothing but potatoes, salt, water, and hot sauce for up to four weeks (we have good data on this!).
If your symptoms disappear or get better, this strongly suggests that either you had some deficiency that the potato diet fixed, or something in your normal diet is causing your illness. If your illness is just as bad as ever, it suggests that either your symptoms aren’t caused by your diet, or are caused by elements of your diet that are also in the potato diet.
Neither of these approaches will tell you what is causing your illness, but both have the potential to narrow things down enormously. If you go to Finland for a month and your migraines stop three days in and don’t come back until you get home, that’s pretty clear evidence that something at home is causing your migraines. You don’t know if it’s your laundry detergent, your well water, or something at your job, but you can take steps to narrow it down further, and you can stop worrying about your diet so much.
Similarly, if you try the potato diet for a month and your executive function issues disappear, you can stop worrying about fumes from your boiler and can try to figure out what part of your diet is giving you brainfog.
Even a null result is informative. If you go on the potato diet for a month and your migraines carry on as normal, that’s a pretty clear sign that it’s not something in your diet, and you should look elsewhere.
Some people find this approach surprising, because scientific investigation usually involves isolating a small number of variables and putting them under tight control. This works fine when you have a small number of variables to start with, or you know which variables you’re interested in. But in the search for hidden variables, there are a nearly infinite number of things that could be the cause of your illness. We need a technique that lets us rule out lots of theories at once, so doing these big splits can be extremely productive.
There’s a classic genre of logic puzzles often called balance puzzles. In these puzzles you have several coins, one of which is lighter than all the others, and you have to use a balance scale to find the light coin in the smallest number of weighings. The way you solve these problems is by splitting the coins into groups and comparing the groups directly. If you split the coins into two groups and the group on the right weighs less than the group on the left, the light coin must be in that group.
spoilers
Consider a version of this puzzle where there is an illuminated lightbulb and a row of 1,000 switches. You want to find the switch that controls the lightbulb, but you don’t know which it is. You could go down the row of switches and try them one by one, but this would probably take you several hundred steps. On the other hand, if you have some kind of opportunity to flip a bunch of switches at once, that can narrow things down really quickly.
Let’s say that half the switches are red and half are blue, and you can flip all the switches of a single color at once. If you flip all the red switches and the light goes off, then the master switch must be red. If you flip all the red switches and the light stays on, then the master switch must be blue. Either way, you now have only 500 switches to try.
This is the same situation we’re in with chronic illness, except that there are something like 1,000,000 switches on the wall, and in some cases the lightbulb might be controlled by complicated interactions between multiple switches. It still makes sense to toggle big groups of switches all at once when you can, because that can narrow things down drastically.
One limitation of this approach is that it’s only really good at finding triggers. If you’re suffering from an iron deficiency, big eliminations probably won’t help find that.
The other limitation of this approach is that it’s not always clear how long you have to eliminate things for. Do you need to eliminate the mystery trigger for a week? A month? Longer? Ideally we could send you to Nepal for a year, or put you on the potato diet for a year, but in reality this won’t be practical for most people.
If Mary is getting poisoned by cadmium, and it takes two months to clear all the cadmium from her system, then going on a restrictive diet for only one month won’t help. But the problem is, she can’t know this in advance. How is she supposed to know about the clearance rate when she doesn’t even know what’s poisoning her?
So we’re stuck with an asymmetry. If one of these eliminations helps you, that narrows things down quite a bit. But if they don’t help you, then it’s more ambiguous. Maybe the half-life of whatever is making you sick is just too long. Still, it seems like it would be worth trying.
TRY SOME LIKELY VARIABLES AT RANDOM
Another possibility is to just try various things and see what works. This is grasping in the dark, but we can still do a lot to cover our bases.
For example, there are a finite number of vitamins. “Vitamin deficiency” is a plausible type of hidden variable, so you could just cycle through all the vitamins and see if any of them happen to be an immediate cure. It seems unlikely that you will get this kind of miracle result, but vitamins are pretty safe so the risk is very low, and you could at least check “vitamin deficiency” off your list.
Similarly, there are a finite number of elements. Some of them, like iron and potassium, are necessary for human health. You could try supplementing these and see if that treats your illness. Other elements, like lead and mercury, are known to be bad for your health. You could try getting blood and/or urine tests, or testing your local water supply, and see if you have higher exposure to any of these known toxins.
Again these are all shots in the dark, but they’re all plausible variables that could be affecting your health. If it turns out your blood mercury levels are way higher than normal, that would be good to know.
You could also try to hit your illness with some generic treatments, basically anything where the name starts with the prefix “anti-”. If you can convince your doctor, you could maybe get them to put you on a broad-spectrum antibiotic (in case your chronic illness is bacterial), antiviral (in case your chronic illness is… etc.), antifungal, anti-inflammatory, or antihistamine. This is a little more risky, but there’s some chance your chronic illness might be fungal and this is one of the only ways you would ever find out.
This broad-spectrum approach will generally be better for finding deficiencies, but in some cases it might also help identify triggers.
GET RID OF YOUR BLOOD
Haha, but no, seriously. Donating blood is easy, safe, and it’s a nice thing to do for your community. You might save a life. And if there’s something nasty building up in your blood, you might be able to get rid of some of it. There’s already some evidence that donating blood can reduce your serum PFAS levels. Maybe it can clear some other things from your system.
Again, this is a pretty blind approach. It probably won’t work for most people. It may not work for anyone at all. But if you donate blood and your symptoms immediately get better, that would be pretty interesting, right?
V.
In the beginning, we’ll be taking shots in the dark. People will try dozens of things with little or no success. This will be quite frustrating.
But the hope is that eventually, we will start to get our bearings. If a couple people with chronic fatigue find that they have high levels of cadmium in their blood, then other people with chronic fatigue will want to check their cadmium levels before trying other interventions. Conversely, if a couple dozen people with chronic fatigue check for cadmium and find nothing, checking for cadmium should be moved lower down on the list for chronic fatigue.
Depending on the success of this approach, you can even imagine this being somewhat formalized. Someone could make a centralized list of things to try or to have tested, and people could report what they had tried and whether it worked out. Tests that seem to be helpful could be moved up in the rankings so people could know to try them first; tests that don’t seem to help people could be moved down and left for the last ditch attempt.
Will this work at all? Who knows, but it seems like it’s worth trying. And at the very least, we may be able to rule out some hypotheses. After all, if we can establish that it’s none of the things on this list… then what the hell is it?
Endnotes
[1]:
“A pigeon is brought to a stable state of hunger by reducing it to 75 percent of its weight when well fed. It is put into an experimental cage for a few minutes each day. A food hopper attached to the cage may be swung into place so that the pigeon can eat from it. A solenoid and a timing relay hold the hopper in place for five sec. at each reinforcement.
If a clock is now arranged to present the food hopper at regular intervals with no reference whatsoever to the bird’s behavior, operant conditioning usually takes place. In six out of eight cases the resulting responses were so clearly defined that two observers could agree perfectly in counting instances. One bird was conditioned to turn counter-clockwise about the cage, making two or three turns between reinforcements. Another repeatedly thrust its head into one of the upper corners of the cage. A third developed a ‘tossing’ response, as if placing its head beneath an invisible bar and lifting it repeatedly. Two birds developed a pendulum motion of the head and body, in which the head was extended forward and swung from right to left with a sharp movement followed by a somewhat slower return. The body generally followed the movement and a few steps might be taken when it was extensive. Another bird was conditioned to make incomplete pecking or brushing movements directed toward but not touching the floor. None of these responses appeared in any noticeable strength during adaptation to the cage or until the food hopper was periodically presented. In the remaining two cases, conditioned responses were not clearly marked.
The conditioning process is usually obvious. The bird happens to be executing some response as the hopper appears; as a result it tends to repeat this response. If the interval before the next presentation is not so great that extinction takes place, a second ‘contingency’ is probable. This strengthens the response still further and subsequent reinforcement becomes more probable. It is true that some responses go unreinforced and some reinforcements appear when the response has not just been made, but the net result is the development of a considerable state of strength.”
Single-subject or single-case research designs date back to at least the 1980s — though as you can see from the sparse Wikipedia page, they haven’t gotten that much attention. While the idea of single-subject research is good, the execution tends to be crap.
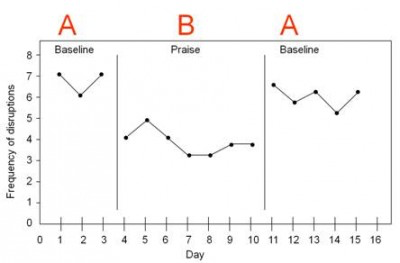
The simplest single-subject design is the “ABA” design, where you have a few control days (“A”), a few days on the treatment (“B”), and then you go back to the control (“A”). See for example this figure from the University of Connecticut:
In this case, we can see that “frequency of disruptions” (from a target student) is high in the first baseline A block, goes down for a while in the B block (“praise”), and goes back up when they switch back to A.
The ABA design is better than nothing. It’s better than a case study, because at least there’s some experimental control. But it just doesn’t give us all that much information. They have 15 days of data, sure, but only three phases. This is really more like a sample size of three (not that a sample size of 15 is all that much more compelling).
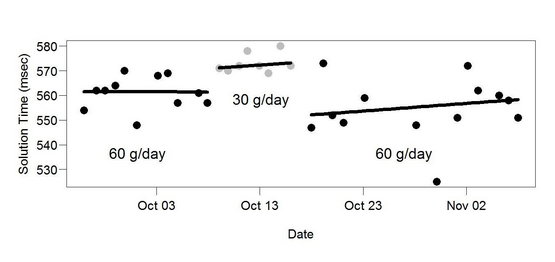
Some sources might recommend the more advanced ABAB approach…
…but ABAB isn’t all that convincing either. Is that a change in the periods of “positive attention”, or just a random walk? It’s pretty hard to tell.
Again, this is vague at best. Yes, it took him longer to do arithmetic problems on 30 g/day butter than on 60 g/day butter. But the change is not very distinct, the three periods clearly overlap, it’s not clear if the periods were randomly determined, etc. And most of all, the sample size is just not very large — we can do better than drawing strong conclusions from a mere three intervals.
You shouldn’t totally discount these simple designs. Starting here can be fine (see for example Allan Neuringer’s self-experiments). Simplicity is important, and if you’re doing early stage exploratory work, going with a study design that’s easy has obvious benefits. If you don’t see any difference with this simple approach, you can move on to something else. If you do see a difference in the ABA, and you want to demonstrate that difference in a more convincing way, then you can expand it into a true within-subjects study.
There’s nothing wrong with Seth’s butter ABA — it’s just that it looks like the start of something, rather than a conclusion. If he wanted to really convince people, he should have spun that off into a longer self-experiment.
Within-Subjects Approach
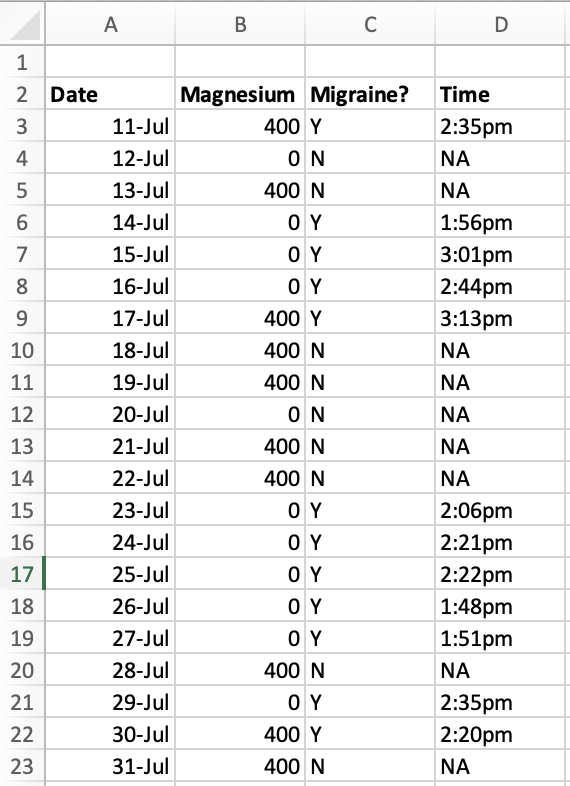
Emily is a woman in her late 20s who gets migraines on a regular basis. She usually gets hit with a migraine in the middle of the afternoon, and they happen almost every day. Emily has been tracking her migraines for a long time, and has determined that each day there’s an 80% chance that a migraine will descend on her at about 2:00 pm, ruining the rest of her afternoon.
Emily has recently noticed that if she takes 400 mg magnesium in the morning, it’s much less likely she’ll have a migraine that afternoon. This isn’t a sure thing — she still gets migraines on days when she takes the magnesium — but it seems like it’s less than 80%.
One way for Emily to get some support for this hypothesis would be for her to run a simple AB self-experiment. She could take no magnesium for two weeks, then take 400 mg magnesium every morning for two weeks, and see if it makes a difference for her migraines. If she gets migraines 80% of the time in weeks where she’s taking no magnesium and only 40% of the time in weeks where she’s taking 400 mg magnesium, that seems like evidence that the magnesium is helping.
And it is evidence, but it’s on the weak side. Depending on how you slice it, the effective sample size here is two — just one fortnight with magnesium, and one fortnight without. You shouldn’t draw strong conclusions here for the same reason that you shouldn’t draw strong conclusions from a study with one person in the experimental group and one person in the control group. There’s just not that much evidence.
With small sample sizes, there are too many alternative explanations, it’s too easy to fool yourself. Maybe she started taking magnesium in the springtime, and the increased daylight is the real reason her migraines improved. Or she just started a new job two months ago, and it took her two months to stop grinding her teeth, which happened to align with the switch over to magnesium. Or her detergent manufacturer switched to a new supplier for fragrances. Or maybe her mailman’s cat, which she’s allergic to, ran away last week. It could be almost anything.
To account for these problems, Emily can just go ahead and get a larger sample size. She can use a random number generator to randomly assign days to either take magnesium or not take magnesium, and then follow that random assignment.
With the addition of these two small steps, she can now use a normal within-subjects experimental approach. Let’s imagine she finds that there’s an 80% chance of developing a migraine on days when she takes no magnesium, and a 30% chance of developing a migraine on days when she takes 400 mg magnesium. She can demonstrate this difference to an arbitrary level of precision, just by running the trial for more days.
Emily’s data might look something like this. The data shown here is not quite enough to reach statistical significance (χ2 gives p = .051) but it’s looking pretty good for 30% chance of migraines with magnesium and 80% chance without.
Even if the difference is much more subtle — perhaps a 75% chance of a migraine with 400 mg magnesium and 80% without — with enough days, she can still show to an arbitrary level of confidence that the magnesium has the observed effect FOR HER, however small that effect might be.
This wouldn’t provide any evidence that magnesium will work for anyone ELSE’s migraines. But even if it doesn’t generalize at all to anyone else, Emily can get as much evidence as she wants that it’s really doing something for her. And that still helps the community, because it shows that the treatment works at least sometimes, for some people.
This is different from a traditional case study. Even though it’s looking at just one person, it uses experimental techniques. Compared to a traditional experiment, you sacrifice external validity (will this generalize to anyone other than this one person?) but you still get the same level of statistical rigor and you can still clearly infer causality.
And with this design, you should be able to use standard within-subjects statistical approaches. A sample size of just one is unusual even for a within-subjects study, but not entirely unheard of.
This approach is under-used in the internet research community (though Scott Alexander did one here and Gwern did one with LSD). Lots of people are online sharing tips and tricks on things they think might help their reflux/migraines/IBS/heart palpitations/executive function/etc. This is good, but it’s hard to know which recommendations are solid and which are just random chance.
If you run a within-subject self-experiment, you can do something incredible for your community. It may not help everyone, but you can demonstrate whether it works for you. Publish your null results too — if you suspect that caffeine triggers your reflux, but under close inspection the hypothesis falls apart, report that shit!
We should emphasize that N = 1 studies falsify a very specific kind of null hypothesis: that an intervention cannot work. If the intervention works for you, that just shows that the intervention can work.
It might not work for anyone else, and with N = 1 you have a much higher chance that one person will do something idiosyncratic that makes it look like the intervention was successful, when in fact it was the idiosyncratic thing doing all the work. For example, maybe on days you take magnesium, you always take it with a big glass of lemonade. It turns out the lemonade is what’s helping your symptoms, not the magnesium, and this wouldn’t be apparent from the data, because the lemonade and the magnesium are confounded.
If you want to go above and beyond, you can get a couple friends and do an even more compelling test with only a few people. As long as you all do multiple trials, your effective sample size from a statistical standpoint can still be arbitrarily large. With more people, we have greater certainty that there isn’t something weird confounded with the experimental variable (but never 100%). Every chronic illness subreddit should be generating research pods of 2-10 people, and testing the treatments they think are worth investigating.
Limitations
Even with better randomization, however, these designs still have a lot of limitations.
For a start, they’re limited by the speed of your research cycle. For example, repeated-measures studies won’t work very well for studying obesity, because people tend to lose and gain weight pretty slowly. It may take months to lose and then regain weight, so it’s hard to study weight gain with this method. If you have to randomize periods of months, it will take you a full year to get a sample size of 12. In comparison, headaches would be easier to study, since they come and go daily or even hourly, and you could randomize your treatment on much shorter timescales.
Worse, for some treatments we don’t know what the appropriate timescales will be. Let’s return to Emily and her migraines. If magnesium works on the order of weeks rather than days, she will have to randomly assign weeks rather than days, which means it will take seven times longer to reach an equivalent sample size. But how can she know in advance whether to use periods of days or of weeks?
If a cure is too powerful, or has long-lasting effects, that actually makes it harder to study. If magnesium cures Emily’s migraines for a month, she’ll have to wait a month between randomization cycles, and it will take her years to get a decent sample size.
Similarly, this kind of protocol may not be able to detect more complicated relationships. If Emily’s body builds up a reservoir of extra magnesium over time, this may be difficult to model and might throw off the clarity of the experiment. Or if her body gets more aggressive about clearing the excess magnesium from her system, the magnesium will have less effect over time, and will have even less effect on trial runs where she has multiple magnesium blocks one after another. These designs have a lot to offer, but they’re not going to get us very far in the face of genuinely complex problems.
Another downside of this approach is that Emily has already found a treatment she likes. Probably she would like to take magnesium every day and get as few migraines as possible, but to do this within-subjects self-experiment, she has to try going off the magnesium multiple times over the course of several months, to make sure it really works. We think it’s often worth it to know for sure, but it isn’t easy to stop a treatment that seems to be working.
Finally, the big limitation is that you can only use this approach if you’ve already identified a treatment that you suspect might work for you. If you’re sick and you don’t have any leads, this method can’t help you figure out what to try. It’s only good for testing or confirming hypotheses — it can’t give you any new ones, can’t narrow down a list of cures or triggers out of the huge number of things that might possibly be making you sick.
Research methods are still very new, probably we can sit down and invent some more.
This is good news, because right now there are many problems that we have no idea how to solve. One area of particular mystery is human health. Doctors can do a lot for you with surgery, vaccines, and antibiotics, but outside of these interventions there remain many ailments that totally stump the system.
A weird part of the postmodern experience is that many people feel kinda bad all the time, even if they aren’t “sick”. If you go to the doctor and you’re like “I’m feeling kinda bad”, they don’t know how to help you.
Being “actually sick” doesn’t get you much further. If anything it’s worse. Lots of people have mystery chronic illnesses, but when you go to doctors with one of these problems, they mostly just shrug at you.
II.
Alistair Kitchen began having stomach pain. It started out small, but over time grew to “an intensity of pain I didn’t know my body was capable of producing, a literally blinding sensation that shut down every sense in my body except the sensations of my stomach.” He says:
So, four years of this. In the third year, after an endoscopy and a series of scans had cleared me for anything “serious”, the advice given to me was, essentially, this:
Look, some people just have trouble with their stomachs. When they have trouble and we don’t know what is causing it, we just call it IBS. So you have IBS. Watch out for foods that might trigger you, and good luck.
Me (over 20 pages of medical history and 30 minutes of conversation): I can’t digest protein or fiber, when I try it feels like something died inside me.
Them: Oh that’s no good, you need to eat so much protein and vitamins
Me: Yes! Exactly! That’s why I made an appointment with you, an expensive doctor I had to drive very far to get to. I’m so excited you see the problem and for the solution you’re definitely about to propose.
Them: What if you took a slab of protein and chewed it and swallowed it. But like a lot of that.
Me: Then I’d feel like something died inside me, and would still fail to absorb the nutrients which is the actual thing we want me to get from food.
Them: I can’t help you if you’re not willing to help yourself.
Having faced this system, many people end up taking their health into their own hands. This makes a lot of sense and we fully endorse it. But most people have no more success on their own than they do with doctors (though at least they’re not being condescended to).
It seems like the average outcome is that you end up living with your mystery illness (or even just your mystery sense-of-mild-feeling-bad-all-the-time) for years. It either never goes away, or randomly goes away some day for no apparent reason.
III.
We suspect that people do about as well on their own as they do with doctors because *no one* knows how to study individual issues. This is because our civilization has done a good job developing population-level research techniques, but a crummy job so far coming up with individual-level research techniques.
Our society has devoted a lot of time to doing research on large groups. We’ve come up with lots of ways of running studies on large samples, and lots of ways of thinking about it. We’d bet that 99% of the studies you’ve ever read are studies on groups.
In comparison, doing research on individuals is a very understudied and (dare we say) cutting-edge form of research. Scientists mostly haven’t developed techniques for it, because almost by definition, it isn’t the kind of thing they study.
Possibly this is because doctors and researchers are more interested in population-level issues. After all, they are usually tasked with solving public health crises, tasked with curing common diseases, things that might affect millions of people. But individuals care more about, well, individuals.
Possibly this is because we started by focusing on the most common illnesses and are only now getting around to the rare ones. Common illnesses are best studied by looking at large groups, so we developed those techniques first, and are only now running up against their limitations.
Possibly it is all a question of computational power. The history of statistics is tainted, because statistics was invented before computers, and was designed within the limits of what a person can reasonably calculate by hand. Even up to the 1990s, consumer machines would take weeks to crunch the kinds of models that today you can run in 15 minutes on your phone. But now we can do more, and maybe that means we can do new things, things that weren’t possible before.
In any case, it must be possible to come up with protocols for such a thing.
“Jimmy with Electrodes”
Individual-level research comes with certain advantages. The problem with population-level techniques is that the same treatment will always work better for some people than for others. If you give two people the same drug, it might work great for one of them and not work at all for the other, and your statistical modeling needs to take that into account. Individual-level research doesn’t have to worry about that! You are just looking at one person.
A technical way of describing this is that individual-level research always has high internal validity — the research question is “does this treatment protocol work for this person” and you always get a straight answer to that question. This comes at the cost of external validity — you have basically no idea whether your findings will generalize to any other person. That’s an ok tradeoff, because you are already choosing to study an individual, and because population-level techniques have questionable external validity to begin with.
We may also be able to use population-level techniques to guide individual-level research, and individual-level techniques to guide population-level research; there may be many ways in which they are complementary.
Individual-level techniques won’t be limited to studying chronic illness — you could also use them, for example, to make healthy people feel amazing more often, which would be pretty cool. People who already feel amazing all the time, you’re on your own.
But chronic illness is a good place to start, because these illnesses are a drain on the lives of millions of people who are motivated to figure out a treatment, and population-level medicine isn’t cutting it.
This is a problem we have been mulling over and that we will be writing about over the next couple months. To start with, here are some simple distinctions that seem like they might come in handy:
Testing vs. Finding Variables
When studying an individual, there are two main situations.
One situation is where you think you know some variables that are involved with your illness, and you want to test them. For example, you may suspect that caffeine makes you feel nauseous. You want to confirm this hypothesis or rule it out. You might also want to demonstrate to a high degree of certainty that caffeine is really a trigger for you, so you can write about it on the internet and other people with random nausea can benefit from your example, possibly by trying it for themselves.
The other situation is where you have no idea what is causing your illness. When you have no clear leads, you want techniques that can help you find variables that might plausibly be involved. This is a much harder problem, but it’s also much more important, because many people are chronically sick and have no idea what is causing their illness.
This sucks, and it’s very tricky because there are approximately infinity variables in the world. But probably we can do better than “try variables at random” (even if some level of luck is inevitably involved), and we should see if we can come up with techniques for this situation.
Triggers vs. Deficiencies
Sometimes a chronic illness is caused by getting too much of something, like an allergen. These are generally known as triggers. Sometimes a chronic illness is caused by not getting enough of something, like a vitamin. We call these deficiencies.
This distinction seems like it might be helpful, because the techniques for finding triggers may be very different from the techniques for finding deficiencies. (More on this in future posts.)
We should also keep in mind that chronic illnesses can be more complicated than simply getting too much or too little of something. Some chronic illnesses aren’t caused by any external variable — there’s always the possibility that you have a brain tumor or something, in which case there may be no triggers or deficiencies involved.
Ruling In vs. Ruling Out
Sometimes we will be in the fortunate position where we can get a lot of evidence that X causes Y. If we can conclusively pin things down and show that dairy causes your chronic nausea, that’s great. Now you can keep yourself from feeling sick all the time, and that’s enormously valuable.
But sometimes we won’t be able to get evidence in favor of anything — we will only be able to disprove things. It’s important to remember that this is valuable too. Maybe you suspect that your nausea might be caused by dairy, caffeine, alcohol, or fatty foods. If you go through them one by one and rule them all out — nope it’s not dairy, it’s not caffeine, not alcohol, not fatty foods — that’s still good to know.
It will be disappointing that you continue to feel nauseous all the time and you don’t know why. It may feel like a step backwards, because you’ve ruled out all your best guesses. But it’s still enormous progress. Disproving a hypothesis is valuable, and at least now you’ll be able to enjoy your milkshakes, Irish coffees, and beer-battered onion rings without fear.
The best thing research can offer you is a cure, but the second-best thing it can offer is some peace of mind.