A new paper, called Obesity II: Establishing Causal Links Between Chemical Exposures and Obesity, was just published in the journal Biochemical Pharmacology (available online as of 5 April 2022). Authors include some obesity bigwigs like Robert H. Lustig, and it’s really long, so we figured it might be important.
The title isn’t some weird Walden II reference — there’s a Part I and Part III as well. Part I reviews the obesity epidemic (in case you’re not already familiar?) and argues that obesity “likely has origins in utero.”

Part III basically argues that we should move away from doing obesity research with cells isolated in test tubes (probably a good idea TBH) and move towards “model organisms such as Drosophila, C. elegans, zebrafish, and medaka.” Sounds fishy to us but whatever, you’re the doctor.
This paper, Part II, makes the case that environmental contaminants “play a vital role in” the obesity epidemic, and presents the evidence in favor of a long list of candidate contaminants. We’re going to stick with Part II today because that’s what we’re really interested in.
For some reason the editors of this journal have hidden away the peer reviews instead of publishing them alongside the paper, like any reasonable person would. After all, who could possibly evaluate a piece of research without knowing what three anonymous faculty members said about it? The editors must have just forgotten to add them. But that’s ok — WE are these people’s peers as well, so we would be happy to fill the gap. Consider this our peer review:
This is an ok paper. They cite some good references. And they do cite a lot of references (740 to be exact), which definitely took some poor grad students a long time and should probably count for something. But the only way to express how we really feel is:

Seriously, 43 authors from 33 different institutions coming together to tell you that “ubiquitous environmental chemicals called obesogens play a vital role in the obesity pandemic”? We could have told you that a year ago, on a budget of $0.
This wasted months, maybe years of their lives, and millions of taxpayer dollars making this paper that is just like, really boring and not very good. Meanwhile we wrote the first draft of A Chemical Hunger in a month (pretty much straight through in October 2020) and the only reason you didn’t see it sooner was because we were sending drafts around to specialists to make sure there wasn’t anything major that we overlooked (there wasn’t).
We don’t want to pick on the actual authors because, frankly, we’re sure this paper must have been a nightmare to work on. Most of the authors are passengers of this trainwreck — involved, but not responsible. We blame the system they work under.
We hope this doesn’t seem like a priority dispute. We don’t claim priority for the contamination hypothesis — here are four papers from 2008, 2009, 2010, and 2014, way before our work on the subject, all arguing in favor of the idea that contaminants cause obesity. If the contamination hypothesis turns out to be right, give David B. Allison the credit, or maybe someone even earlier. We just think we did an exceptionally good job making the case for the hypothesis. Our only original contributions (so far) are arguing that the obesity epidemic is 100% (ok, >90%) caused by contaminants, and suggesting lithium as a likely candidate.
So we’re not trying to say that these authors are a bunch of johnny-come-latelies (though they kind of are, you see the papers up there from e.g. 2008?). The authors are victims here of a vicious system that has put them in such a bad spot that, for all their gifts, they can now only produce rubbish papers, and we think they know this in their hearts. It’s no wonder grad students are so depressed!
So to us, this paper looks like a serious condemnation of the current academic system, and of the medical research system in particular. And while we don’t want to criticize the researchers, we do want to criticize the paper for being an indecisive snoozefest.
Long Paper is Long
The best part of this paper is that comes out so strongly against “traditional wisdom” about the obesity epidemic:
The prevailing view is that obesity results from an imbalance between energy intake and expenditure caused by overeating and insufficient exercise. We describe another environmental element that can alter the balance between energy intake and energy expenditure: obesogens. … Obesogens can determine how much food is needed to maintain homeostasis and thereby increase the susceptibility to obesity.
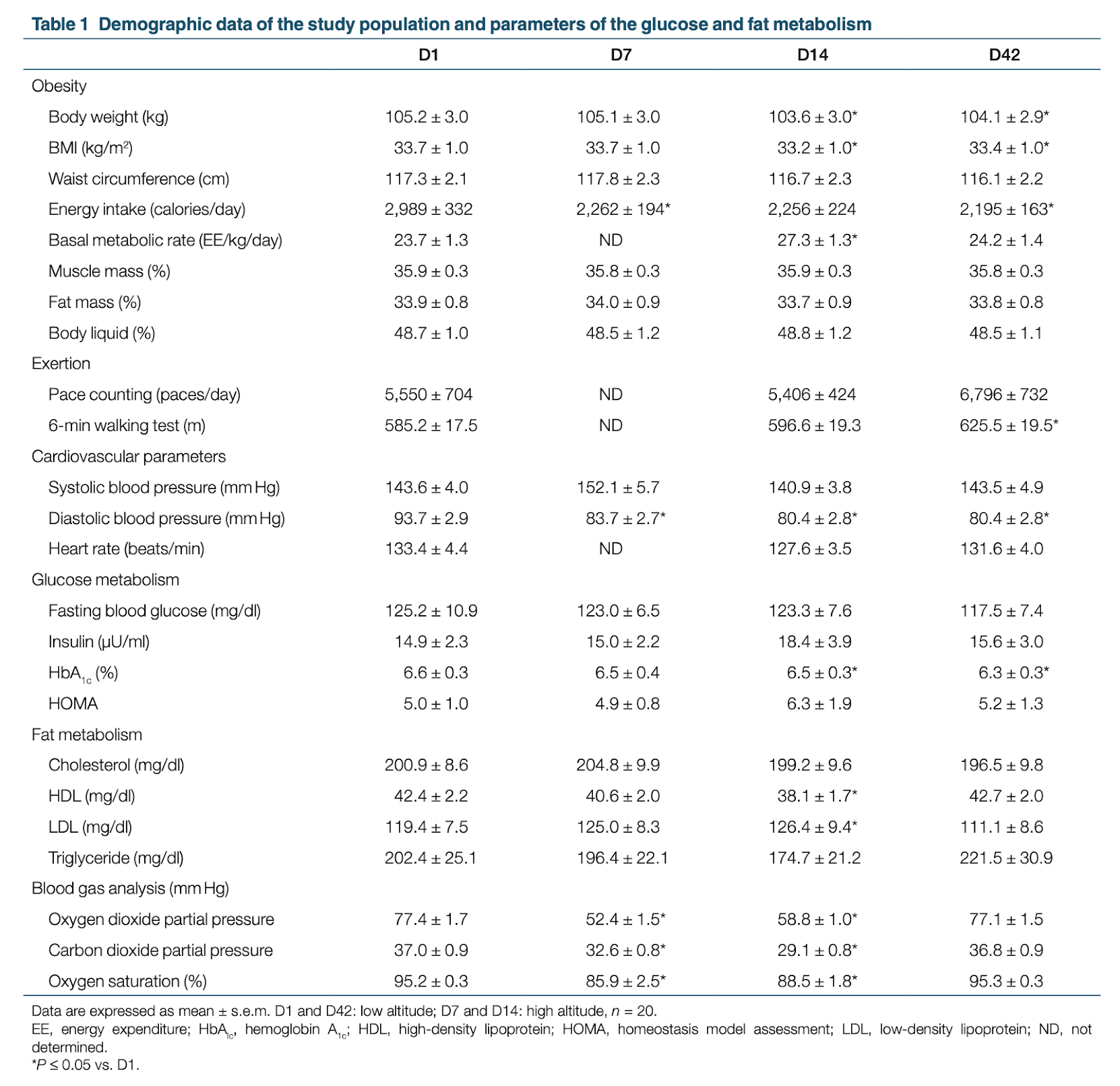
In particular we like how they point out how, from the contaminant perspective, measures of how much people eat are just not that interesting. If chemicals in your carpet raise your set point, you may need to eat more just to maintain homeostasis, and you might get fat. This means that more consumption, of calories or anything else you want to measure, is consistent with contaminants causing obesity. We made the same point in Interlude A. Anyways, don’t come at us about CICO unless you’ve done your homework.
We also think the paper’s heart is in the right place in terms of treatment:
The focus in the obesity field has been to reduce obesity via medicines, surgery, or diets. These interventions have not been efficacious as most people fail to lose weight, and even those who successfully lose substantial amounts of weight regain it. A better approach would be to prevent obesity from occurring in the first place. … A significant advantage of the obesogen hypothesis is that obesity results from an endocrine disorder and is thus amenable to a focus on prevention.
So for this we say: preach, brothers and sisters.
The rest of the paper is boring to read and inconclusive. If you think we’re being unfair about how boring it is, we encourage you to go try to read it yourself.
Specific Contaminants
The paper doesn’t even do a good job assessing the evidence for the contaminants it lists. For example, glyphosate. Here is their entire review:
Glyphosate is the most used herbicide globally, focusing on corn, soy and canola [649]. Glyphosate was negative in 3T3-L1 adipogenic assays [650], [651]. Interestingly, three different formulations of commercial glyphosate, in addition to glyphosate itself, inhibited adipocyte proliferation and differentiation from 3T3-L1 cells [651]. There are also no animal studies focusing on developmental exposure and weight gain in the offspring. An intriguing study exposed pregnant rats to 25mg/kg/day during days 8-14 of gestation [652]. The offspring were then bred within the lineage to generate F2 offspring and bread to generate the F3 progeny. About 40% of the males and females of the F2 and F3 had abdominal obesity and increased adipocyte size revealing transgenerational inheritance. Interestingly, the F1 offspring did not show these effects. These results need verification before glyphosate can be designated as an obesogen.
For comparison, here’s our review of glyphosate. We try to, you know, come to a conclusion. We spend more than a paragraph on it. We cite more than four sources.
We cite their [652] as well, but we like, ya know, evaluate it critically and in the context of other exposure to the same compound. We take a close look at our sources, and we tell the reader we don’t think glyphosate is a major contributor to the obesity epidemic because the evidence doesn’t look very strong to us. This is bare-bones due diligence stuff. Take a look:
The best evidence for glyphosate causing weight gain that we could find was from a 2019 study in rats. In this study, they exposed female rats (the original generation, F0) to 25 mg/kg body weight glyphosate daily, during days 8 to 14 of gestation. There was essentially no effect of glyphosate exposure on these rats, or in their children (F1), but there was a significant increase in the rates of obesity in their grandchildren (F2) and great-grandchildren (F3). There are some multiple comparison issues, but the differences are relatively robust, and are present in both male and female descendants, so we’re inclined to think that there’s something here.
There are a few problems with extending these results to humans, however, and we don’t just mean that the study subjects are all rats. The dose they give is pretty high, 25 mg/kg/day, in comparison to (again) farmers working directly with the stuff getting a dose closer to 0.004 mg/kg.
The timeline also doesn’t seem to line up. If we take this finding and apply it to humans at face value, glyphosate would only make you obese if your grandmother or great-grandmother was exposed during gestation. But glyphosate wasn’t brought to market until 1974 and didn’t see much use until the 1990s. There are some grandparents today who could have been exposed when they were pregnant, but obesity began rising in the 1980s. If glyphosate had been invented in the 1920s, this would be much more concerning, but it wasn’t.
Frankly, if they aren’t going to put in the work to engage with studies at this level, they shouldn’t have put them in this review.
If this were a team of three people or something, that would be one thing. But this is 43 specialists working on this problem for what we assume was several months. We wrote our glyphosate post in maybe a week?
Some of the reviews are better than this — their review of BPA goes into more detail and cites a lot more studies. But the average review is pretty cruddy. For example, here’s the whole review for MSG:
Monosodium glutamate (MSG) is a flavor enhancer used worldwide. Multiple animal studies provided causal and mechanistic evidence that parenteral MSG intake caused increased abdominal fat, dyslipidemia, total body weight gain, hyperphagia and T2D by affecting the hypothalamic feeding center [622], [623], [624]. MSG increased glucagon-like peptide-1 (GLP-1) secretion from the pGIP/neo: STC-1 cell line indicating a possible action on the gastrointestinal (GI) tract in addition to its effects on the brain [625]. It is challenging to show similar results in humans because there is no control population due to the ubiquitous presence of MSG in foods. MSG is an obesogen.
Seems kind of extreme to unequivocally declare “MSG is an obesogen” on the basis of just four papers. On the basis of results that seem to be in mice, rats, mice, and cells in a test tube, as far as we can tell (two of the citations are review articles, which makes it hard for us to know what studies they specifically had in mind). Somehow this is enough to declare MSG a “Class I Obesogen” — Animal evidence: Strong. In vitro evidence: Strong. Regulatory action: to be banned. Really?
Instead, we support the idea of — thinking about it for five minutes. For example, MSG occurs naturally in many foods. If MSG were a serious obesogen, tomatoes and dashi broth would both make you obese. Why are Italy and Japan not more obese? The Japanese first purified MSG and they love it so much, they have a factory tour for the stuff that is practically a theme park — “there is a 360-degree immersive movie experience, a diorama and museum of factory history, a peek inside the fermentation tanks (yum!), and finally, an opportunity to make and taste your own MSG seasoning.” Yet Japan is one of the leanest countries in the world.
As far as we can tell, Asia in general consumes way more MSG than any other part of the world. “Mainland China, Indonesia, Vietnam, Thailand, and Taiwan are the major producing countries in Asia.” Why are these countries not more obese? MSG first went on the market in 1909. Why didn’t the obesity epidemic start then? We just don’t think it adds up.
(Also kind of weird to put this seasoning invented in Asia, and most popular in Asia, under your section on “Western diet.”)

Let’s also look at their section on DDT. This one, at least, is several paragraphs long, so we won’t quote it in full. But here’s the summary:
A 2017 systematic review of in vitro, animal and epidemiological data on DDT exposures and obesity concluded the evidence indicated that DDT was “presumed” to be obesogenic for humans [461]. The in vitro and animal data strongly support DDT as an obesogen. Based on the number of positive prospective human studies, DDT is highly likely to be a human obesogen. Animal and human studies showed obesogenic transmission across generations. Thus, a POP banned almost 50 years ago is still playing a role in the current obesity pandemic, which indicates the need for caution with other chemical exposures that can cause multigenerational effects.
We’re open to being convinced otherwise, but again, this doesn’t really seem to add up. DDT was gradually banned across different countries and was eventually banned worldwide. Why do we not see reversals or lags in the growth of obesity in those countries those years? They mention that DDT is still used in India and Africa, sometimes in defiance of the ban. So why are obesity rates in India and Africa so low? We’d love to know what they think of this and see it contextualized more in terms of things like occupation and human exposure timeline.
Review Paper
With a long list of chemicals given only the briefest examination, it’s hard not to see this paper as overly inclusive to the point of being useless. It makes the paper feel like a cheap land grab to stake a claim to being correct in the future if any of the chemicals on the list pan out.
Maybe their goal is just to list and categorize every study that has ever been conducted that might be relevant. We can sort of understand this but — why no critical approach to the material? Which of these studies are ruined by obvious confounders? How many of them have been p-hacked to hell? Seems like the kind of thing you would want to know!
You can’t just list papers and assume that it will get you closer to understanding. In medicine, the reference for this problem is Ioannidis’s Why Most Published Research Findings Are False. WMPRFAF was published in 2005, you don’t have an excuse for not thinking critically about your sources.
Despite this, they don’t even mention lithium, which seems like an oversight.

We wish the paper tried to provide a useful conclusion. It would have been great to read them making their best case for pretty much anything. Contaminants are responsible for 50% of the epidemic. Contaminants are responsible for no more than 10% of the epidemic. Contaminants are responsible for more than 90% of the epidemic. We think phthalates are the biggest cause. We think DDT is the biggest cause. We think it’s air pollution and atrazine. Make a case for something. That would be cool.
What is not cool is showing up being like: Hey we have a big paper! The obesity epidemic is caused by chemicals, perhaps, in what might possibly be your food and water, or at work, though if it’s not, they aren’t. This is a huge deal if this is what caused the epidemic, possibly, unless it didn’t. The epidemic is caused by any of these several dozen compounds, unless it’s just one, or maybe none of them. What percentage of the epidemic is caused by these compounds? It’s impossible to say. But if we had to guess, somewhere between zero and one hundred percent. Unless it isn’t.
Effect Size
The paper spends almost no time talking about effect size, which we think is 1) a weird choice and 2) the wrong approach for this question.
We don’t just care about which contaminants make you gain weight. We care about which contaminants make you gain a concerning amount of weight. We want to know which contaminants have led to the ~40 lbs gain in average body weight since 1970, not which of them can cause 0.1 lbs of weight gain if you’re inhaling them every day at work. These differences are more than just important, they’re the question we’re actually interested in!
For comparison: coffee and airplane travel are both carcinogens, but they increase your risk of cancer by such a small degree that it’s not even worth thinking about, unless you’re a pilot with an espresso addiction. When the paper says “Chemical ABC is an obesogen”, it would be great to see some analysis of whether it’s an obesogen like how getting 10 minutes of sunshine is a carcinogen, or whether it’s an obesogen like how spending a day at the Chernobyl plant is a carcinogen. Otherwise we’re on to “bananas are radioactive” levels of science reporting — technically true, but useless and kind of misleading.
The huge number of contaminants they list does seem like a mark in favor of a “the obesity epidemic is massively multi-causal” hypothesis (which we discussed a bit in this interview), but again it’s hard to tell without seeing a better attempt to estimate effect sizes. The closest thing to an estimate that we saw was this line: “Population attributable risk of obesity from maternal smoking was estimated at 5.5% in the US and up to 10% in areas with higher smoking rates”.
Stress Testing
Their conclusion is especially lacking. It’s one thing to point out that what we’re studying is hard, but it’s another thing to deny the possibility of victory. Let’s look at a few quotes:
“A persistent key question is what percent of obesity is due to genetics, stress, overnutrition, lack of exercise, viruses, drugs or obesogens? It is virtually impossible to answer that question for any contributing factors… it is difficult to determine the exact effects of obesogens on obesity because each chemical is different, people are different, and exposures vary regionally and globally.”
Imagine going to an oncology conference and the keynote speaker gets up and says, “it is difficult to determine the exact effects of radiation on cancer because each radiation source is different, people are different, and exposures vary regionally and globally”. While much of this is true, oncologists don’t say this sort of thing (we hope?) because they understand that while the problem is indeed hard, it’s important, and hold out hope that solving that problem is not “virtually impossible”. Indeed, we’re pretty sure it’s not.
They’re pretty pessimistic about future research options:
“We cannot run actual ‘clinical trials’ where exposure to obesogens and their effects are monitored over time. Thus, we focus on assessing the strength of the data for each obesogen.”
Assessing the strength of the data is a good idea, but this is leaving a lot on the table. Natural experiments are happening all the time, and you don’t need clinical trials to infer causality. We’d like to chastise this paper with the following words:
[Before] we set about instructing our colleagues in other fields, it will be proper to consider a problem fundamental to our own. How in the first place do we detect these relationships between sickness, injury and conditions of work? How do we determine what are physical, chemical and psychological hazards of occupation, and in particular those that are rare and not easily recognized?
There are, of course, instances in which we can reasonably answer these questions from the general body of medical knowledge. A particular, and perhaps extreme, physical environment cannot fail to be harmful; a particular chemical is known to be toxic to man and therefore suspect on the factory floor. Sometimes, alternatively, we may be able to consider what might a particular environment do to man, and then see whether such consequences are indeed to be found. But more often than not we have no such guidance, no such means of proceeding; more often than not we are dependent upon our observation and enumeration of defined events for which we then seek antecedents.
… However, before deducing ‘causation’ and taking action we shall not invariably have to sit around awaiting the results of the research. The whole chain may have to be unraveled or a few links may suffice. It will depend upon circumstances.
Sir Austin Bradford Hill said that, and we’d say he knows a little more about clinical trials than you do, pal, because HE INVENTED THEM. And then he perfected them so that no living physician could best him in the Ring of Honor–

So we think the “no clinical trials” thing is a non-issue. Sir Austin Bradford Hill and colleagues were able to discover the connection between cigarette smoking and lung cancer without forcing people to smoke more than they were already smoking. You really can do medical research without clinical trials.

But even so, the paper is just wrong. We can run clinical trials. People do occasionally lose weight, sometimes huge amounts of weight. So we can try removing potential obesogens from the environment and seeing if that leads to weight loss. If we do it in a controlled manner, we can get some pretty strong evidence about whether or not specific contaminants are causing obesity.
Defeatism
Our final and biggest problem with this paper is that it is so tragically defeatist. It leaves you totally unsure as to what would be informative additional research. It doesn’t show a clear path forward. It’s pessimistic. And it’s tedious as hell. All of this is bad for morale.
The paper’s suggestions seem like a list of good ways to spend forever on this problem and win as many grants as possible. This seems “good” for the scientists in the narrow sense that it will help them keep their tedious desk jobs, jobs which we think they all secretly hate. It’s “good” in that it lets you keep playing what Erik Hoel describes as “the Science Game” for as long as possible:
When you have a lab, you need grant money. Not just for yourself, but for the postdoctoral researchers and PhDs who depend on you for their livelihoods. … much of what goes on in academia is really the Science Game™. … varying some variable with infinite degrees of freedom and then throwing statistics at it until you get that reportable p-value and write up a narrative short story around it.
Think of it like grasping a dial, and each time you turn it slightly you produce a unique scientific publication. Such repeatable mechanisms for scientific papers are the dials everyone wants. Playing the Science Game™ means asking a question with a slightly different methodology each time, maybe throwing in a slightly different statistical analysis. When you’re done with all those variations, just go back and vary the original question a little bit. Publications galore.
If this is your MO, then “more research is needed” is the happiest sound in the world. Actually solving a problem, on the other hand, is kind of terrifying. You would need to find a new thing to investigate! It’s much safer to do inconclusive work on the same problem for decades.
This is part of why we find the suggestion to move towards research with “model organisms such as Drosophila, C. elegans, zebrafish, and medaka” so suspicious. Will this solve the obesity epidemic? Probably not, and certainly not any time this decade. Will it allow you to generate a lot of different papers on exposing Drosophila, C. elegans, zebrafish, and medaka to slightly different amounts of every chemical imaginable? Absolutely.
(As Paul Graham describes, “research must be substantial– and awkward systems yield meatier papers, because you can write about the obstacles you have to overcome in order to get things done. Nothing yields meaty problems like starting with the wrong assumptions.’”)
With all due respect to this approach, we do NOT want to work on obesity for the rest of our lives. We want to solve obesity in the next few years and move on to something else. We think that this is what you want to happen too! Wouldn’t it be nice to at least consider that we might make immediate progress on serious problems? What ever happened to that?
Political Scientist Adolph Reed Jr. once wrote that modern liberalism has no particular place it wants to go. “Its métier,” he said, “is bearing witness, demonstrating solidarity, and the event or the gesture. Its reflex is to ‘send messages’ to those in power, to make statements, and to stand with or for the oppressed. This dilettantish politics is partly the heritage of a generation of defeat and marginalization, of decades without any possibility of challenging power or influencing policy.“
In this paper, we encounter a scientific tradition that no longer has any place it wants to go (“curing obesity? what’s that?”), that makes stands but has a hard time imagining taking action, that is the heir to a generation of defeat and marginalization. All that remains is a reflex of bearing witness to suffering.

We think research can be better than this. That it can be active and optimistic. That it can dare to dream. That it can make an effort to be interesting.
Why do we keep complaining about this paper being boring? Why does it matter? It matters because when the paper is boring, it suggests that the idea that obesity is caused by contaminants isn’t important enough to bother spending time on the writing. It suggests people won’t be interested to read the paper, that no one cares, that no care should be taken in the discussion. That nothing can be gained by thinking clearly about these ideas. It suggests that the prospect of curing obesity isn’t exciting. But we think that the prospect of curing obesity is very exciting, and we hope you do too!