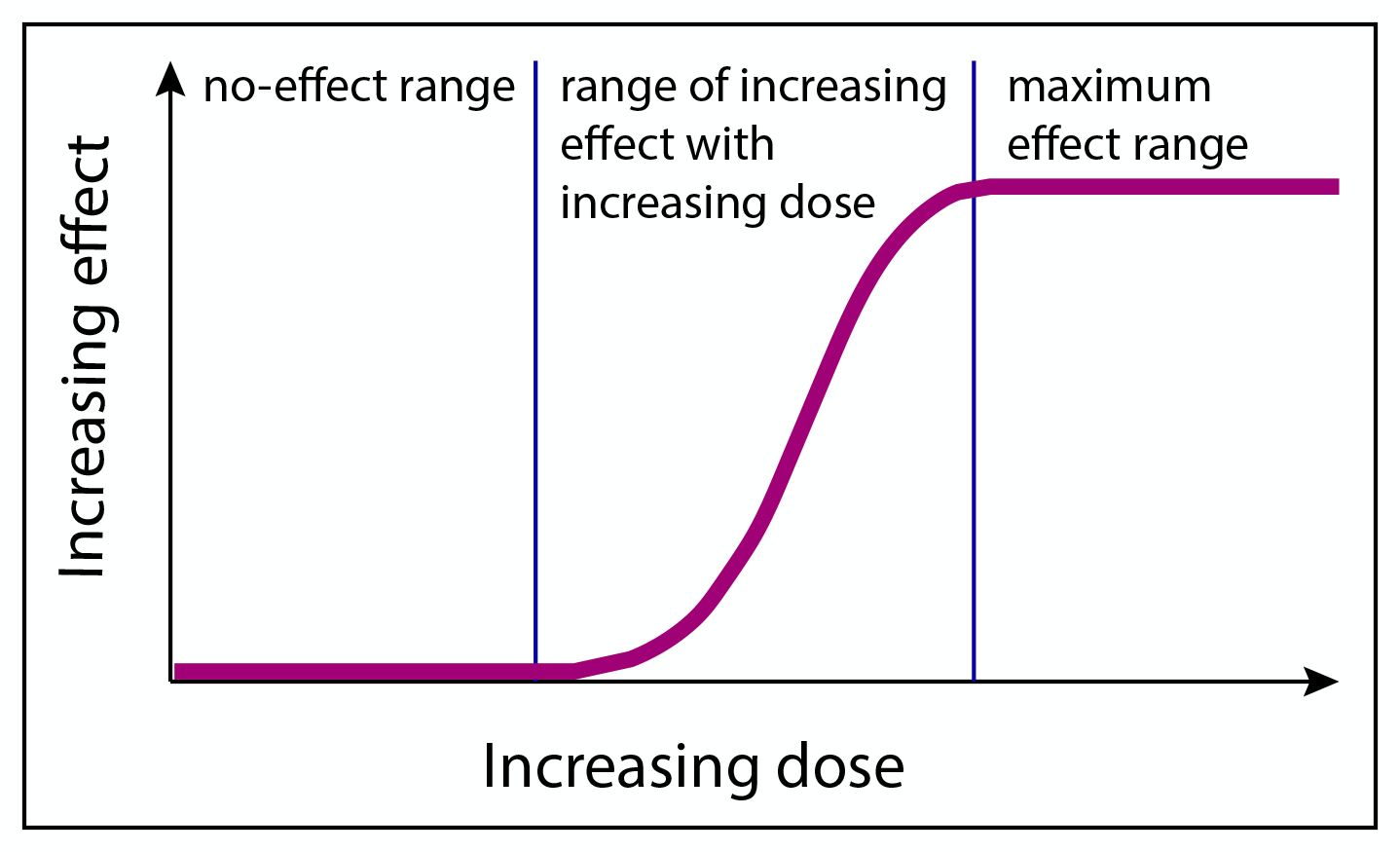
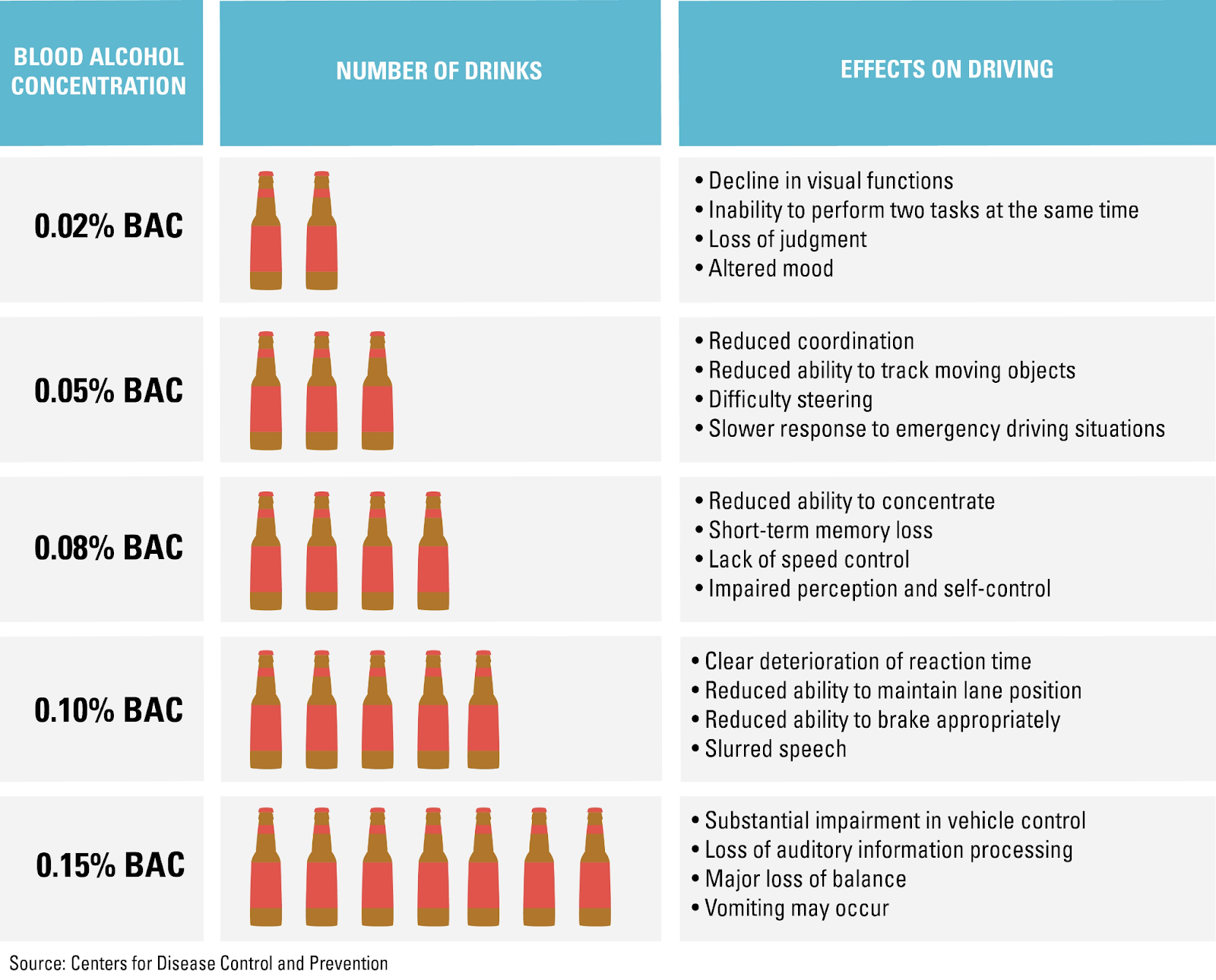
Drugs have effects. Take more of a drug, and you’ll get more and bigger effects. They call this a dose-response relationship — take some dose, get some response. Benadryl makes you drowsy, mercury gives you hallucinations, cyanide kills you.
But these effects only kick in above certain doses. At very low doses, the drug has no effects. This always has to be true, because at zero dose, the drug can’t have any effects.
Then at some dose, the effect starts kicking in. Sometimes this means you start feeling it a little and it gets stronger over time. Other times, it means the response rate increases, and more people start feeling the effect as they take bigger doses.
At some point, the effect is as strong as it can possibly get and it doesn’t get any stronger. Everyone who is going to have a reaction is getting the strongest effect they can get.
Dose-response relationships can be described with dose-response curves, like this one:
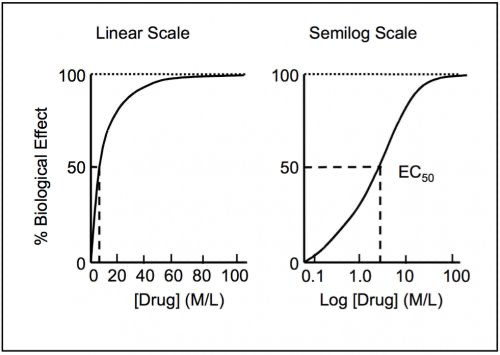
Often these curves make the most sense on a log scale (probably because this is bounded exponential growth; it’s exponential but eventually everyone who is going to have the effect already has it), so for this exercise, we’ll be portraying the x-axis on a log scale. This may not be true for all drugs, but it’s a reasonable starting place.
Lithium is a metal that is also a drug that sometimes causes weight gain. But no one really knows what the dose-response curve for weight gain on lithium looks like. Weight gain is clearly a side effect of clinical doses of lithium (about 50-300 mg of elemental lithium a day), at least for some people. But almost no one has studied lithium doses below 50 mg a day, so we don’t know at what point this weight gain effect starts kicking in.
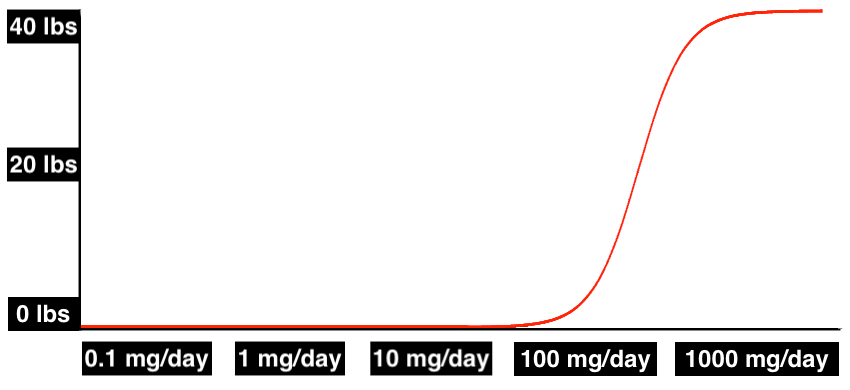
The dose-response curve could look like this, where weight gain doesn’t show up until you hit therapeutic doses of 100 mg/day and more:
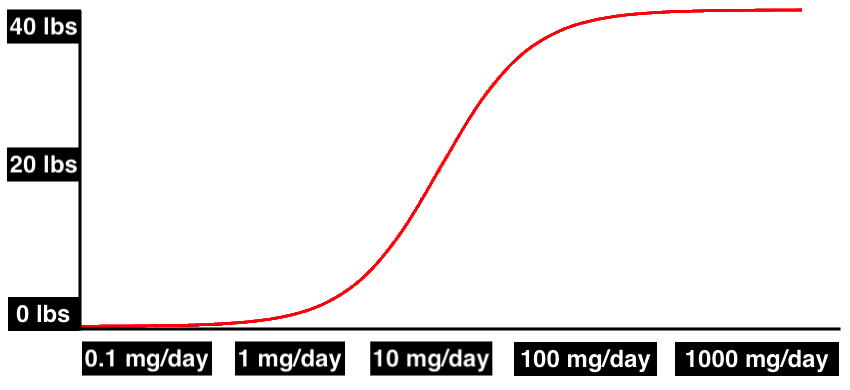
Or it could look like this, where effects kick in starting at subclinical doses of as low as 1 mg/day:
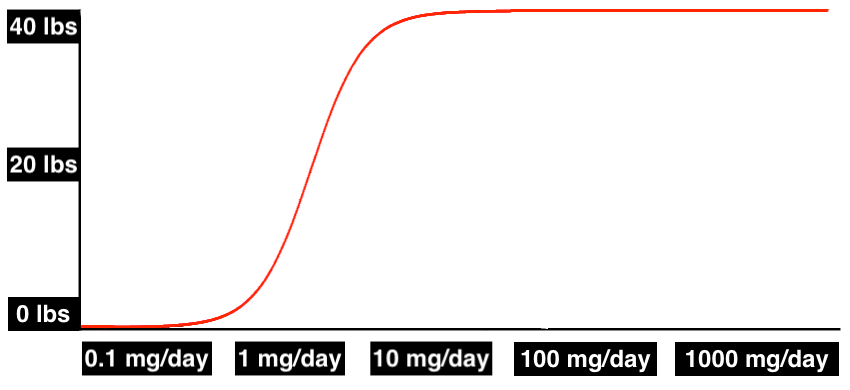
Or it could even look like this, where weight gain starts at trace doses of less than 1 mg/day, and once you’re getting 10 mg/day, you’re maxed out:
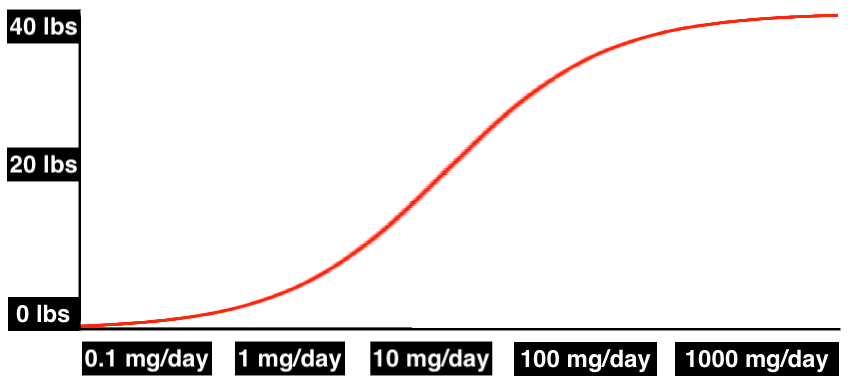
The curve could be spread out, with gradual effects increasing across all plausible doses:
Or it could be incredibly abrupt, where weight gain happens suddenly once you’ve passed a certain threshold:
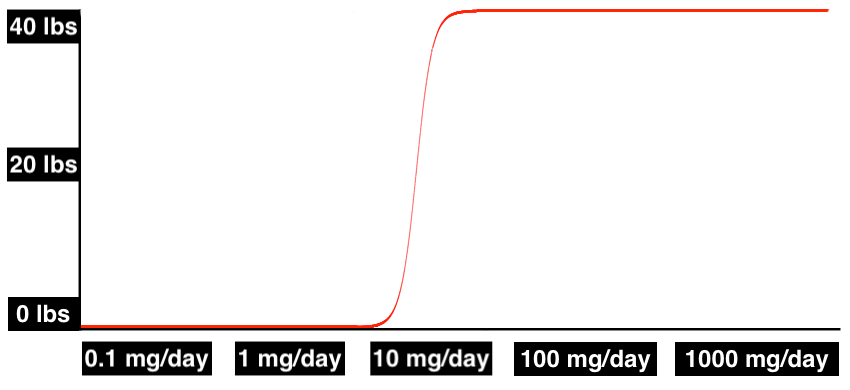
There’s also good reason to believe the dose-response curve will be different for different people. The response may be different in terms of the shape of the curve, when the effects kick in, and when they max out.
By ancient tradition, we will call our example patients “Alice” and “Bob”. In this hypothetical, Bob starts seeing weight gain as he approaches 1 mg/day and has already gained almost 40 lbs at 10 mg/day, but Alice doesn’t get the same effects until noticeably higher doses:
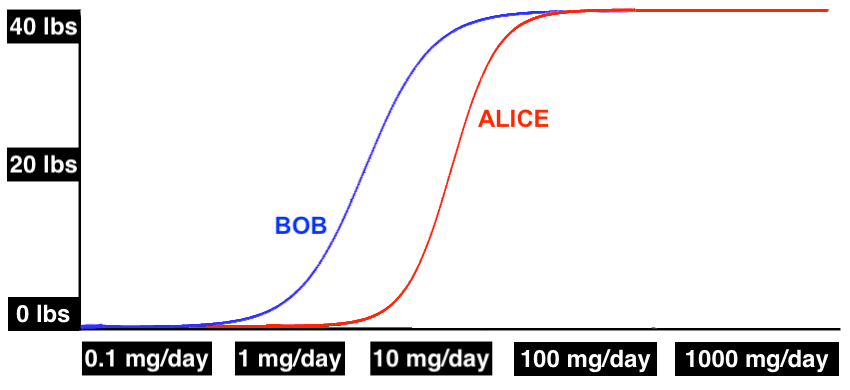
It might also be different in terms of the maximum effect. In this next example, not only does Alice not start gaining weight until 10 mg/kg, she caps out her weight gain at just over 20 lbs, while Bob gains 40 lbs on a similar dose:
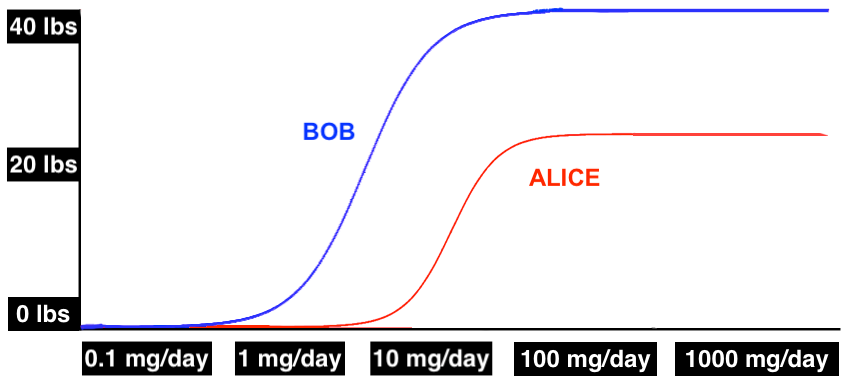
Psychiatric doses of lithium are in the 50-300 mg range (elemental), and some people think this means that weight gain must happen in this range. But this may not be the case.
First of all, there’s plenty of evidence suggesting that the psychiatric effects of lithium kick in at trace doses of less than 1 mg/day. The effects may not be very strong at trace doses, but you can still pick them out in a population-level analysis. In fact, there’s a whole dang literature finding that rates of dementia, suicide, homicide, and other “behavioral outcomes” are associated with trace lithium levels in drinking water. This suggests that some effects kick in at very small doses.
But regardless of whether or not trace amounts of lithium lower the suicide rate, the fact is that lithium has several different effects, and there’s no reason those effects can’t kick in at different doses. It might look something like this:
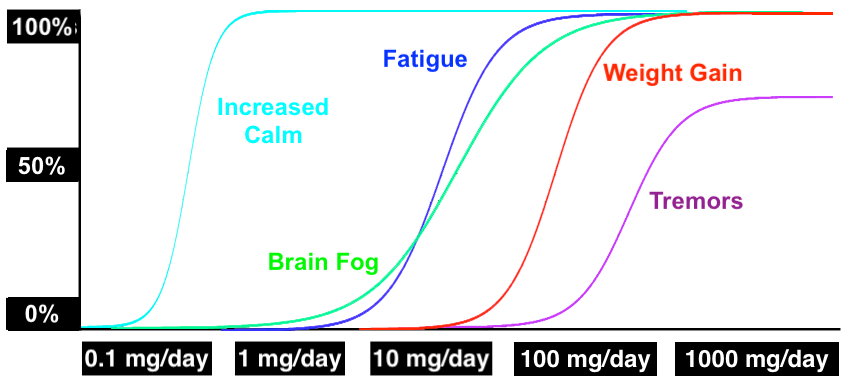
(To be clear, all these curves are completely made up for the purposes of illustration.)
This should probably be our default assumption. Most drugs have multiple effects, and different effects often kick in at different doses. For example, alcohol is a drug that makes you talkative at low doses and makes you puke your guts out at high doses.
(Your mileage may vary. Adam Mastroianni, who reviewed this piece, says, “Not me, I puke a tiny amount at tiny doses, increasing to a massive amount of puke at large doses.”)
In fact, we know that lithium has effects that kick in at different doses, because therapeutic effects tend to kick in well before patients die from lithium toxicity, and death is also an effect.
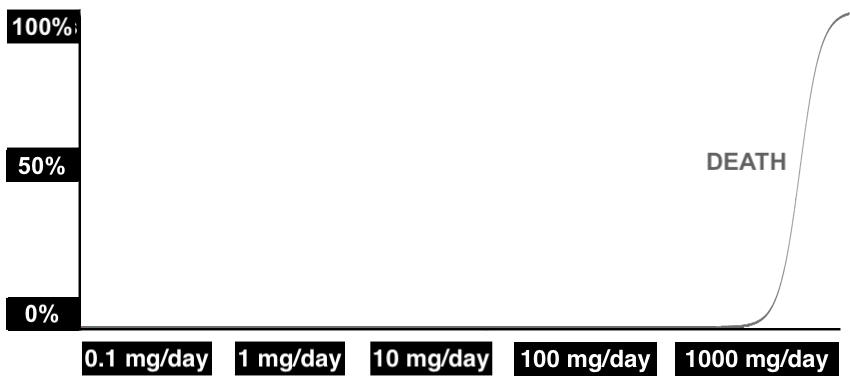
It’s true that some people don’t gain weight at all, even on clinical doses of more than 1000 mg/day. But this might just mean that in their case, the dose-response curve for weight gain is above the dose-response curve for toxicity/death. You can’t get there without dying, so we never see it. (And for some people, the mechanism by which lithium causes weight gain probably just doesn’t work at all.)
In any case, we have almost no information about what the curves might look like for lithium, because there’s very little research on doses below the low end of the clinical range (around 50 mg/day). There’s that literature on trace doses in drinking water which we mentioned above, and there’s one RCT from the ‘90s finding that trace doses of lithium made violent offenders friendlier and happier — but as far as we know, there’s never been any formal study on doses in the range of 1-50 mg/day. If anyone has studied weight gain on lithium doses below 50 mg/day, we’ve certainly never seen it.
So let’s see what we can do to figure out anything at all about the dose-response curve for the weight gain effects of lithium — and, maybe more interesting, the effects of lithium in general. Do any of these curves start showing up at subclinical doses?
Nootropics Survey
One thing that’s interesting, in terms of our bigger “is lithium exposure causing the obesity epidemic?” question, is that most of the side effects of lithium are non-specific — if you feel nauseous and tired, it could be lithium exposure, but it could equally be a million other things. That makes it hard to tell if symptoms of lithium exposure have increased over the past 50 years, since no one has been tracking brain fog rates since 1970. If the rate of increased thirst has dectupled, we might not even know (unless…).
But one thing people do track is hypothyroidism. Clinical doses of lithium, at least, can lead to hypothyroidism, and even mild thyroid dysfunction is linked to changes in body weight. And while the evidence isn’t anywhere near conclusive, some studies suggest that the rate of hypothyroidism has increased — see for example this popular press article, this analysis of hypothyroidism in the UK, and this study of a population in Scotland. Since clinical doses can cause thyroid problems, increasing rates of hypothyroidism make it slightly more plausible that trace lithium exposure (which has clearly increased) has subclinical effects.
Some of the effects we’re going to study — like fatigue, depression, and muscle weakness — are also symptoms of hypothyroidism. These are also nonspecific, but if they were to increase, they might be diagnosed as hypothyroidism. We’re curious to see if they increase on low, subclinical doses.
We worked with Troof (a science blogger who has recently been studying nootropics) to put together a survey (a PDF version is available on the OSF) asking nootropics enthusiasts about the doses of lithium they have tried, if any, and the effects they experienced on each dose. (In case you’re not familiar, here’s the Wikipedia page for nootropics.)
The survey was pretty straightforward. First, we asked people for their basic demographic information. Then, we asked them to describe their previous experience with lithium.
We allowed people to record information for up to five different doses of lithium — different in either being different amounts (e.g. 1 mg/day vs 5 mg/day), different compounds (e.g. lithium as lithium orotate vs. as lithium carbonate), or both.
For each dose, we asked people to tell us what compound they took, how much they took per day, and approximately how many days they tried the dose for.
We also asked them what effects they experienced on each dose. Our list of effects was based on this page from Mayo Clinic, though our list did not include all the effects mentioned on this page.
We make no claims that our list is any sort of principled selection — it’s just a subset of effects we decided to include. There were too many to include all of them, so we made some calls.
In particular, we focused on “milder” side effects, since we knew that the nootropics folks would be on lower doses than a clinical population and would probably not experience the more severe effects. We also combined some effects to avoid redundancy — for example, we combined multiple effects related to passing gas into the single effect “flatulence” on our list.
We do regret cutting “fruit-like breath odor” and “eyeballs bulge out of the eye sockets”. Now those are side effects.
In any case, the final list was:
- Increased clarity / focus
- Increased calm
- Improved mood
- Improved sleep
- Trouble sleeping
- Weight gain
- Weight loss
- Confusion, poor memory, or lack of awareness
- Fainting
- Fast, pounding, or irregular heartbeat or pulse
- Frequent urination
- Increased thirst
- Slow heartbeat
- Stiffness of the arms or legs
- Troubled breathing (especially during hard work or exercise)
- Unusual tiredness or weakness
- Brain fog
- Dizziness
- Eye pain
- Headache
- Vision problems
- Depression
- Diarrhea
- Drowsiness
- Lack of coordination
- Loss of appetite
- Muscle weakness
- Fatigue
- Nausea
- Ringing in the ears
- Slurred speech
- Trembling (severe)
- Bloating or indigestion
- Flatulence
- Decreased libido
- Loss in sexual ability, desire, drive, or performance
- Tooth pain
We also included an option for “other”.
Finally, because we are especially interested in weight changes, we also asked for each dose, “If you lost / gained weight, what was approximately the magnitude of the loss / gain”, with answers in kilograms.
Recruitment
Nootropics enthusiasts often take small amounts of lithium, usually because they believe it has a variety of beneficial effects at low doses, effects including balanced mood and reduced stress. So recruiting from the nootropics subreddit seemed like a good way to find people who already have experience with subclinical doses.
We put out the survey on r/Nootropics, in a post titled, “We’re Collecting People’s Experiences with Lithium. All Results and Data Will Be Posted Publicly. If You Have Experience with Lithium, Please Contribute!” This was our only recruitment strategy and, as far as we know, all responses came from people on r/Nootropics.
A total of 40 people filled out the survey, providing data on at least one regimented dose (an amount taken daily for a period of time) of lithium. Of these, 20 people also reported on a second dose, 5 reported on a third dose, 2 reported on a fourth dose, and one person reported on a fifth dose. From this we can see that of the respondents, 50% have tried at least two different doses of lithium at some point.
For now, we will ignore that some of these doses are the same people, and just treat these as 68 different individual doses. Going back and doing more complex modeling at some point would be a good idea, we encourage that, but it’s not the focus of the post today. To keep it clear, we will call these “cases”. There are 40 people who gave us 68 cases.
Two people don’t report how much they were taking for their second dose, however, so we will be ignoring these cases. In the end we have 66 cases.
This is all self-report, and we haven’t been at all strict about kicking people out. In fact, we didn’t kick anyone out. Some of the data do look a little strange. One person reported taking 5 mg/day of lithium carbonate, which seems unlikely. But we’re taking the data at face value for now.
Doses
First of all, we want to see how much elemental lithium everyone is taking.
Many people reported a single number for their daily lithium dose, but some people reported a range, e.g. “5mg-20mg”. To convert this into a single number for analysis, whenever a person gave a range of values, we went with the average of the range endpoints. In this example, a report of “5mg-20mg” would be converted to 12.5 mg.
Different lithium compounds contain different amounts of elemental lithium. This is the “active ingredient”, so to speak. We did our best to estimate elemental lithium from the numbers people reported. In most cases, this was pretty straightforward. Lithium carbonate is prescribed by the weight of the compound, and the elemental dose is 18.8% of the weight of the listed dose. Lithium orotate usually lists elemental lithium on the packaging, and so most of the time, no conversion is needed.
However, we did have to guess on a few. For example, one person said that they were taking lithium orotate, but said they were taking 130 mg per day. Based on what we know about lithium orotate doses available on the market (see e.g. here), we think 130 mg elemental is very unlikely — this is probably 5 mg elemental, so we coded it as 5 mg. For all these conversions, you should be able to double-check our numbers in the raw data (available on the OSF).
Having made these conversions, we find that people were taking doses between 0.25 and 282 mg per day elemental lithium, over spans ranging from 1 day to 4 years. We use dose per day because it’s easy to track. Here’s the distribution:
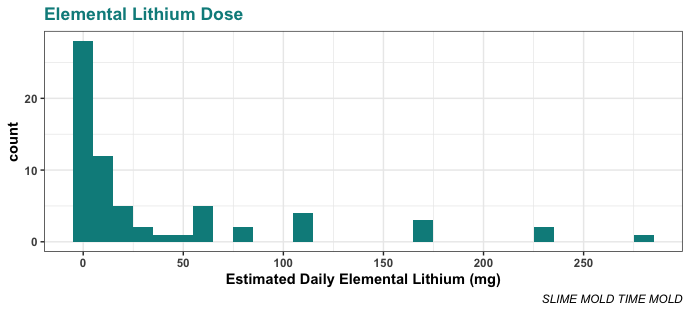
As you can see, most people were taking less than 50 mg/day. In fact, most were taking less than 25 mg/day. The median daily dose in this sample is 10 mg/day, the mean is 39.6 mg/day, and the mode (15 people) is 5 mg/day. The next most popular dose after the mode is actually 1 mg/day — 6 people were trying that amount.
In comparison, the average therapeutic dose is 50-300 mg/day elemental lithium, usually delivered as lithium carbonate. So overall, these nootropics folks are taking rather small doses.
Lithium orotate was by far the most popular compound in our sample. This makes a lot of sense — lithium orotate can be purchased over the counter, or over the internet, without a prescription, and comes in relatively low elemental doses, all of which makes it an ideal nootropic. Of the 66 cases, 42 people were taking lithium orotate, 22 were taking lithium carbonate, and one each were taking lithium aspartate and “Lithium Chloride / Ionic Lithium”.
We keep saying “doses”, but it’s important to keep in mind that from a biological point of view, these are not really doses — these are deltas, a change in the daily dose. People are already getting some small daily dose of lithium every day from their food and water, so whatever they are taking as a nootropic is a dose in addition to the dose they were already getting. We don’t currently know what kinds of doses people are getting from food and water — the literature is a little confused at points — but we’re confident that it’s more than zero.
So while we don’t know if the average American is getting 5 mg/day from their food or just 0.05 mg/day, we know they’re getting some amount — for now, let’s call the average everyday dose X. If someone is taking 5 mg/day as a nootropic, they’re not getting a total dose of 5 mg/day, they’re getting X + 5 mg/day.
Weight Change
Let’s start by looking at weight change on these low doses.
Like the doses themselves, weight change was also reported as a range in a few cases. Like the doses, whenever someone gave a range, we took the mean of that range as our point estimate value.
Here are the weight changes people reported compared to the daily elemental dose they were taking. Note that the weight changes here are in kilograms:
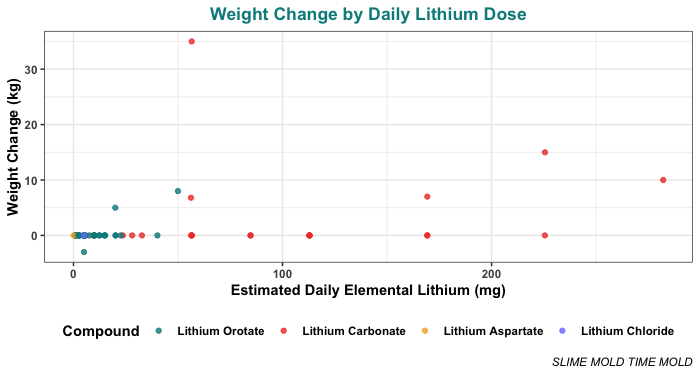
That plot is a little hard to read because most people are taking low doses (< 50 mg/day) so most of the points are crammed in over on the left side. To make it easier to read, here’s the same plot with the x-axis log10 transformed (with some jitter in the x-axis to keep points from overlapping):
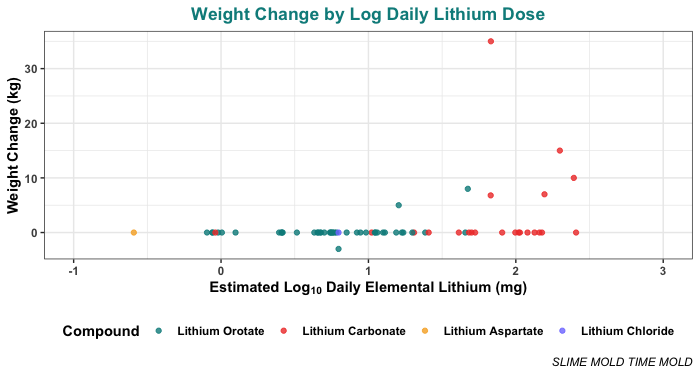
One caveat is that these plots include many people who didn’t actually mention any weight change at all. Since they didn’t mention it, we assumed the weight change on their dose was effectively zero. This seems like a pretty safe assumption, but just in case, here’s the same plot with only the people who explicitly said something about their weight change:
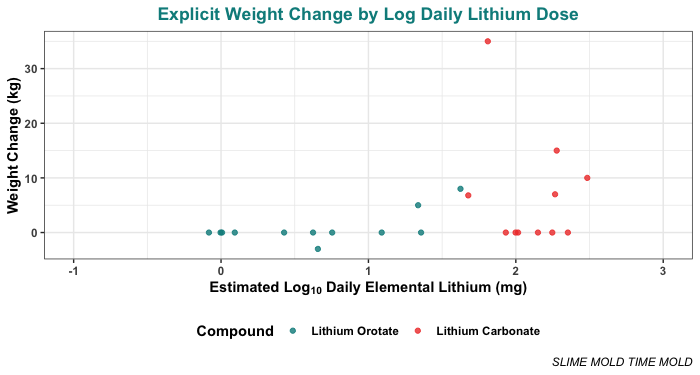
Most people didn’t see any weight change, or at least, they didn’t report any. But 8 of the 66 cases did report some weight change.
The first weight change reported is a loss of 3 kg, at a dose of 5 mg/day. This is a low dose, and it’s weight lost, not weight gained, which makes it something of an outlier.
The first weight gain reported is an increase of 5 kg on 20 mg/day, which this participant reported taking for approximately 365 days. The next weight gain is 8 kg on 50 mg/day, which the person reported taking for only 60 days.
After 50 mg, weight gain seems to be more common, though certainly not universal. Of people who took more than 50 mg/day elemental, 6 of 18 reported weight gain, which is 33%. The highest weight gain reported was 35 kg (not pounds, he was quite clear) on 56.4 mg/day elemental taken as 300 mg/day lithium carbonate, over 4 years.
So, keeping the limitations of the small sample in mind, this suggests that the weight gain effects kick in around the range of 20–50 mg/day of elemental lithium, for somewhere in the ballpark of one third of people.
The sample size is quite small, but if you squint, it does kind of look like weight gain kicks in a bit earlier for Lithium Orotate than for Lithium Carbonate. We didn’t expect this, but while we were working on this project, a reader pointed us to a small literature finding that lithium orotate is sometimes effective at a lower dose than lithium carbonate.
This is a literature that currently seems to be driven by Anthony Pacholko and Lane Bekar, two Canadian researchers from Saskatchewan, building off of the work of Hans Nieper in the 1970s. In the interest of full disclosure, we should tell you that Wikipedia describes Nieper as “a controversial German alternative medicine practitioner” whose therapies have “been discredited as ineffective and unsafe.” The “see also” links at the bottom of his page are “List of unproven and disproven cancer treatments” and “Quackery”. Caveat lector.
In any case, there is a review by Pacholko and Bekar from 2021, which does cite many sources outside Nieper, and says in the abstract, “[lithium orotate] is proposed to cross the blood–brain barrier and enter cells more readily than [lithium carbonate], which will theoretically allow for reduced dosage requirements and ameliorated toxicity concerns”. They also have an empirical study published in 2022, which reports benefits of lithium orotate over lithium carbonate in mice.
We’re not going to review the whole literature here, but it’s worth noting. Let’s mark it down for now as suggestive.
Other Effects
Weight gain is not the only effect of lithium. It might not even be the most interesting effect.
The nootropics people on reddit dragged us for mostly including negative effects — which, you know what, totally fair. We should have included more positive effects. We’re interested in seeing when the bad stuff kicks in, but while we were at it, we should have looked at when everything kicked in. If we study this again, we’ll include more positive effects.


We also now realize that we should have asked for the effects on a scale (1-7, 0-3, something like that). Asking just “did you experience increased thirst or not” gives us very little information for most of these symptoms. If we study this again, we’ll use more detailed measures.
But for now, let’s look at the data we have. And the data we have are already pretty interesting. People reported experiencing all sorts of effects:
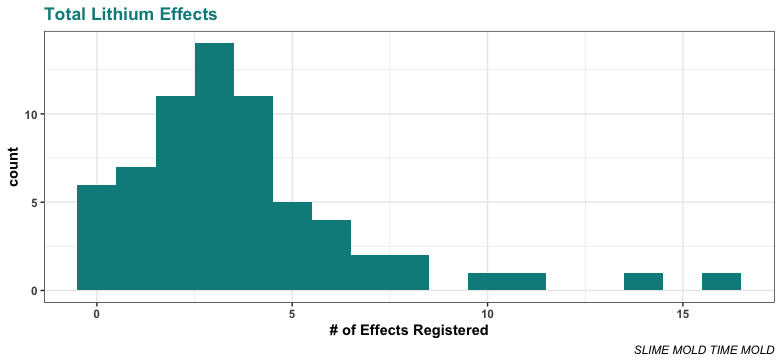
And, to our surprise, they reported lots of these effects even on pretty low doses:
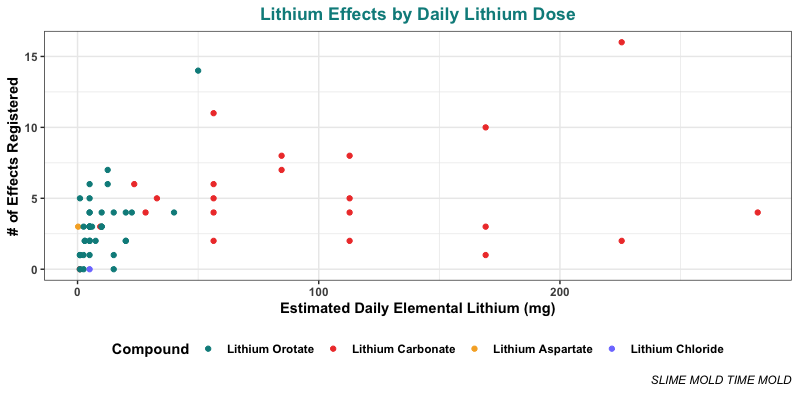
As before, this is a little hard to read because of the squashing. Here’s the same thing with the x-axis log10 transformed:
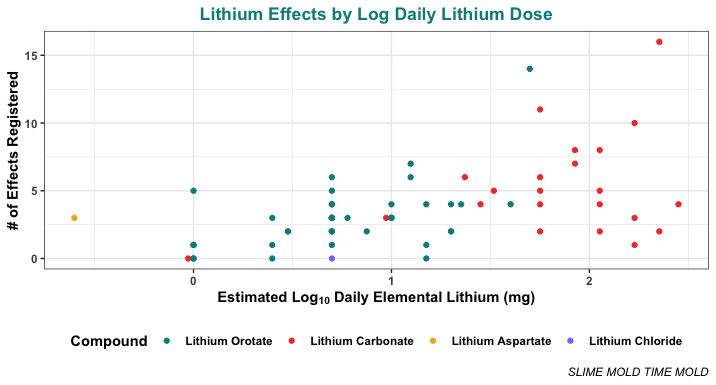
Even below 10 mg/day elemental (a 1 on the x-axis above, since this is log10), most people are reporting a few of these effects, and some of them are reporting several. Above 10 mg/day elemental, almost everyone reports multiple effects! It’s clear that stuff starts kicking in at pretty small doses.
Moving beyond the aggregated effects, we can ask, what effects popped up specifically? Here’s the list, with the number of cases that mentioned each effect:
- Increased clarity / focus: 14
- Increased calm: 38
- Improved mood: 35
- Improved sleep: 23
- Trouble sleeping: 7
- Confusion, poor memory, or lack of awareness: 12
- Fainting: 0
- Fast, pounding, or irregular heartbeat or pulse: 1
- Frequent urination: 10
- Increased thirst: 11
- Slow heartbeat: 0
- Stiffness of the arms or legs: 1
- Troubled breathing: 2
- Unusual tiredness: 5
- Brain fog: 13
- Dizziness: 5
- Eye pain: 2
- Headache: 3
- Vision problems: 1
- Depression: 5
- Diarrhea: 4
- Drowsiness: 5
- Lack of coordination: 4
- Loss of appetite: 5
- Muscle weakness: 2
- Fatigue: 8
- Nausea: 2
- Ringing in the ears: 3
- Slurred speech: 2
- Trembling (severe): 3
- Bloating or indigestion: 4
- Flatulence: 2
- Decreased libido: 10
- Loss in sexual ability, desire, drive, or performance: 4
- Tooth pain: 0
And here are the top 10:
- Increased calm: 38
- Improved mood: 35
- Improved sleep: 23
- Increased clarity / focus: 14
- Brain fog: 13
- Confusion, poor memory, or lack of awareness: 12
- Increased thirst: 11
- Frequent urination: 10
- Decreased libido: 10
- Fatigue: 8
We see that the four positive effects are the most commonly reported, which is what we would expect from a population of nootropics users who are taking lithium in search of positive effects. More than half of the cases reported “increased calm” and “improved mood”, and around a third reported “improved sleep”. On top of this, 14 reported “increased clarity / focus”. Of the 66 cases, 50 (about 75%) reported at least one of these four positive effects.
But this also makes it especially striking that so many people reported negative effects. If anything, this population is inclined to downplay the negative effects of lithium, but negative effects were reported quite frequently.
The most commonly reported negative effect was brain fog (13), followed by “confusion, poor memory, or lack of awareness” (12). These sound like the same thing, but there wasn’t perfect overlap. We see that 7 people reported brain fog without reporting confusion, and 6 reported confusion without reporting brain fog.
It’s pretty weird that “increased clarity / focus” is the fourth most common effect and “brain fog” and “confusion, poor memory, or lack of awareness” are effects #5 and #6. Aren’t these polar opposites? Why are they right next to each other in the rankings? Sounds like a possible paradoxical reaction.
The next most common effects were increased thirst (11) and frequent urination (10), which also seem related.
After that, the next most common is decreased libido (10), which is supported by a less common but related effect, “loss in sexual ability, desire, drive, or performance” (4). These are both reported at rather low doses, as low as 1 mg/day.
The next most common are fatigue (8), and trouble sleeping (7), and then we get into numbers too small to go over individually. But even so, almost every symptom we put on our list was reported by at least one person — we certainly did not expect that. The only three symptoms that no one reported were fainting, slow heartbeat, and tooth pain.
Some of these symptoms, like ringing in the ears (3), are only reported by people who were taking more than 50+ mg/day. But lots of effects start appearing at very low doses.
Like with the weight gain, there might be more effects for orotate than for carbonate at the same elemental dose. Don’t take this as conclusive — there’s not all that much evidence. But it is intriguing.
We can even do a regression looking at just the data from cases where people were taking carbonate or orotate. This brings us to a somewhat unusual finding.
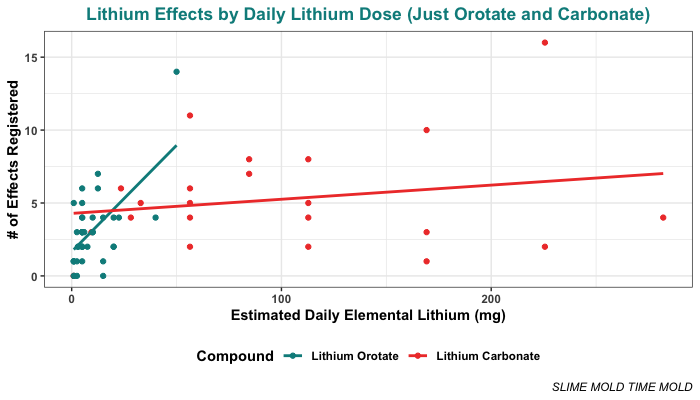
When the dose of elemental lithium is used to predict the total number of lithium effects, the regression model finds significant main effects of both dose (p = .0008) and compound (p = .021), and a significant dose-by-compound interaction (p = .0019). The total R-squared is 0.257, which is pretty good. This model suggests that lithium orotate does bring on more effects at a lower dose than lithium carbonate.
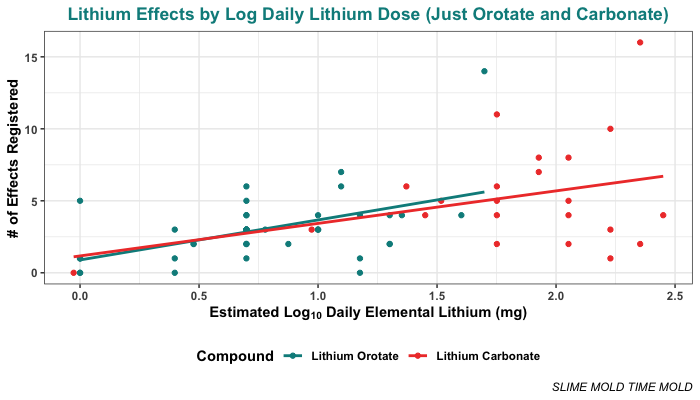
But, there is only a main effect of dose (p = .005) when dose of elemental lithium is log10 transformed. In this case, the compound (p = .899) and the interaction (p = .718) are not significant, though the R-squared is pretty similar (0.245).
This difference is pretty clear when we plot both models with their regression lines. Here’s the situation if you don’t log-transform the daily lithium dose. You can clearly see that the slopes of the two lines are very different:
But here’s the situation if you do log-transform the daily lithium dose. You can clearly see that the slopes of the two lines are nearly identical:
This is a little weird. On the one hand, that’s a pretty clear interaction in the non-transformed data. On the other hand, we would expect log transformation to be the appropriate transformation for this analysis. Make of that what you will.
Troof points out that a lot of this interaction seems to be driven by a single participant, who looks kind of unusual and is taking an unusually high dose of lithium orotate. If you look at the plots, you can see them as a somewhat clear outlier (taking the most orotate and having the most effects of anyone on that compound). So probably don’t put too much trust in this data point, and without it, the case for an interaction basically disappears.
Conclusion
These results suggest that many effects of lithium kick in at subclinical levels. In this sample, the majority of people who took at least 1 mg of elemental lithium a day reported at least one effect, and people on doses above 5 mg/day tended to report experiencing several effects.
The most common effects people reported were the four positive effects we asked about, but several negative effects of lithium were commonly reported as well, especially brain fog, “confusion, poor memory, and lack of awareness”, increased thirst, frequent urination, decreased libido, “loss in sexual ability, desire, drive, or performance”, fatigue, and trouble sleeping. A slight majority of cases (53%) reported at least one negative effect.
Weight gain was not a common effect, but it was reported at relatively low doses. The lowest dose for reported weight gain was on a dose of 20 mg/day, and the next lowest was on 50 mg/day. The greatest reported weight gain was on a dose of only 56.4 mg/day. Taken together, this suggests that in the current environment, lithium can cause noticeable weight gain on elemental doses below 50 mg/day, and possibly as low as 20 mg/day.
Unfortunately, this does not tell us all that much about the dose-response curve. There are just too many degrees of freedom, and we don’t know that X value, the amount that people are getting from their food and water. It could be that X is well below the dose-response curve, and +50 mg/day is needed to push you onto the curve:
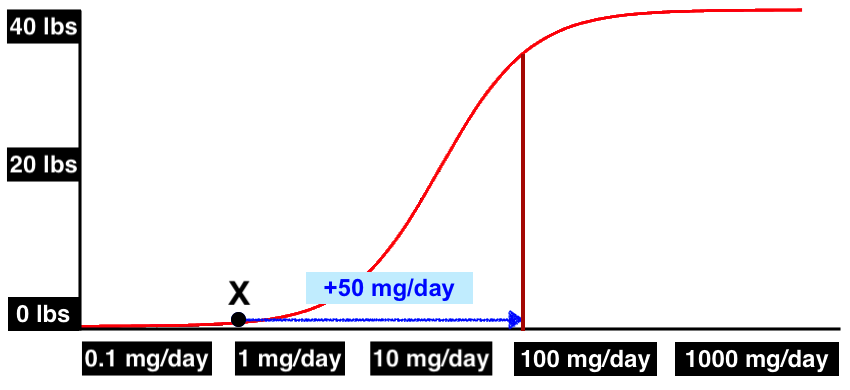
But it could equally be the case that X is well onto the curve — past the point of greatest sensitivity! — and a big delta like +50 mg/day is needed just to see any weight change at all.
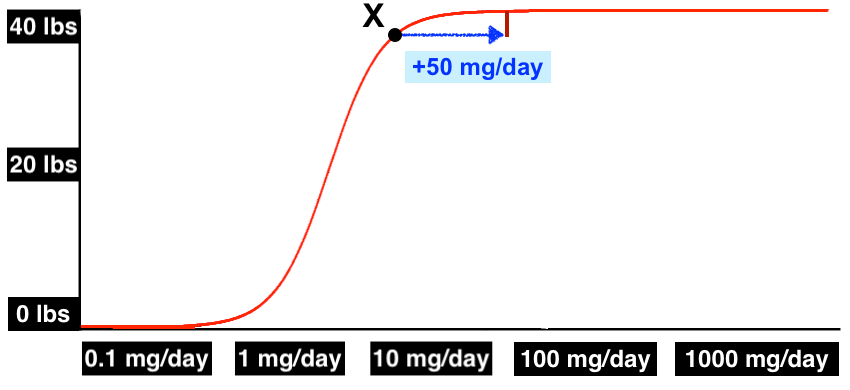
This evidence doesn’t rule anything in, but it does rule some things out. Given these findings, we can mostly rule out the idea that doses below 10 mg/day have no effects. We can also rule out the idea that weight gain starts kicking in at just 0.1 mg/day — it seems pretty clear that you need a bigger delta than that. But we can also mostly rule out the idea that weight gain only occurs above 600 mg/day.
So while it’s good that some things are ruled out, we still don’t know enough to pin down the dose-response curve.
At least, not for weight gain. We do see what looks like evidence of the dose-response curves for other effects.
Troof also played around with the data a bit, and sent us the following graph. The pattern is clear for some effects and rather messy for others, but we see what looks very clearly like the start of a dose-response curve for increased thirst. We also see what look like dose-response curves for improved mood, improved sleep, increased calm, and increased clarity, where rates of the effects increase and then level off. But there isn’t a clear curve for brain fog or confusion, at least not in these data.
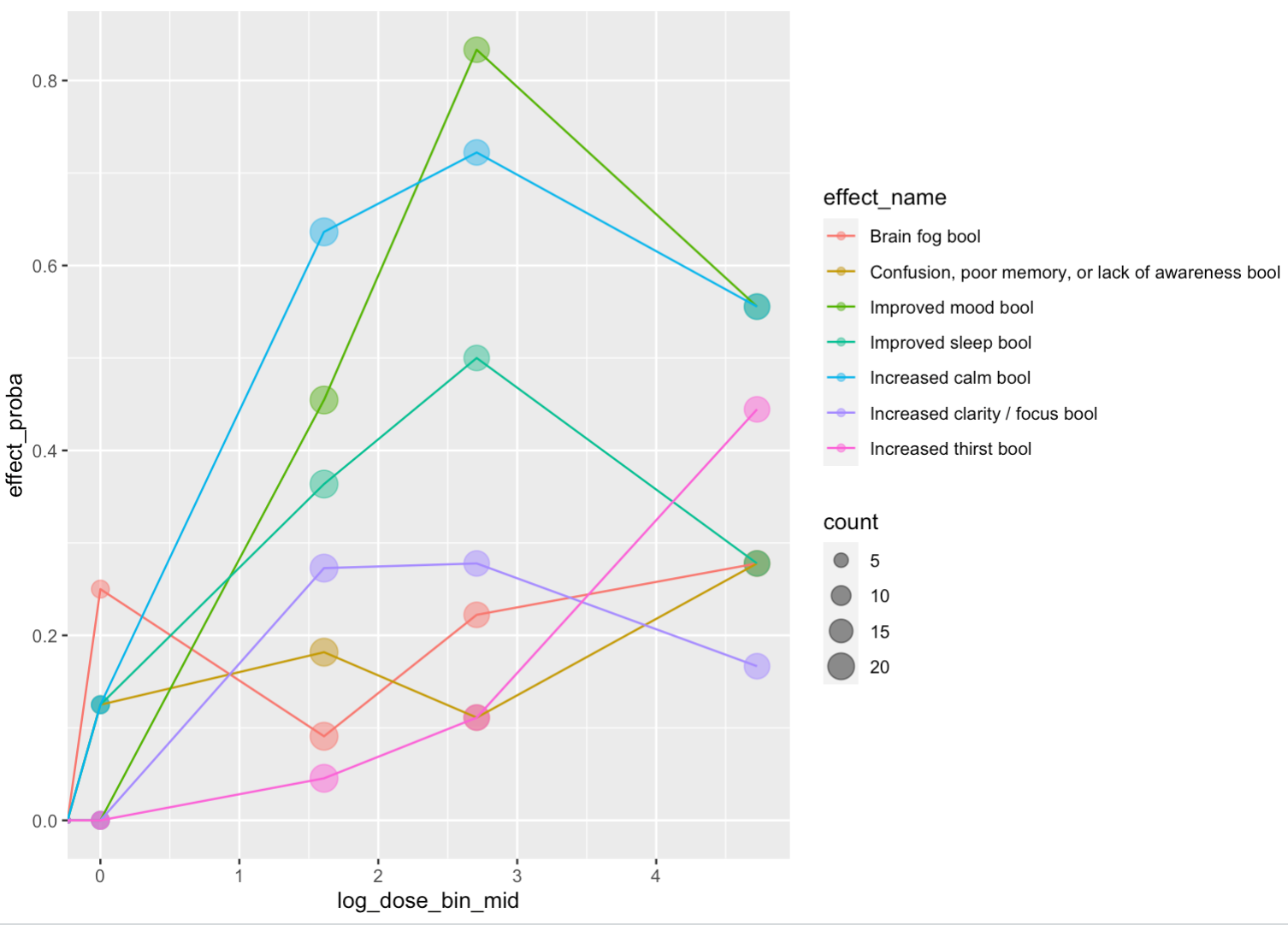
One weird thing we noticed is that most of these dose-response curves come down at the highest dose level, suggesting that some of these effects actually get less likely past a certain point. Not sure what’s going on there, we’re interested to hear what people think.
Human Challenge
At this point you might be wondering: should someone do a human challenge trial for low-dose lithium? You know, round up some brave souls on the internet, get them all to take 10 mg’s worth of lithium orotate every day for a month, and see what happens to them by the end. Is that a good idea?
We don’t think this is a good idea, for a couple reasons. First of all, we don’t know what X is, which means that increasing the dose by a fixed amount isn’t actually all that informative.
Second, we’re pretty sure that X is different in different places and for different people. Combine this with the fact that different people probably have different dose-response curves for strictly genetic reasons, and the results begin seeming hopelessly complicated.
Finally, while low-dose lithium does seem to have positive effects for many people, some of its effects are quite nasty. We wouldn’t want to subject volunteers to unnecessary brain fog and fatigue. If we were sure that the study would teach us a lot, then maybe it would be worth it, maybe we would be open to convincing people to give it a go. Maybe we would try it ourselves. But since we don’t think it would really answer any of our biggest questions, we don’t think a lithium supplementation study would be worth anyone’s while.
However, Troof has convinced us that there are more than 40 people out there who have already tried subclinical doses of lithium, and that at least some of them will be reading this post. So we’ve put together an updated version of our survey that fixes some of the problems we mentioned above — it asks about the magnitude of each effect, includes more positive effects, and includes more effects in general. If you’ve taken lithium before, you can fill out the survey here, and if we get enough responses, we will post another analysis. If you filled out the first survey, you can fill this one out too, because this one is a little more detailed — just check the box that indicates that you took the first survey, so we can make sure not to double-count you.