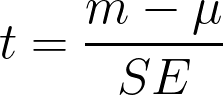A natural prediction of the idea that anorexia is the result of a paradoxical reaction to the same contaminants that cause obesity is that we should observe anorexia nervosa in animals as well as in humans.
All the animals we have data on are getting fatter, but some species are gaining weight faster than others. It’s very likely that there will also be major differences in the rate and degree of paradoxical reactions. It would be very surprising if these contaminants affect mice in the exact same way they affect lizards or stingrays.
When we look at obesity data for animals, we see that primates appear to be gaining more weight than other species, and this makes sense. Primates are more closely related to humans than other animals are, so anything that causes obesity in humans is more likely to cause obesity in primates than in other mammals, and more likely cause obesity in mammals than in non-mammals, etc. As a result, we expect that anorexia is also most likely to be found in other primates.
Testing this prediction is a bit tricky. A wild animal that develops anorexia will likely die. As a result it won’t be around for us to observe, and won’t end up in our data. While pets and lab animals receive a higher standard of care, they may not survive either.
As far as we can tell, when veterinarians notice that an animal is underweight and not eating, they don’t generally record this as an instance of an eating disorder. Instead, when a young animal doesn’t eat and eventually wastes away, this is often classified as “failure to thrive.” This is further complicated by the fact that veterinarians use the term anorexia to refer to any case where an animal isn’t eating, treating it as a symptom rather than a disorder. For example, a dog might not eat because it has an ulcer, or has accidentally consumed a toxic substance, and this would be recorded as anorexia. In humans, we would call this something like loss of appetite, which is itself a symptom of many disorders — including anorexia nervosa. (We’d love to hear from any vets with expertise in this area.)
As a consequence of all this, we don’t expect to find much direct evidence for anorexia in different species of animals. We do however expect there to be plenty of statistical evidence, because there are many statistical signatures that we can look for.
One thing we can look for is increased variance in body weights. Everyone knows that the average BMI has been going up for decades, but what is less commonly known is that the variance of BMI has also increased since 1975. When expressed in standard deviation, it has almost doubled in many countries. As correctly noted in The Lancet, this “contributed to an increase in the prevalence of people at either or both extremes of BMI.”
We should expect that animals today will have higher variation of body weights than they did in the past, just like humans do. We can similarly expect that animals that live in captivity will have higher variation of body weights than animals that live in the wild.
A particularly telling sign of this will be that while animals today (or in captivity) will on average be fatter than animals in the past (or in the wild), the leanest animals will actually be in the modern (or captive) group. We may not see animals with recognizable anorexia, but we should expect to see animals that are thinner than they would be naturally, which is presumably thinner than is healthy for them.
We might also expect to see different patterns by sex. In humans, women have higher variance of body weights than men do, which may explain why anorexia is more common in women than in men. This may not be the case in all species — it may even reverse. But a gender effect is what we see in humans and so we might also expect to see it in other animals as well.
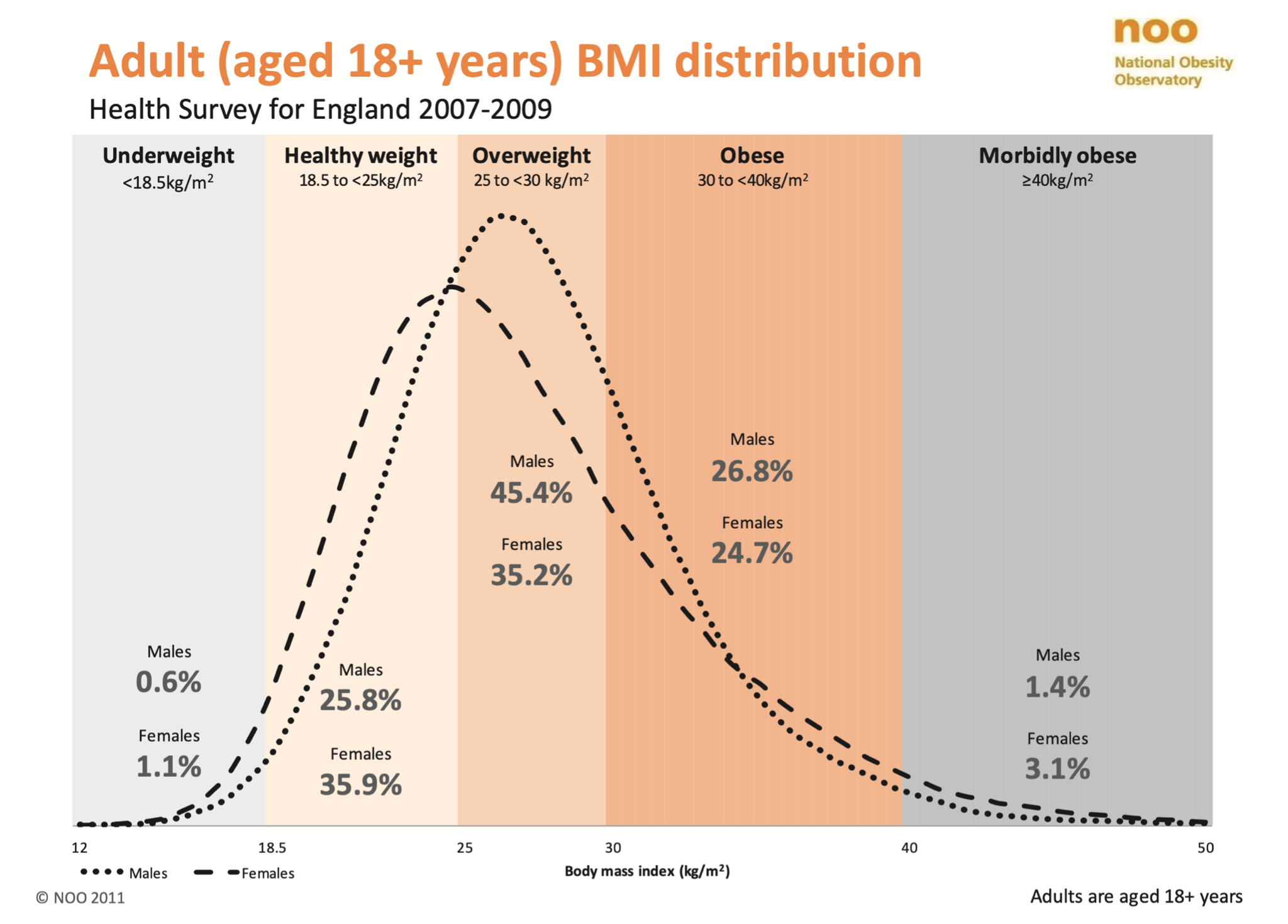
Obesity in English Adults. Note that the distribution for women has a higher variance, which leads to more underweight AND more morbidly obese women than men.
Long-Tail Macaques
In nonhuman animals, we use BMI equivalents. Sterck and colleagues developed a weight-for-height index for long-tail macaques which they called WHI2.7, which can function much like BMI does for humans.
For BMI in humans, values above 25 are considered overweight and values below 18.5 are considered underweight. For WHI2.7, the authors suggest that values above 62 indicate the macaque is overweight and values below 39 indicate the macaque is underweight.
Sterck and colleagues developed this measure by looking at macaques in their current population of research subjects, but they also compared the measurements of their research population to the measurements of the founder generation at Utrecht University from 1987 to 1989, and to some measurements of wild macaques from Indonesia in 1989.
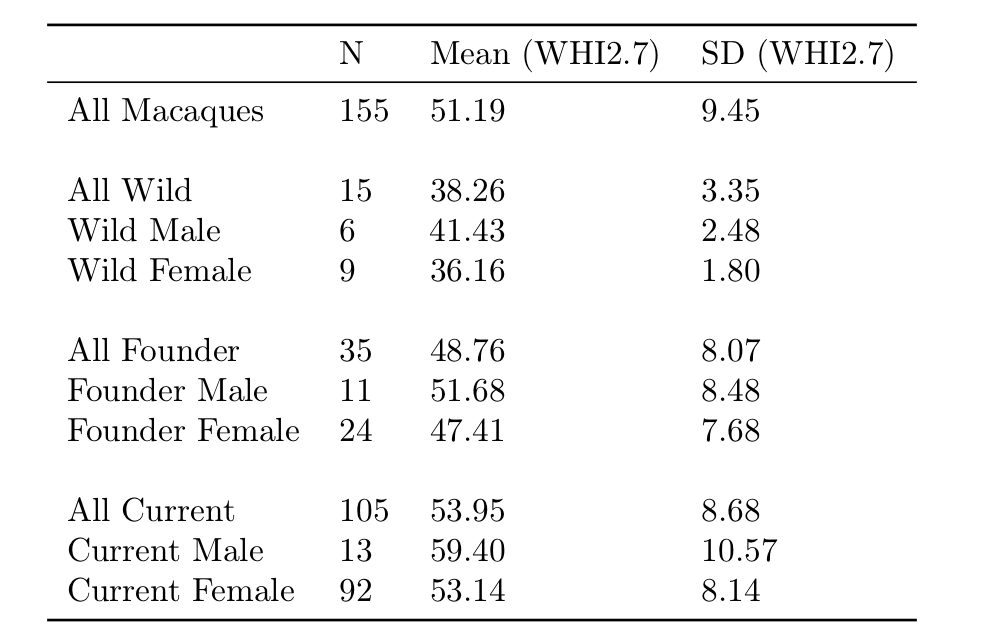
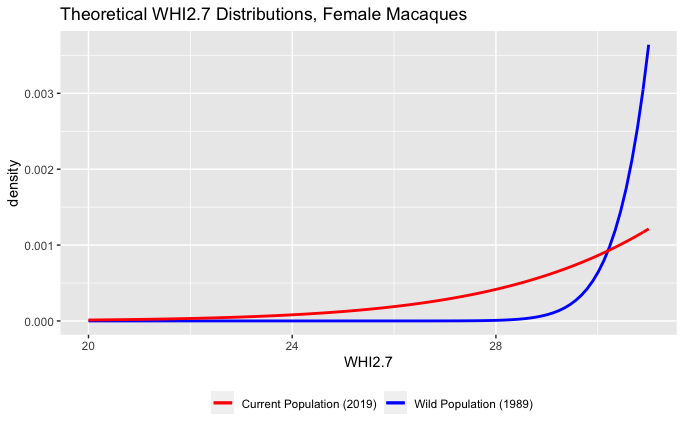
Consistent with other observations of lab animals, we see that the macaques in the research population in 2019 are quite a bit fatter than the wild macaques in the 1980s (see table & figure below). The current population has an average WHI2.7 of 53.95, while the wild macaques had an average WHI2.7 of only 38.26. The current macaques are also quite a bit fatter than their ancestors, the founder group from the 1980s, who had an average WHI2.7 of 48.76.
WHI2.7 means and standard deviations for the three populations of long-tailed macaques described in Sterck et al., 2019
When we look at the standard deviations of these weight-height indexes, we find that the wild macaques in 1989 had a standard deviation of only 3.35, while the current population in 2019 had a standard deviation of 8.68! The founder population was somewhere in between, with a standard deviation of 8.07 (and this is slightly inflated by one extreme outlier). As macaques in captivity become more overweight and obese, the variance in their weight also increases. We can note that the standard deviation more than doubled between wild macaques and the current research population, and this is similar to the change in the standard deviation of human BMIs from 1975 to now, which approximately doubled.
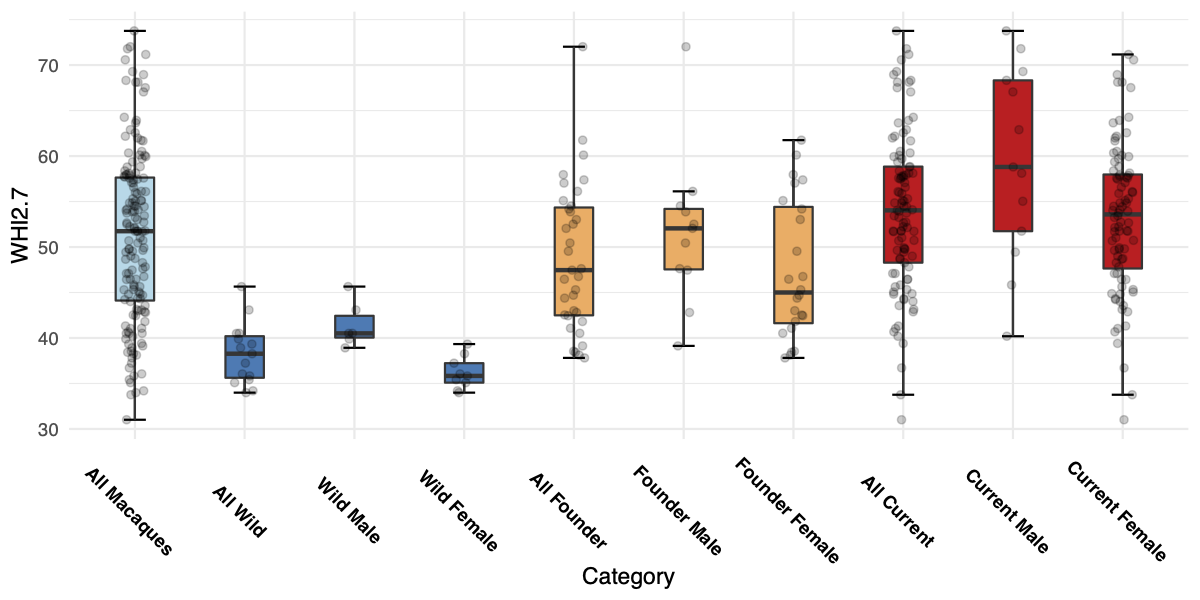
WHI2.7 means and standard deviations for the three populations of long-tailed macaques described in Sterck et al., 2019
The wild monkeys were the leanest on average, with most of the wild females slightly underweight by the WHI2.7 measure. But the very leanest monkeys are actually in the current population, just as predicted. The leanest wild macaque had a WHI2.7 of 34.0, but the two leanest monkeys overall are both in the current population, and had WHI2.7 of 33.8 and 31.0. All of these leanest individuals were female.
As these observations suggest, there are consistent sex effects. In all three groups, male macaques have higher average WHI2.7 scores than females. In the wild group, the distributions barely overlap at all — the leanest male has a score just barely below that of the heaviest female.
Taking sex into account, the change in variance is even more pronounced. The wild macaques had a standard deviation in WHI2.7 scores of 3.35, but because the male and female distributions were largely separate, the standard deviation for males was 2.48 and the standard deviation for females was only 1.80.
This means that for the female macaques, the standard deviation of body composition scores increased by a factor of more than 4.5x, from 1.80 in the wild population to 8.14 in the current population.
We can use these data to make reasonable inferences about what we would see with a larger population. Weight and adiposity tend to be approximately normally distributed, and when we look at the distribution for WHI2.7 in these data, we see that the scores are indeed approximately normally distributed.
For these analyses, we’ll limit ourselves to the female macaques exclusively. Every underweight macaque in this dataset is female — not a single male macaque is classified as underweight. In every group, the mean WHI2.7 is higher for males than it is for females. Just as in humans, being underweight seems to be more of a concern for females than for males.
We could use this information to estimate what percent of macaques are underweight (WHI2.7 of 39 or less). But this doesn’t make sense because we already know that the wild macaques are underweight on average (mean WHI2.7 of 38.26). This is because that threshold, a WHI2.7 of 39, is based on the body fat percentage observed in these same wild macaques.
(This is quite similar to humans who don’t live a western lifestyle. On the Trobriand Islands, the average BMI was historically around 20 for men and around 18 among women, technically underweight by today’s standards.)
The authors also suggest that a WHI2.7 of 37 is perfectly healthy. Even though some of the macaques have WHI2.7 scores below 37, all macaques were examined by veterinarians as part of the study, and seem to be perfectly healthy (99% had BCS scores above 2.5, which indicates “lean” but not thin and certainly not emaciated). Other sources suggest that macaques can still be healthy even when they are thinner than this. Essentially, the threshold of 39 or even 37 isn’t appropriate for our analysis, because macaques appear to be largely healthy in this range.
While it’s hard to determine what WHI2.7 would indicate that a macaque is dangerously underweight, we’ve based our analysis on the leanest macaques we have data for. All the macaques we have data for have WHI2.7 scores above 30. We know that they were all surviving at this weight and the leanest were rated by the vets as merely thin, not emaciated. As a result, 30 seems like a good cutoff, and we can calculate approximately how many macaques would have a WHI2.7 below 30 in a larger population.
The wild female macaques have an average WHI2.7 of 36.16 with a standard deviation of 1.80. Based on this, in a larger population about 0.03% of wild female macaques would have a WHI2.7 below 30.0.
The female macaques from the current research population have an average WHI2.7 of 53.14 with a standard deviation of 8.14. Based on this, in a larger research population about 0.22% of current macaques would have a WHI2.7 below 30.0.
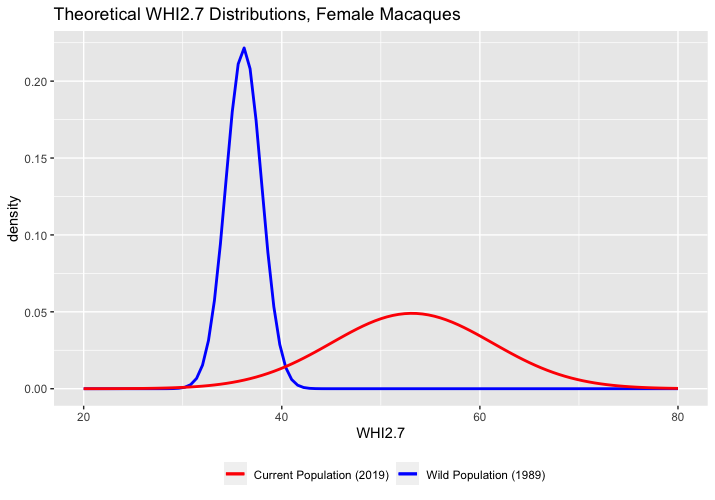
Theoretical distribution of WHI2.7 scores for female macaques in two distributions.
This shows an increase in the mean WHI2.7 and an enormous increase in the variation, just what we would expect to see if anorexia were the result of a paradoxical reaction. In addition, we see that the increase in variation also leads to an increase in the number of extremely underweight macaques (see below). If we tentatively describe a WHI2.7 of 30 or below as anorexic, then the rate of anorexia in female macaques in the current population is about ten times higher than the rate of anorexia in the wild population. The prevalence in the current female research macaques, 0.22%, is also notably similar to the prevalence of anorexia in humans, which is usually estimated to be in the range of 0.1% to 1.0% among women.
Lower tail of the theoretical distribution of WHI2.7 scores for female macaques in two distributions.
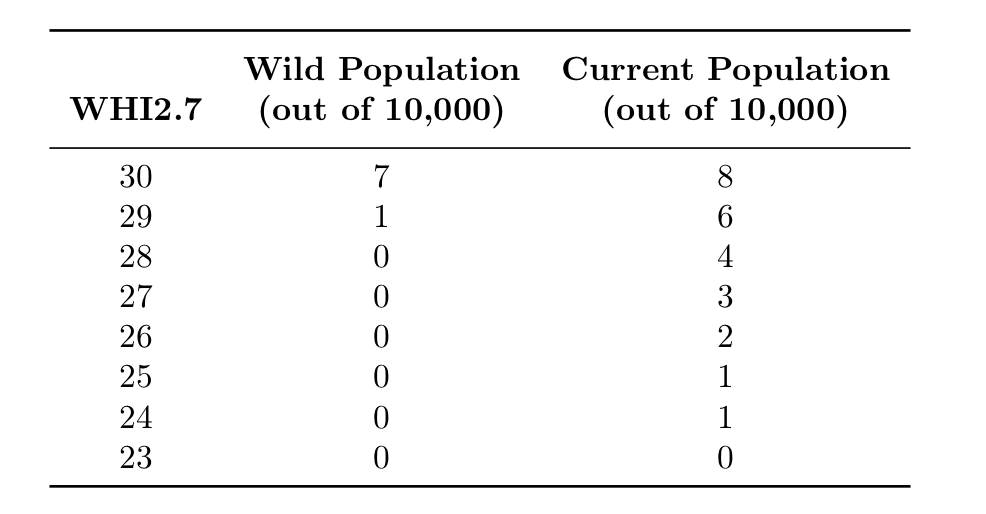
Another way to put this is that if we had a group of 10,000 wild macaques, we would expect about 7 wild macaques with a WHI2.7 of 30, 1 wild macaque with a WHI2.7 of 29, and no wild macaques with a WHI2.7 of 28 or below. In comparison if we had 10,000 macaques from a contemporary research population, we would expect about 8 macaques with a WHI2.7 of 30, about 6 macaques with a WHI2.7 of 29, about 4 macaques with a WHI2.7 of 28, about 3 macaques with a WHI2.7 of 27, about 2 macaques with a WHI2.7 of 26, about 1 macaque with a WHI2.7 of 25, about 1 macaque with a WHI2.7 of 24, and probably no macaques with WHI2.7 scores of 23 or below.
A different cutoff wouldn’t change the effect. For any arbitrary threshold, there will be more modern macaques at the extreme ends of the distribution. Based on what we know about healthy weights for these animals, 30 is a conservative cutoff, and the disparity only increases if we look at lower WHI2.7 scores.
Expected number of macaques with various extremely underweight WHI2.7 scores in different populations of 10,000 macaques.
It seems clear that a macaque with a score of 25 would be an extremely underweight animal, and from a simple analysis of the distributions, we should only expect to see these animals in a modern research population. In short, it’s clear that modern captive macaques have higher rates of anorexia than wild macaques from the 1980s, just the kind of paradoxical reaction this theory predicts.
We come up with theories to try to make sense of the world around us, and we start by trying to come up with a theory that can explain as much of the available evidence as possible.
But one of the known problems with coming up with theories is that sometimes you are overenthusiastic, and connect together lots of things that aren’t actually related. It can be very tempting to cherry-pick evidence to support an idea, and leave out evidence that doesn’t fit the picture. It’s possible to make this mistake honestly — you get excited that things seem to fit together and don’t even notice all the evidence that is stacked against your theory.
But sometimes noticing that things seem to fit together is how an important insight comes to light. The theory of continental drift was invented when Alfred Wegener was looking through a friend’s new atlas and noticed that South America and Africa seemed to have matching coastlines, “like a couple spooning in bed”. He wasn’t even a geologist — at the time, he was an untenured lecturer in meteorology — but he thought that it was important, so he followed up on the idea. “Why should we hesitate to toss the old views overboard?” he said when his father-in-law suggested that he be cautious in his theorizing. He was criticized by geologists in Germany, Britain, and America, in part because he couldn’t describe a mechanism with the power to shuffle the continents around the globe. But in the end, Wegener was right.
The true power of a theory is its ability to make testable predictions. One obvious prediction of the theory that obesity is caused by a contaminant in our environment is that we should also expect to see paradoxical reactions to that contaminant.
Predicting Paradoxical Reactions
Sometimes drugs have what’s called a paradoxical reaction, where the drug does the opposite of the thing it normally does. For example, amphetamines are usually a stimulant, but in a small percent of cases, they make people drowsy instead. Antidepressants usually make people less suicidal, but sometimes they make people more suicidal.
Normally when we talk about paradoxical reactions, we’re talking about the intended effect of the drug, not the side effects. But from the drug’s point of view, there’s no such thing as side effects — all effects are just effects. As a result, we should expect to sometimes see paradoxical reactions in side effects as well.
And in fact, we do. A common side effect of the sedative alprazolam is rapid weight gain. But another common side effect is rapid weight loss. Clinical trials show both side effects regularly. One trial of 1,388 people found that 27% of patients experienced weight gain and 23% of patients experienced weight loss. In those who do lose weight, weight loss is correlated with the dose (r = .35, p = .006).
Normally the weight loss from these paradoxical reactions is pretty limited. But occasionally people lose huge amounts. People can gain 4 lbs (1.8 kg) over only 17 days on alprazolam. In comparison, anecdotal reports from admitted abusers suggest that high doses of alprazolam can lead you to eventually lose 10 or even 40 lbs.
AGRP neurons are a population of neurons closely related to feeding. One of the ways researchers established this connection was by showing that activating these neurons in mice led to “voracious feeding within minutes.” Another way they showed this connection was by destroying these neurons, a process called ablation. “AGRP neuron ablation in adult mice,” reviews one paper, “leads to anorexia.”
If weight gain is the main effect of a drug, the paradoxical reaction is weight loss. If the obesity epidemic is caused by one or more contaminants that cause weight gain, we should expect that there will be some level of paradoxical reaction as well. If obesity is the condition, the paradoxical condition would be anorexia.
If it’s possible to turn the lipostat up, leading to serious weight gain, it’s certainly possible to turn the lipostat down as well, leading to serious weight loss. For most people, these environmental contaminants cause weight gain. But just like with other drugs, in some people there’s a paradoxical reaction instead.
Low BMI has traditionally been viewed as a consequence of the psychological features of anorexia nervosa (that is, drive for thinness and body dissatisfaction). This perspective has failed to yield interventions that reliably lead to sustained weight gain and psychological recovery. Fundamental metabolic dysregulation may contribute to the exceptional difficulty that individuals with anorexia nervosa have in maintaining a healthy BMI (even after therapeutic renourishment). Our results encourage consideration of both metabolic and psychological drivers of anorexia nervosa when exploring new avenues for treating this frequently lethal illness.
Brain lesions alone can cause anorexia nervosa, complete with the characteristic psychopathologies like fear of fatness, drive for thinness, and body image disturbance. Many cases present as “typical” anorexia nervosa, complete with weight and shape preoccupations. When tumors are surgically removed, these symptoms go away and the patients return to a healthy weight.
Brain lesions are not the only purely biological issue that can cause anorexia. In some cases, it appears to be closely related to the gut microbiome. In one case study a patient with anorexia had a BMI of only 15 even after undergoing cognitive-behavioral therapy, medication, and short-term force feeding, and despite maintaining a diet of 2,500 calories per day. Physicians gave her a fecal microbiota transplant from an unrelated donor with a BMI of 25. Following the transplant she gained 6.3 kg (13.9 lbs) over the next 36 weeks, despite not increasing her calorie intake at all. This is only one case, but the authors indicate that they are planning to conduct a randomized controlled trial to investigate the effects of fecal transplants in individuals suffering with anorexia. To the best of our knowledge this next study has not yet been published, but we look forward to seeing the results.
Eating and maintaining weight is a central cognitive problem. “The lipostat does much more than simply regulate appetite,” says Stephan Guyenet, “It’s so deeply rooted in the brain that it has the ability to hijack a broad swath of brain functions, including emotions and cognition.”
Remember those children we mentioned in Part II, who were born without the ability to produce leptin? Unlike normal teenagers, they aren’t interested in dating, films, or music. All they want to talk about is food. “Everything they do, think about, talk about, has to do with food,” says one of the lead researchers in the field. A popular topic of conversation among these teens is recipes.
These teenagers have a serious genetic disorder. But if you put average people in a similar situation, they behave the same way. The Minnesota Starvation Experiment put conscientious objectors on a diet of 1,560 calories per day. Naturally, these volunteers became very hungry, and soon found themselves unable to socialize, think clearly, or open heavy doors.
As they lost weight, these men developed a remarkable obsession with food. The researchers came to call this “semistarvation neurosis”. Volunteers’ thoughts, conversations, dreams, and fantasies all centered on food. They became fascinated by the paraphernalia of eating. “We not only cleaned our plates, we licked them,” recalled one volunteer. “Talked about food, thought about it. Some people collected as many as 25 or 30 cookbooks” (one such collection is pictured below). Others collected cooking utensils. “What we enjoyed doing was to see other people eat,” he continued. “We would go into a restaurant and order just a cup of coffee and sit and watch other people eat.”
Subjects became overwhelmingly preoccupied with food, and some collected dozens of cookbooks, like the collection shown above.
These are the neuroses of people whose bodies believe that they are dangerously thin, either correctly (as in the starvation experiment) or incorrectly (as in the teenagers with leptin deficiency). The same thing happens when your mind, correctly or incorrectly, believes that you are dangerously fat. You become obsessed with food and eating, only in this case, you become obsessed with avoiding both. A classic symptom of anorexia is “preoccupations and rituals concerning food”. If that doesn’t describe the behavior above, I’m not sure what would.
But avoiding food and collecting cookbooks isn’t the lipostat’s only method for controlling body weight. It has a number of other tricks up its sleeve.
Many people burn off extra calories through a behavior called “non-exercise activity thermogenesis” (NEAT). This is basically a fancy term for fidgeting. When a person has consumed more calories than they need, their lipostat can boost calorie expenditure by making them fidget, make small movements, and change posture frequently. It’s largely involuntary, and most people aren’t aware that they’re burning off extra calories in this way. Even so, NEAT can burn off nearly 700 calories per day.
This kind of fidgeting is the classic response in people whose bodies are fatter than they want to be. In studies where people were overfed until they were 10% heavier than their baseline, NEAT increased dramatically. All of this is strong evidence that people with anorexia have lipostats that mistakenly think they desperately need to lose weight.
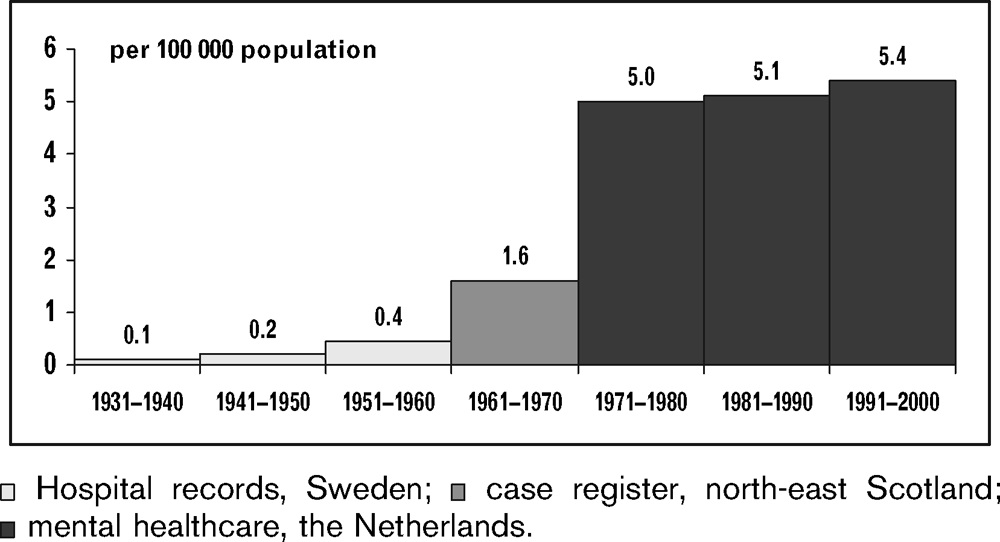
Of course, this does sound a little far-fetched. If anorexia were really a paradoxical reaction to the same contaminants that cause obesity, then in the past we would see almost no anorexia in the population, up to a sharp spike around 1980…
Registered yearly incidence of anorexia nervosa in mental healthcare in northern Europe in the 20th century
In general the data is pretty scattered and spotty. Rarely does a study look at rates in the same area for more than five years. When there are such comparisons, they are usually for periods before 1980. For example, van’t Hof and Nicolson, writing in 1996 and arguing that rates of anorexia are not increasing, at one point cite studies that showed no increase from 1935-1979, 1935-1940, 1975-1980, and 1955-1960. But data from the Global Health Data Exchange (GHDx) shows that rates of eating disorders have been increasing worldwide since 1990, from about 0.185% to 0.215%. This trend is small but reliable — 87.5% of countries saw their rates of eating disorders increase since 1990.
(If that’s not enough for you, we can mention that in 1985 the New York Times reported, “before the 1970’s, most people had never heard of anorexia nervosa.” Writing in the 1980s, presumably they would know.)
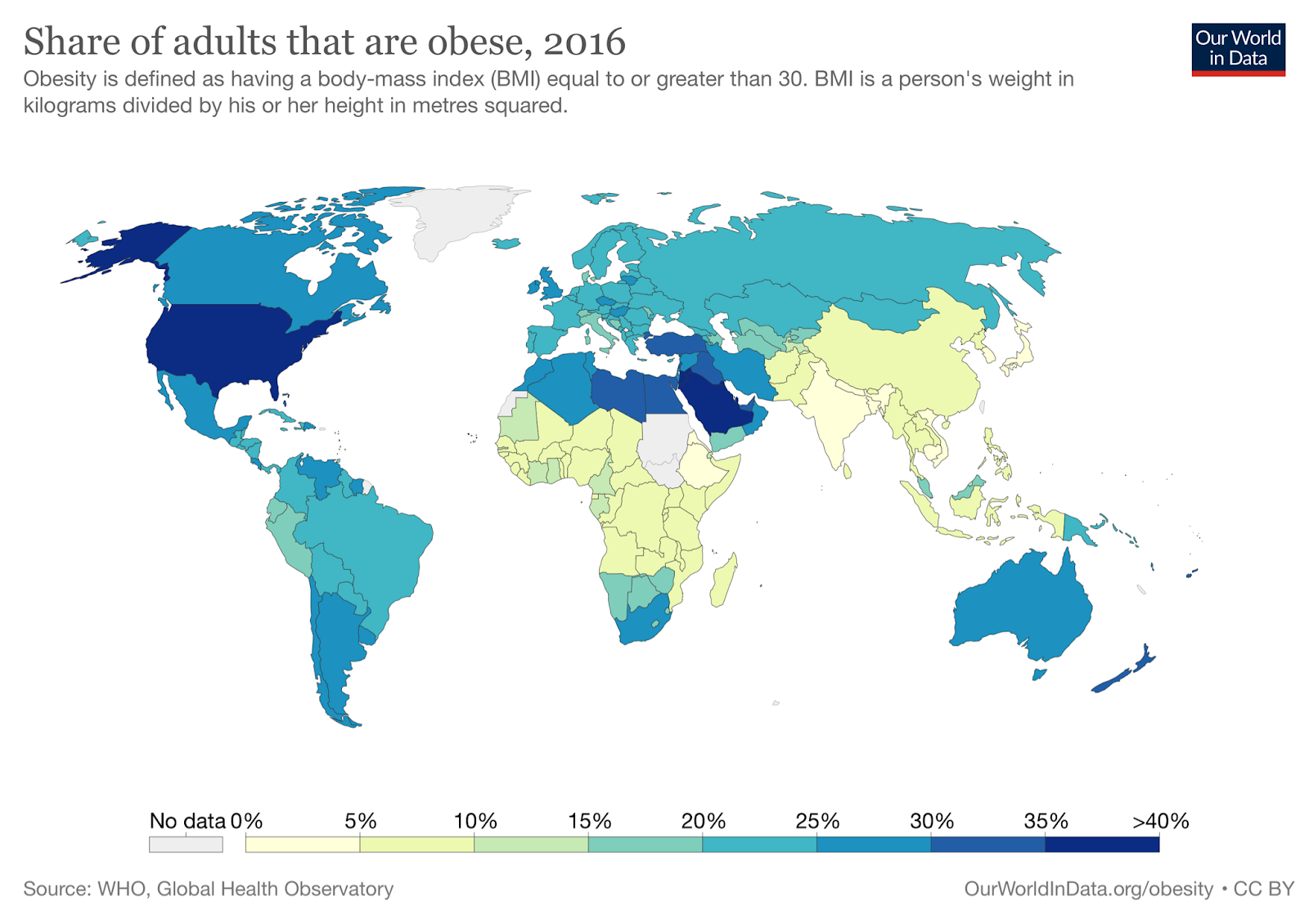
Share of Adults that are Obese, 2016. Reproduced from ourworldindata.org under the CC BY 4.0 license.
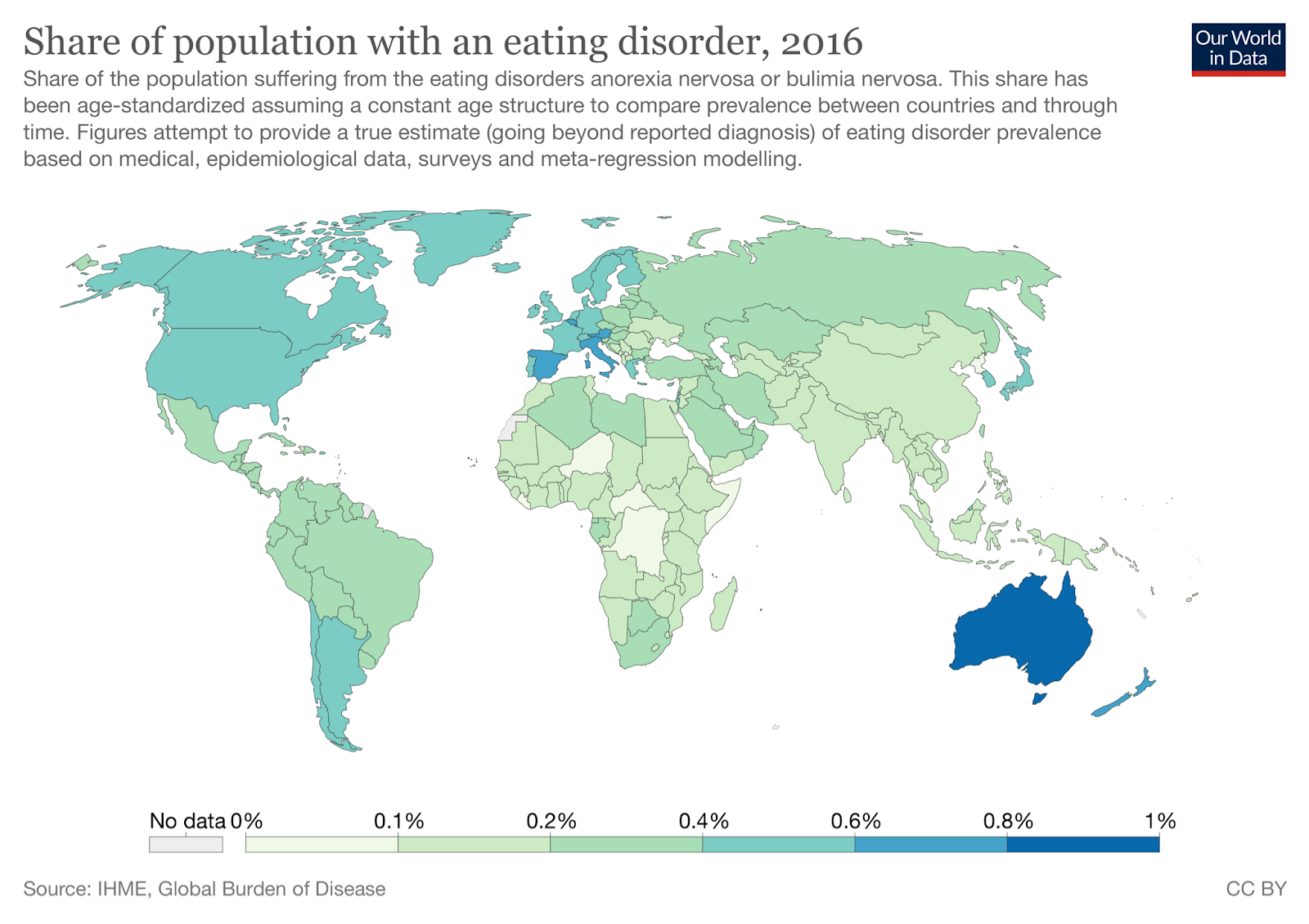
Share of Population with an Eating Disorder, 2016. Reproduced from ourworldindata.org under the CC BY 4.0 license.
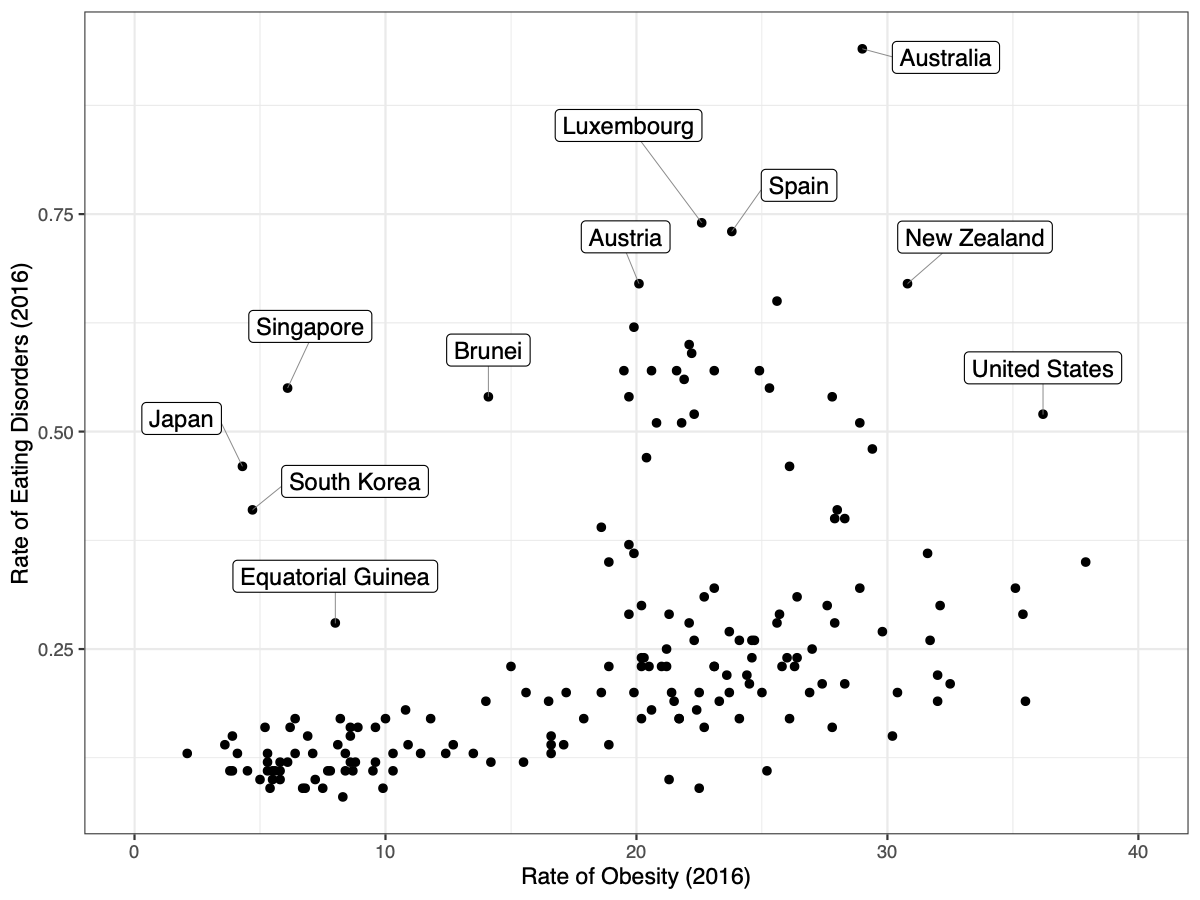
With the exception of a few notable outliers (genetically homogeneous South Korea and Japan), these match up really well. The fit isn’t perfect, but we shouldn’t expect it to be. There are large genetic differences and differences in healthcare practices between these countries. They may use different criteria to diagnose eating disorders. But even given these concerns, we still see pretty strong associations — Chile, Argentina, and Uruguay are the most obese countries in South America, and they also have the highest rates of eating disorders.
We can go one step further. Looking at the data, we see that these are statistically related. In 2016, rates of eating disorders were correlated with obesity in the 185 countries where we have measures for both, r = .33, p < .001. If we remove the five tiny island nations with abnormally high (> 45%) obesity (Kiribati, Marshall Islands, Micronesia, Samoa, and Tonga), all of them with populations of less than 200,000 people, the correlation is r = .46:
Prevalence of eating disorders and obesity, 2016. Kiribati, Marshall Islands, Micronesia, Samoa, and Tonga not shown.
We see the same correlation between rates of obesity and rates of eating disorders when we look at the data from 1990, r = .37, p < .001.
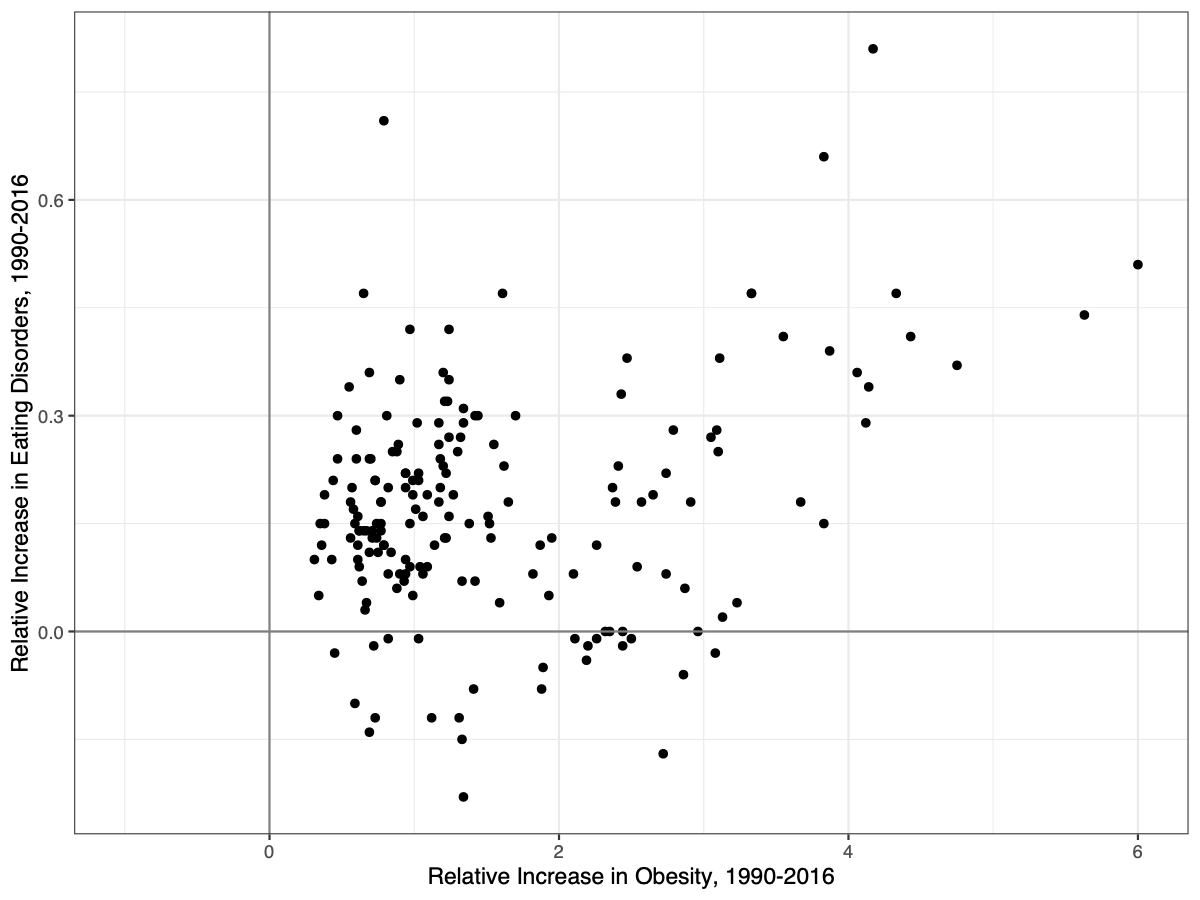
Perhaps most compelling, we find that the rate of change in obesity between 1990 and 2016 is correlated with the rate of change in eating disorders between 1990 and 2016. The correlation is r = .26, p = .0004, and it’s r = .30 if we kick out Equatorial Guinea, a country where the rates of eating disorders tripled between 1990 and 2016, when none of the other countries even had their rates double. You can see those data (minus Equatorial Guinea) below:
Increase in the prevalence of eating disorders and obesity, 1990-2016. Equatorial Guinea not shown.
That’s no joke. The countries that are becoming more obese are also having higher and higher rates of eating disorders.
We even see signs of a paradoxical reaction in some of the contaminants we reviewed earlier. You’ll remember that when mice are exposed to low doses of PFOA in-utero, they are fatter as adults — but when mice are exposed to high doses as adults, they lose weight instead. The dose and the stage of development at exposure seems to matter, at least in mice. It’s notable that anorexia most often occurs in teenagers and young adults, especially young women. Are young women being exposed to large doses all of a sudden, just as they start going through puberty? Where would these huge doses come from? It may not be that much of a stretch — PFAS are included in many cosmetics.
In one study of 3M employees, higher PFOS levels led to a higher average BMI, but also to a wider range in general. The lightest people in the study had some of the highest levels of PFOS in their blood. The quartile with the least PFOS in their blood had an average BMI of 25.8 and a range of BMIs from 19.2 to 40. The quartile with the most PFOS in their blood had an average BMI of 27.2 and a range of BMIs from 17.8 to 45.5. Remember, a BMI of below 18.5 is considered underweight.
In the study of newborn deliveries in Baltimore that we mentioned earlier, researchers found that obese mothers had babies with higher levels of PFOS than mothers of a healthy weight. But underweight mothers also had babies with higher levels of PFOS. In fact, babies from underweight mothers had the highest levels of PFOS exposure, 5.9 ng/mL, compared to 5.4 ng/mL in obese mothers, and 4.8 ng/mL in mothers of normal weight. “The finding that levels were higher among obese and underweight mothers is interesting,” they say, “but does not have an obvious explanation.” Knowing what we know now, the obvious explanation is that PFOS usually causes weight gain, but like all drugs, it sometimes has a paradoxical reaction, resulting in weight loss instead.
Per- and polyfluoroalkyl substances (PFAS) are a group of synthetic chemicals that are used to make a wide variety of everyday products, including food packaging, carpets, rugs, upholstered furniture, nonstick cookware, water-repellant outdoor gear like tents and jackets, firefighting foams, ski wax, clothing, and cleaning products. Many are also used in industrial, aerospace, construction, automotive, and electronic applications.
The PFAS family is enormous, containing over 5,000 different compounds. But only a couple of these compounds are well-studied. The rest remain rather mysterious. Perfluorooctanoic acid (PFOA) and perfluorooctane sulfonate (PFOS) are two of the original PFAS, are especially widespread in the environment, and we tend to have the most information on them.
PFAS are practically indestructible. They repel oil and water and are heat-resistant, which is part of why they have so many applications, but these features also ensure that they degrade very slowly in the environment, if they degrade at all. Short-chain PFAS have half-lives of 1-2 years, but longer-chain equivalents like PFOS are stable enough that we haven’t been able to determine their half-life. As a result, they stick around in the environment for a very long time, and soon make their way into soil and groundwater. The full picture is complicated, but there’s evidence that they accumulate in rivers as they flow towards the ocean.
They not only stick around for a long time in the environment, they stick around for a long time in your body. If you’re reading this, there’s probably PFAS in your blood. A CDC report from 2015 found PFAS in the blood of 97% of Americans, and a 2019 NRDC report found that the half-life of PFAS in the human body is on the order of years. They estimate 2.3 – 3.8 years for PFOA, 5.4 years for PFOS, 8.5 years for PFHxS, and 2.5 – 4.3 years for PFNA. “PFOS, PFNA, PFHxS, and related PFAS,” they write, “are known to bioaccumulate in the bodies of people of all ages, even before birth.”
How do these chemicals get into our bodies? Every route imaginable. “People are concurrently exposed to dozens of PFAS chemicals daily,” the NRDC report explains, “through their drinking water, food, air, indoor dust, carpets, furniture, personal care products, and clothing. As a result, PFAS are now present throughout our environment and in the bodies of virtually all Americans.” Looking at one map of PFAS measurements, we see that PFAS has been detected at military sites in 49 states (no measurements given for Hawaii) and in drinking water in Utqiagvik, Alaska, the northernmost incorporated place in the United States. Unfortunately, only a few states have done comprehensive testing.
This exposure isn’t just limited to humans. There’s bioaccumulation in the remote lichen-caribou-wolf food chain in northern Canada, and in part of the Arctic Ocean, with animals higher in the food chain showing higher concentrations of PFAS in their bodies.
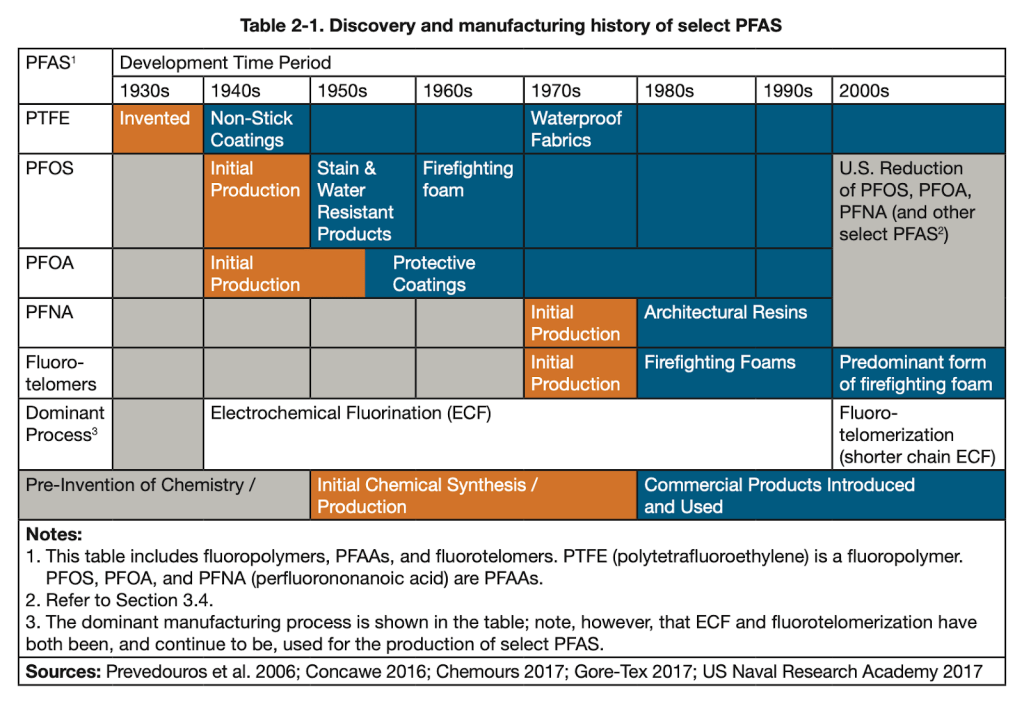
If we look at the history of PFAS (below), we see that the timeline for PFAS introduction lines up pretty well with the timeline for the obesity epidemic. PFAS were invented in the 1930s, 40s, and 50s, and were rolled out over the next couple decades. This gave them some time to build up in people’s bodies and in the environment. By the 1980’s many types, including some new compounds, were in circulation. In the 2000s, some of them began to be banned, but many of them are still widely used. After all, there are more than 5,000 of them, so it’s hard to keep track.
Discovery and manufacturing history of select PFAS.
A study from the Red Cross worked with blood donor data and measured serum levels in samples from 2000-2001 and plasma levels in samples from 2006, 2010, and 2015. In general, they found serious declines in serum levels of the PFAS they examined. For example, the average PFOS concentrations went from 35.1 ng/mL to 4.3 ng/mL, a decline of 88%, and PFNA concentrations went from 0.6 ng/mL to 0.4 ng/mL, a decline of 33%. The National Health and Nutrition Examination Survey (NHANES) data from the same period matches these trends pretty closely.
These studies show that levels of PFAS in American blood are declining, but they’re only looking at the PFAS that we already know are declining. Many of these PFAS are no longer in production. PFOS and PFOA, among other compounds, were phased out in the US between 2006 and 2015. But new compounds with similar structures were brought in to replace them. The companies that make these compounds say that the new PFAS are safer, but unsurprisingly this is very controversial.
Notably absent from both the Red Cross and the NHANES data is PTFE. This is somewhat surprising given that it is the original PFAS, and it is still in production. Granted, many sources claim that PTFE is extremely inert — including the paper Polytetrafluoroethylene Ingestion as a Way to Increase Food Volume and Hence Satiety Without IncreasingCalorie Content, which goes on to argue that we should replace 25% of our food with Teflon (PTFE) powder so that we feel more full while eating fewer calories, which they say will help us make “the leap into the realm of zero calorie foods.” Personally, we’d stick to celery.
Advertisement for the Happy Pan, a Teflon-coated pan from the 1960s.
In one study they gave monkeys various amounts of PFOS for 182 days, and found “significant adverse effects” only in the 0.75 mg/kg/day dose group. Effects in this group included “mortality in 2 of 6 male monkeys, decreased body weights, increased liver weights, lowered serum total cholesterol, lowered triiodothyronine concentrations (without evidence of hypothyroidism), and lowered estradiol levels.”
This is interesting, but there are some problems. First of all, 0.75 mg/kg/day is an insanely high dose. Serum concentrations in the 0.15 mg/kg/day dosage group were 82,600 ng/mL for males and 66,800 ng/mL for females. The comparable rate in human blood samples is about 20-30 ng/mL. Second, 182 days is not a very long or realistic exposure period for most humans.
At these extremely high, short-term doses, weight loss is actually a relatively common side effect. This is the opposite of obesity, of course, but it does suggest that PFAS can affect body weight.
The type of exposure might make the difference. Mice have very different developmental trajectories than we do, but mice exposed to low doses of PFOA in-utero had higher body weights at low exposures, while mice exposed to high doses as adults lost weight. ”Exposure during adulthood was not associated with later-life body weight effects,” they write, “whereas low-dose developmental exposure led to greater weight in adulthood and increased serum leptin and insulin levels. Animals exposed to higher doses of PFOA, on the other hand, had decreased weight.” Note also that while half-life of PFOA in humans is about 3.8 years, in mice it is around 18 days.
A study of 665 pregnant Danish women, recruited in 1988–1989 with the researchers following up with the children 20 years later, found that in-utero PFOA exposure was related to greater BMI and waist circumference in female but not in male children. There are some issues with multiple comparisons — they measured more than one PFAS and they subdivided by gender, both of which are degrees of freedom — but the effects are strong enough to survive reasonable corrections for multiple comparisons, and are consistent with the results from mice, so let’s mark this one down as “suggestive”.
Other studies have found small but reliable effects where male babies, but not female babies, were a few grams lighter at birth when their mothers had higher serum PFOS levels. Again this study suffers from multiple comparison issues, but again it is relatively consistent with animal research.
It doesn’t seem likely that the effect in humans can be exclusively prenatal, however, because we know that people often gain weight when they move to a more obese country. There’s pretty good evidence that different environments are exposing you to different levels of contamination, and that it makes a difference.
Your drinking water is not the only way to be exposed. Many foods are contaminated with PFAS. PFAS are also found in clothes, carpets, and upholstered furniture, so you could be exposed even if there’s no PFAS in your diet. If your favorite beer or pasta sauce is bottled at a factory where the water source is high in PFAS, you’ll be exposed even if your own drinking water is uncontaminated. And since most major brands are bottled in more than one location, there wouldn’t even be a reliable by-brand effect—you’d need to track it by factory.
A better way to do this comparison might be between countries. In fact, we see what appears to be a pattern: There’s more PFAS in tapwater in the United States than there is in tapwater in China, and there’s more PFAS in tapwater in China than there is in tapwater in Japan. The pattern isn’t perfect, however: There’s even more PFAS in tapwater in France than in the United States, and more in Japan than in Thailand.
Occupational Hazard
One place you might get a lot of reliable exposure, though, is at your job. Looking at the uses of PFAS, we see that they’re common in:
Firefighting foams
Cookware and food packaging
Paints and varnishes
Cleaning products
Automotive applications, including components in the engine, fuel systems, and brake systems, as well as automotive interiors like stain-resistant carpets and seats
Healthcare applications, both in medical devices like pacemakers and in medical garments, drapes, and curtains
This suggests that if PFAS are linked to obesity, we should expect to see disproportionate levels of obesity in:
Firefighters
Food workers (especially cooks)
Construction workers
Professional cleaners
Auto mechanics and others who work closely with vehicles
Medical professionals who work closely with medical devices and garments / drapes / curtains, though probably not medical desk jobs.
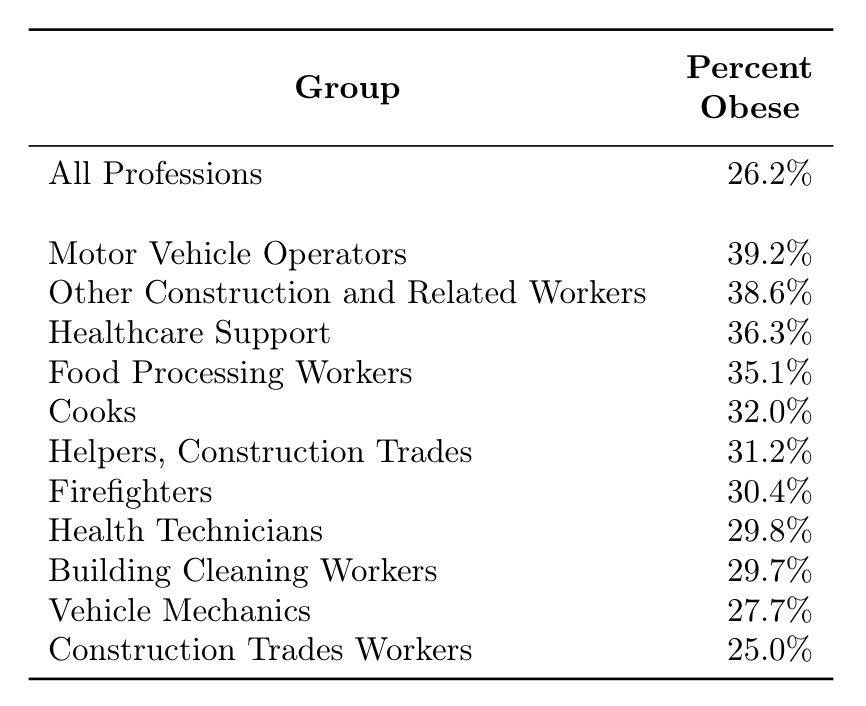
In the 2000’s, the Washington State Department of Labor and Industries surveyed more than 37,000 workers. They found that on average 24.6% of their sample was obese, which we can use as our baseline. The rate of obesity in “protective services”, which includes police, firefighters and emergency responders, was 33.3%. Among cleaning and building services workers, 29.5% were obese. Truck drivers were the most obese group of all, at 38.6%, and mechanics were #5 at 28.9% obese. Health service workers (excluding doctors and nurses) were 28.8% obese. On the other hand, only 20.1% of food preparation workers were obese, and only 19.9% of construction workers:
Table 1: Washington State Department of Labor and Industries Data, 2003-2009
We can also look at national data from US workers in general. Looking at data between 2004 and 2011, we see that the average rate of obesity went from 23.5% in 2004 to 27.6% in 2011, and was 26.2% on average in that range. Unfortunately they break these numbers down by race, so we have to look at each race separately.
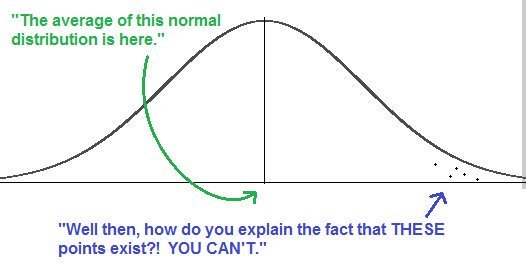
When we look at the occupations of interest for non-hispanic white adults, we see that 30.4% of firefighters, 32.0% of cooks, 35.1% of food processing workers, 29.7% of building cleaning workers (and for some reason a whopping 37.3% of cleaning supervisors), 39.2% of motor vehicle operators, 27.7% of vehicle mechanics, 36.3% of people working in healthcare support, and 29.8% of health technicians were obese (see Table 2 below). Some construction occupations were slightly less obese than average (“Construction trades workers” at 25.0%), and some were much more obese than average (“Helpers, construction trades” and “Other construction and related workers” at 31.2% and 38.6%, respectively).
Table 2: National Health Interview Survey Data, Non-Hispanic White Adults, 2004-2011
For non-hispanic white adults, individuals with the highest age-adjusted prevalence of obesity were motor vehicle operators, “other construction and related workers”, law enforcement workers, and nursing, psychiatric, and home health aides. It’s not clear why law enforcement workers are in there, but it’s pretty remarkable that the PFAS explanation can predict the other three.
Patterns are largely similar for the other racial groups. Among black female workers, the occupations with the highest age-adjusted prevalence of obesity were health care support (49.2%), transportation and material moving (46.6%), protective service (45.8%), personal care and service (45.9%), community and social services (44.7%), food preparation and serving (44.1%), and health care practitioners and technicians (40.2%). Some of these don’t seem to fit — why is “transportation and material moving” in there? — until you realize that “transportation and material moving” includes air traffic controllers, pilots, and other transportation workers, and you remember that PFAS-based firefighting foams are still widely used at airports.
Overall when we look at professions we would expect to have high exposure to PFAS, we see that workers in those professions are more obese than average. When you look at the professions with the highest rates of obesity, we see that most of them are related to mechanical work, healthcare, cleaning, or firefighting, all professions that have disproportionate exposure to PFAS on the job.
If on-the-job PFAS exposure really does lead to obesity, we should also see higher levels of obesity in people who work with PFAS directly. This is exactly what we find.
Looking closer, they found that the group with the highest amount of PFOA contamination also had the highest BMI. The authors even take a moment to draw attention to this point. “It should be noted,” they say, “that all five employees in 1995 with serum PFOA levels [30,000 ng/mL] had BMIs 28.” BMI was slightly correlated with PFOA contamination (r = .11), though with only 111 people, the correlation was not significant. The authors seem unaware of the implications of this, however, and treat BMI as a confounder for other analyses.
Of course, this was not a normal group. They had insanely high serum PFOA levels, up to 115,000 ng/mL, though a few people had no PFAS in their blood.
A later 3M paper published in 2003 looked at serum levels of both PFOA and PFOS. In these data, there is a very clear relationship between PFOS levels and BMI. Men in the lowest quartile of PFOS exposure (mean 270 ng/mL) have an average BMI of 25.8, while men in the highest quartile of PFOS exposure (mean 2,690 ng/mL) have an average BMI of 27.2. The effect is even more pronounced for female employees. Women in the lowest quartile of PFOS exposure (mean 70 ng/mL) have an average BMI of 22.8, while women in the highest quartile of PFOS exposure (mean 1,510 ng/mL) have an average BMI of 28.7. They don’t report a correlation, but they do say, “the fourth quartile had significantly higher mean values than the first quartile for … BMI.”
Dose-Dependent Relationships in the Population
This is somewhat confusing, however, because PFAS serum levels aren’t all that correlated with BMI in the general population. This paper on 2003-2004 NHANES data (a large sample intended to be nationally representative) looked at PFAS concentrations in a final sample of 640 (down from 2,368) people and found only weak evidence of PFAS having an influence on body weight. The strongest relationship they report is for PFOS levels among male participants over 60. Some analyses even report significant negative relationships between PFAS levels and BMI.
Both of these approaches, however, are looking at coefficients in regression equations where they have included many covariates. While in principle this technique can be used to adjust for confounders, in practice the resulting estimates are difficult to interpret. Without a strong model of the causal structure involved, it’s hard to know what the relationship between two variables means when it is adjusted by 20 other variables. Including covariates in an unprincipled way can even cause estimates of an effect to reverse direction. It’s not a panacea, and in fact it can be misleading.
The NHANES data is publicly available, so we decided to check for ourselves. Sure enough, PFOS levels aren’t correlated with BMI — though they are correlated with both weight and height individually.
There’s an issue with looking at simple correlations of PFAS levels, of course, because they are highly correlated with one another. If you have high serum levels of one PFAS, you probably also have high serum levels of another. This means that they may interact or mask one another’s effects in potentially complicated ways.
For example, let’s look at PFHS. A quick correlation shows that serum PFHS levels are negatively correlated with BMI. As far as we can tell, no one has ever reported this, but it’s right there in the NHANES data. In the 2003-2004 data, the correlation is r = -0.090, p < .000045. This effect is small but extremely robust — people exposed to more PFHS are slightly skinnier.
PFHS levels are also correlated with PFOS (r = .29). When we look at the relationship between PFOS and BMI controlling for PFHS, the relationship between PFOS and BMI becomes significant, p = .035, showing that people with higher PFOS exposure are more obese.
“Just wait a minute,” you say, “that’s barely significant at all! How many relationships did you look at before you found that, anyways? This sounds a lot like p-hacking.” We had the same concern, which is why it’s great that we have NHANES data from many different years that we can use to validate this result.
We can go backwards to the 1999-2000 data (we can’t use the 2001-2002 data because the PFAS data for that year are missing ID numbers) where we find a significant relationship between PFOS and BMI controlling for PFHS, p = .008. We can also go forwards to the 2005-2006 data, where we also find a significant relationship between PFOS and BMI controlling for PFHS, p = .007. It seems to be pretty reliable. Now, it’s not a huge effect — the influence of PFOS is only about a half a point of BMI for the average person. But that’s a lot more than nothing.
This isn’t the place for doing a full analysis of the relationships between the different PFAS and how they interact. The NHANES doesn’t even measure every kind of PFAS, so we wouldn’t be able to find every relationship. The point is simply that the influence on BMI may be more complicated than a simple association, and this is proof that at least one of these surprises is hiding in publicly available data.
Why is the association so apparent in the 3M workers but harder to detect in the general population? It has to do with the issues with dose-dependence that we identified earlier. The 3M studies are the sort of samples where we should be able to detect a dose-dependent effect, if one exists. The NHANES data, however, is the sort of sample where it should be hard to detect a dose-dependent effect, even if a strong one exists.
The NHANES data is intended to be nationally representative, while the 3M data is looking at a few hundred people at a couple factories. As a result, the 3M sample is much less diverse than the NHANES sample, which means that it will also be less genetically diverse. Since there’s less genetic diversity, genetics will have less influence on people’s body weight. With less variation coming from people’s genetics, there’s less noise for the dose-dependent signal to be lost in, and it will be easier to detect. Looking at other populations that are not so diverse — like pregnant Danish women between 1996 and 2002 or newborn deliveries at the Johns Hopkins Hospital in Baltimore, MD — we also find that PFAS levels are related to BMI. Similarly, a study from 2021 found a dose-dependent relationship between PFOA — but not PFOS — and obesity in children living in the United States.
The 3M studies are also looking at a much wider range of dosages than are observed in the general population. In the 2003-2004 NHANES data, the range of serum PFOA levels was 0.1 to 77 ng/mL, and the range of serum PFOS levels was 0.3 to 435 ng/mL. In comparison, the range of serum PFOA levels in the 1993 and 1995 3M study was 0 to 115,000 ng/mL. In the 2003 3M study, the range of serum PFOA levels was 10 to 12,700 ng/mL and the range of serum PFOS levels was 40 to 10,060 ng/mL. Analyzing a less restricted range makes the correlation more accurate, which is what we see in the 3M data.
In the 3M sample, some employees participated in both 1993 and in 1995, and PFOA serum levels were highly correlated among the 68 employees who appeared in both samples (r = .91, p = 0.0001). This means that levels of exposure were extremely consistent across the two years between the measurements, possibly because people’s level of exposure was related to the role they had in the production process. Normally, it takes a while for someone’s weight to catch up to the dose of a compound that influences their weight — this is clear from studies of weight gain in people taking antipsychotics. But the 3M employees had serum levels that had been stable for many years. We should expect this to reduce noise and make the correlation between serum levels and BMI more accurate, and it appears to have done just that.
Other Considerations
Dose-dependence is strong evidence that PFAS are a contributor to the obesity epidemic. Is there any other lingering evidence?
One paper looking at a dieting study from 2003 found that PFAS concentration wasn’t related to body weight or weight lost during dieting. However, it was associated with greater weight regain over the months following the diet. People with the highest plasma concentrations of PFAS gained back about 8.8 lbs (4 kg), while people with the lowest plasma concentrations of PFAS gained back only about 4.4 lbs (2 kg). This is a relatively minor but statistically significant difference, and it is consistent with an account where these compounds don’t simply cause weight gain, but damage the lipostat and lead people to defend a higher body weight.
West Virginia is usually an obesity outlier. It’s the #1 or #2 most obese state (depending on your source), and it’s been one of the most obese states for as long as we’ve been keeping statewide records for this sort of thing. But it’s also high in elevation (19th highest after Washington state and Texas) and pretty far upriver. Most of the neighboring states — Ohio (#11), Pennsylvania (#24), Maryland (#26) and Virginia (#28) — are not nearly so obese.
Some people are hopeful that these bans will form a sort of natural experiment that can allow us to see what happens when PFAS are removed from the environment. Unfortunately, we’re less optimistic. First off, these compounds are very durable, so even if we ban them, huge doses will still be in the environment. Second, statewide bans won’t keep these substances from entering the state in food or goods produced elsewhere.
Finally, these bans restrict only a tiny percentage of all PFAS. As a recent report from the European Commission notes, “The ban of widely used long-chain PFAS has led to their substitution with a large number of shorter chain PFAS. Several of these alternatives are now under regulatory scrutiny in the REACH Regulation because of the concern they pose for the environment and for human health.” Efforts to limit exposure to PFAS are a great idea, but the continued use of short-chain PFAS limits the usefulness of bans as natural experiments to determine the role of PFAS in obesity.
Carl Hart is a parent, Columbia professor, and five-year-running recreational heroin user, reports The Guardian. “I do not have a drug-use problem,” he says, “Never have. Each day, I meet my parental, personal and professional responsibilities. I pay my taxes, serve as a volunteer in my community on a regular basis and contribute to the global community as an informed and engaged citizen. I am better for my drug use.”
Hart makes it pretty clear he thinks drug use is a good thing. Good not only for himself, but for people in general. “Most drug-use scenarios cause little or no harm,” he says, “and some reasonable drug-use scenarios are actually beneficial for human health and functioning.” He supports some basic safeguards, including an age limit and possibly an exam-based competency requirement, “like a driver’s licence.” But otherwise, he thinks that most people can take most drugs safely.
The article mentions Hart’s research in passing, but doesn’t describe it. Instead, these claims seem to be based largely on Hart’s personal experiences with drugs. He’s been using heroin for five years and still meets his “parental, personal and professional responsibilities”. He likes to take amphetamine and cocaine “at parties and receptions.” He uses MDMA as a way to reconnect with his wife.
When Hart wondered why people “go on [Ed.: yikes] about heroin withdrawal”, he conducted an ad hoc study on himself, first upping his heroin dose and then stopping (it’s not clear for how long). He describes going through an “uncomfortable” night of withdrawal, but says “he doesn’t feel the need or desire to take more heroin and never [felt] in any real danger.”
This is fascinating, but it seems like there’s a simple individual differences explanation — people differ (probably genetically) in how destructive and addictive they find certain substances, and Hart is presumably just very lucky and doesn’t find heroin (or anything else) all that addictive. This is still consistent with heroin being a terrible drug that ruins people’s lives for the average user.
Let’s imagine a simplified system where everyone either is resistant to a drug and can enjoy it recreationally, or finds it addictive and it ends up destroying their life. For alcohol, maybe 5% of people find it addictive (and become alcoholics) and the other 95% of us can enjoy it without any risk. In this case, society agrees that alcohol is safe for most people and we keep it legal.
But for heroin, maybe 80% of people would find it addictive if they tried it. Even if 20% of people would be able to safely enjoy recreational heroin, you don’t know if it will destroy your life or not until you try it, so it’s a very risky bet. As a result, society is against heroin use and most people make the reasonable decision to not even try it.
Where that ruins-your-life-percentage (RYLP) stands for different drugs matters a lot for the kinds of drugs we want to accept as a society. Certainly a drug with a 0% RYLP should be permitted recreationally, and almost as certainly, a drug that ruined the lives of 100% of first-time users should be regulated in some way. The RYLP for real drugs will presumably lie somewhere in between. While we might see low-RYLP drugs as being worth the risk (our society’s current stance on alcohol), a RYLP of just ten or twenty percent starts looking kind of scary. A drug that ruins the lives of one out of every five first-time users is bad enough — you don’t need a RYLP of 80% for a drug to be very, very dangerous.
Listen, we also believe in the right to take drugs. We take drugs. Drugs good. Most drugs — maybe all drugs — should be legal. But this is very different from pretending that many drugs are not seriously, often dangerously addictive for a large percentage of the population.
As far as we know, drugs like caffeine and THC aren’t seriously addictive and don’t ruin people’s lives. There’s even some fascinating evidence, from Reuven Dar, that nicotine isn’t addictive (though there may be other good reasons to avoid nicotine). But drugs like alcohol and yes, heroin, do seem to be seriously addictive, and recognizing this is important for allowing adults to make informed choices about how they want to get high off their asses.
Hart’s experience with withdrawal, and how he chooses to discuss it, seems particularly clueless. It’s possible that Hart really is able to quit heroin with minimal discomfort, but it’s confusing and kind of condescending that he doesn’t recognize it might be harder for other people. When people say things like, “I find heroin very addictive and withdrawal excruciating,” a good start is to take their reports seriously, not to turn around and say, “well withdrawal was a cakewalk FOR ME.”
This seems to be yet another example of the confusing trend in medicine and biology, where everyone seems to assume that all people are identical and there are no individual differences at all. If an exercise program works for me, it will work equally well for everyone else. If a dietary change cures my heartburn, it will work equally well for everyone’s heartburn. If a painkiller works well for me when I have a headache, it will work equally well for the pain from your chronic illness. The assumption seems to be that people’s bodies (and minds) are made up of a single indifferentiable substance which is identical across all people. But of course, people are different, and this should be neither controversial nor difficult to understand. This is why if you’re taking drugs it’s important to experiment — you need to figure out what works best for you.
This is kind of embarrassing for Carl Hart. He is a professor of neuroscience and psychology. His specialty is neuropsychopharmacology. He absolutely has the statistical and clinical background necessary to understand this point. At the risk of being internally redundant, different people are different from each other. They will have different needs. They will have different responses to the same drugs. Sometimes two people will have OPPOSITE reactions to the SAME drug! Presumably Carl Hart has heard of paradoxical reactions — he should be aware of this.
On the other hand, anyone who sticks their finger in Duterte’s eye is my personal hero. We should cut Hart some slack for generally doing the right thing around a contentious subject, even if we think he is dangerously wrong about this point.
Less slack should be cut for the article itself. This is very embarrassing for The Guardian. Hart is the only person they quote in the entire article. They don’t seem to have interviewed any other experts to see if they might disagree with or qualify Hart’s statements. This is particularly weird because other experts are clearly interested in commenting and the author clearly knows that they might disagree with Hart. They might have asked for a comment from Yale Professor, physician, and (statistically speaking) likely marijuana user, Nicholas Christakis, who would have been happy to offer a counterbalancing opinion. The Guardian was happy to print that Hart is critical of the National Institute on Drug Abuse (NIDA), “in particular of its director, Nora Volkow”, but there’s no indication that they so much as reached out to NIDA or to Volkow for comment (incidentally, here’s what Volkow has to say on the subject).
We can’t be sure, but it’s even possible they somewhat misrepresented Hart’s actual position. It’s disappointing but not surprising when a newspaper doesn’t understand basic statistics, and it would be unfair to hold them to the same standard we hold for Carl Hart. But it is fair to hold them accountable for the basics of journalistic practice, and it seems to us like they dropped the bong on this one.
One of the mysterious aspects of obesity is that it is correlated with altitude. People tend to be leaner at high altitudes and fatter near sea level. Colorado is the highest-altitude US state and also the leanest, with an obesity rate of only 22%. In contrast, low-altitude Louisiana has an obesity rate of about 36%. This is pretty well documented in the literature, and isn’t just limited to the United States. We see the same thing in countries around the world, from Spain to Tibet.
A popular explanation for this phenomenon is the idea that hypoxia, or lack of oxygen, leads to weight loss. The story goes that because the atmosphere is thinner at higher altitudes, the body gets less oxygen, and this ends up making people leaner.
One paper claims to offer final evidence in favor of this theory: Hypobaric Hypoxia Causes Body Weight Reduction in Obese Subjects by Lippl, Neubauer, Schipfer, Lichter, Tufman, Otto, & Fischer in 2010. Actually, the webpage says 2012, but the PDF and all other sources say 2010, so whatever.
This study focused on twenty middle-aged obese German men (mean age 55.7, mean BMI 33.7), all of whom normally lived at a low altitude — 571 ± 29 meters above sea level. Participants were first given a medical exam in Munich, Germany (530 meters above sea level) to establish baseline values for all measures. A week later, all twenty of the obese German men, as well as (presumably) the researchers, traveled to “the air‐conditioned Environmental Research Station Schneefernerhaus (UFS, Zugspitze, Germany)”, a former hotel in the Bavarian Alps (2,650 meters above sea level). The hotel/research station “was effortlessly reached by cogwheel train and cable car during the afternoon of day 6.”
Patients stayed in the Schneefernerhaus research station for a week, where they “ate and drank without restriction, as they would have at home.” Exercise was “restricted to slow walks throughout the station: more vigorous activity was not permitted.” They note that there was slightly less activity at the research station than there was at low altitudes, “probably due to the limited walking space in the high‐altitude research station.” Sounds cozy.
During this week-long period at high altitude, the researchers continued collecting measurements of the participants’ health. After the week was through, everyone returned to Munich (530 meters above sea level). At this point the researchers waited four weeks (it’s not clear why) before conducting the final health examinations, at which point the study concluded. We’re not sure what to say about this study design, except that it’s clear the film adaptation should be directed by Wes Anderson.
Schneefernerhaus Research Station. Yes, really.
II.
While this design is amusing, the results are uninspiring.
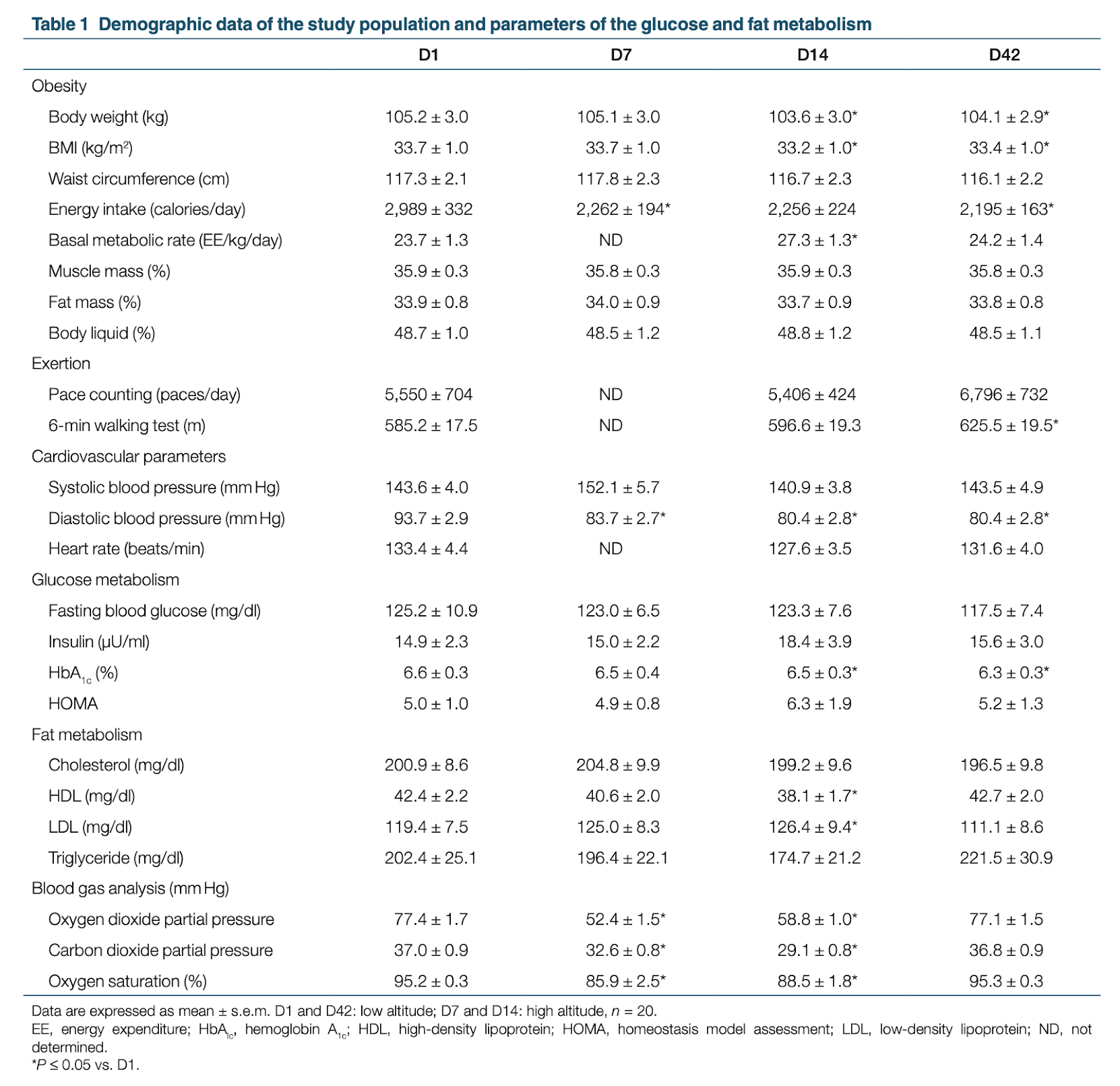
To begin with, the weight loss was minimal. During the week they spent at 2,650 meters, patients lost an average of 3 pounds (1.5 kg). They were an average of 232 lbs (105.1 kg) to begin with, so this is only about 1% of their body weight. Going from 232 lbs (105.1 kg) to 229 lbs (103.6 kg) doesn’t seem clinically relevant, or even all that noticeable. The authors, surprisingly, agree: “the absolute amount of weight loss was so small.”
More importantly, we’re not convinced that this tiny weight loss result is real, because the paper suffers from serious multiple comparison problems. Also known as p-hacking or “questionable research practices”, multiple comparisons are a problem because they can make it very likely to get a false positive. If you run one statistical test, there’s a small chance you will get a false positive, but as you run more tests, false positives get more and more likely. If you run enough tests, you are virtually guaranteed to get a false positive, or many false positives. If you try running many different tests, or try running the same test many different ways, and only report the best one, it’s possible to make pure noise look like a strong finding.
We see evidence of multiple comparisons in the paper. They collect a lot of measures and run a lot of tests. The authors report eight measures of obesity alone, as well many other measures of health.
The week the patients spent at 2,650 meters — Day 7 to Day 14 — is clearly the interval of interest here, but they mostly report comparisons of Day 1 to the other days, and they tend to report all three pairs (D1 to D7, D1 to D14, and D1 to D42), which makes for three times the number of comparisons. It’s also confusing that there are no measures for D21, D28, and D35. Did they not collect data those days, or just not report it? We think they just didn’t collect data, but it’s not clear.
The authors also use a very unusual form of statistical analysis — for each test, first they conducted a nonparametric Friedmann procedure. Then, if that showed a significant rank difference, they did a Wilcoxon signed‐rank method test. It’s pretty strange to run one test conditional on another like this, especially for such a simple comparison. It’s also not clear what role the Friedmann procedure is playing in this analysis. Presumably they are referring to the Friedman test (we assume they don’t mean this procedure for biodiesel analysis) and this is a simple typo, but it’s not clear why they want to rank the means. In addition, the Wilcoxon signed‐rank test seems like a slightly strange choice. The more standard analysis here would be the humble paired t-test.
Even if this really were best practice, there’s no way to know that they didn’t start by running paired t-tests, throwing those results out when they found that they were only trending in the right direction. And in fact, we noticed that if we compare body weight at D7 to D14 using a paired t-test, we find a p-value of .0506, instead of the p < .001 they report when comparing D1 to D14 with a Wilcoxon test. We think that this is the more appropriate analysis, and as you can see, it’s not statistically significant.
Regardless, the whole analysis is called into question by the number of tests they ran. By our count they conducted at least 74 tests in this paper, which is a form of p-hacking and makes the results very hard to interpret. It’s also possible that they conducted even more tests that weren’t reported in the paper. This isn’t really their fault — p-hacking wasn’t described until 2011 (and the term itself wasn’t invented until a few years later), so like most people they were almost certainly unfamiliar with issues of multiple comparisons when they did their analysis. While we don’t accuse the authors of acting in bad faith, we do think this seriously undermines our ability to interpret their results. When we ran the single test that we think was most appropriate, we found that it was not significant.
And of course, the sample size was only 20 people, though perhaps there wasn’t room for many more people in the research station. On one hand this is pretty standard for intensive studies like this, but it reduces the statistical power.
There appear to be about 68 statistical tests in this table alone. Every little star (*) indicates a significant test against the number in D1. It’s hard to tell for sure how many tests they performed here (due to their very weird procedure) but it’s as high as 68.
III.
The authors claim to show that hypoxia causes weight loss, but this is overstating their case. They report that people brought to 2,650 meters lost a small amount of weight and had lower blood oxygen saturation [1], but we think the former result is noise and the latter result is unsurprising. Obviously if you bring people to 2,650 meters they will have lower blood oxygen, and there’s no evidence linking that to the reported weight loss.
Even more concerning is the fact that there’s no control group, which means that this study isn’t even an experiment. Without a control group, there can be no random assignment, and with no random assignment, a study isn’t an experiment. As a result, the strong causal claim the authors draw from their results is pretty unsubstantiated.
There isn’t an obvious fix for this problem. A control group that stayed in Munich wouldn’t be appropriate, because oxygen is confounded with everything else about altitude. If there were a difference between the Munich group and the Schneefernerhaus group, there would be no way to tell if that was due to the amount of oxygen or any of the other thousand differences between the two locations. A better approach would be to bring a control group to the same altitude, and give that control group extra oxygen, though that might introduce its own confounds — for example, the supplemental-oxygen group would all be wearing masks and carrying canisters. I guess the best way to do this would be to bring both groups to the Alps, give both of them canisters and masks, but put real oxygen in the canisters for one group and placebo oxygen (nitrogen?) in the canisters for the other groups.
We’re sympathetic to inferring causal relationships from correlational data, but the authors don’t report a correlation between blood oxygen saturation and weight loss, even though that would be the relevant test given the data that they have. Probably they don’t report it because it’s not significant. They do report, “We could not find a significant correlation between oxygen saturation or oxygen partial pressure, and either ghrelin or leptin.” These are tests that we might expect to be significant if hypoxia caused weight loss — which suggests that it does not.
Unfortunately, the authors report no evidence for their mechanism and probably don’t have an effect to explain in the first place. This is too bad — the study asks an interesting question, and the design looks good at first. It’s only on reflection that you see that there are serious problems.
Thanks to Nick Brown for reading a draft of this post.
[1] One thing that Nick Brown noticed when he read the first draft of this post is that the oxygen saturation percentages reported for D7 and D14 seem to be dangerously low. We’ve all become more familiar with oxygen saturation measures because of COVID, so you may already know that a normal range is 95-100%. Guidelines generally suggest that levels below 90% are dangerous, and should be cause to seek medical attention, so it’s a little surprising that the average for these 20 men was in the mid-80’s during their week at high altitude. We found this confusing so we looked into it, and it turns out that this is probably not a issue. Not only are lower oxygen saturation levels normal at higher altitudes, the levels can apparently be very low by sea-level standards without becoming dangerous. For example, in this study of residents of El Alto in Bolivia (an elevation of 4018 m), the mean oxygen saturation percentages were in the range of 85-88%. So while this is definitely striking, it’s probably not anything to worry about.
Briefly, Hall et al. (2019) is a metabolic ward study on the effects of “ultra-processed” foods on energy intake and weight gain. The participants were 20 adults, an average of 31.2 years old. They had a mean BMI of 27, so on average participants were slightly overweight, but not obese.
Participants were admitted to the metabolic ward and randomly assigned to one of two conditions. They either ate an ultra-processed diet for two weeks, immediately followed by an unprocessed diet for two weeks — or they ate an unprocessed diet for two weeks, immediately followed by an ultra-processed diet for two weeks. The study was ad libitum, so whether they were eating an unprocessed or an ultra-processed diet, participants were always allowed to eat as much as they wanted — in the words of the authors, “subjects were instructed to consume as much or as little as desired.”
The authors found that people ate more on the ultra-processed diet and gained a small amount of weight, compared to the unprocessed diet, where they ate less and lost a small amount of weight.
We’re not in the habit of re-analyzing published papers, but we decided to take a closer look at this study because a couple of things in the abstract struck us as surprising. Weight change is one main outcome of interest for this study, and several unusual things about this measure stand out immediately. First, the two groups report the same amount of change in body weight, the only difference being that one group gained weight and the other group lost it. In the ultra-processed diet group, people gained 0.9 ± 0.3 kg (p = 0.009), and in the unprocessed diet group, people lost 0.9 ± 0.3 kg (p = 0.007). (Those ± values are standard errors of the mean.) It’s pretty unlikely for the means of both groups to be identical, and it’s very unlikely that both the means and the standard errors would be identical.
It’s not impossible for these numbers to be the same (and in fact, they are not precisely equal in the raw data, though they are still pretty close), especially given that they’re rounded to one decimal place. But it is weird. We ran some simple simulations which suggest that this should only happen about 5% of the time — but this is assuming that the means and SDs of the two groups are both identical in the population, which itself is very unlikely.
Another test of interest reported in the abstract also seemed odd. They report that weight changes were highly correlated with energy intake (r = 0.8, p < 0.0001). This correlation coefficient struck us as surprising, because it’s pretty huge. There are very few measures that are correlated with one another at 0.8 — these are the types of correlations we tend to see between identical twins, or repeated measurements of the same person. As an example, in identical twins, BMI is correlated at about r = 0.8, and height at about r = 0.9.
We know that these points are pretty ticky-tacky stuff. By themselves, they’re not much, but they bothered us. Something already seemed weird, and we hadn’t even gotten past the abstract.
To conduct this analysis, we teamed up with Nick Brown, with additional help from James Heathers. We focused on one particular dependent variable of this study, weight change, while Nick took a broader look at several elements of the paper.
II.
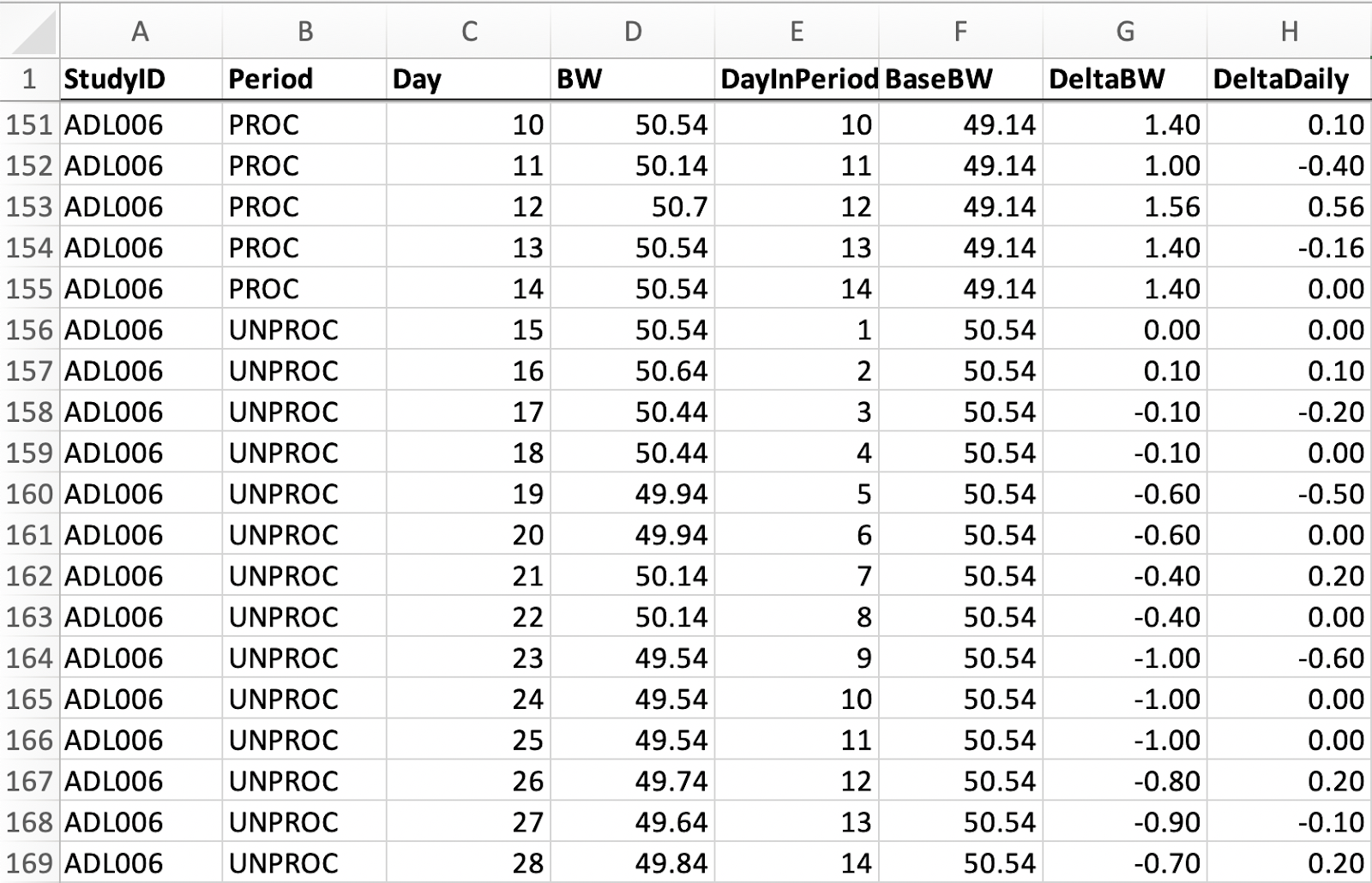
Because we were most interested in weight change, we decided to begin by taking a close look at the file “deltabw”. In mathematics, delta usually means “change” or “the change in”, and “bw” here stands for “body weight”, so this title indicates that the file contains data for the change in participants’ body weights. On the OSF this is in the form of a SAS .sas7bdat file, but we converted it to a .csv file, which is a little easier to work with.
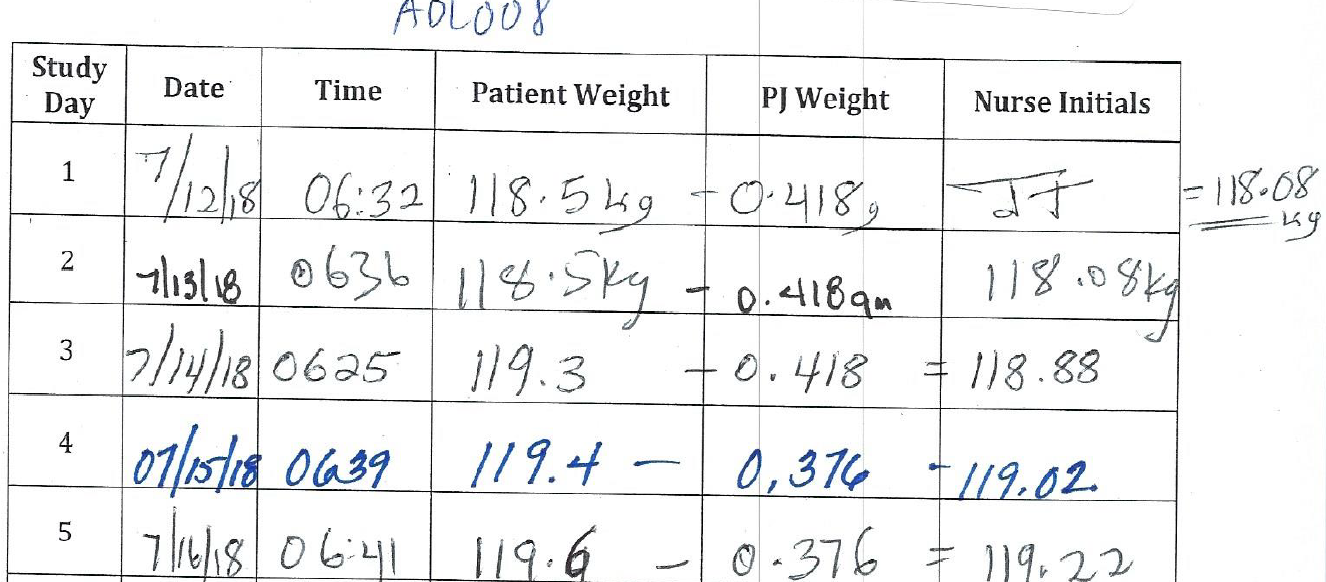
Here’s a screenshot of what the deltabw file looks like:
In this spreadsheet, each row tells us about the weight for one participant on one day of the 4-week-long study. These daily body weight measurements were performed at 6am each morning, so we have one row for every day.
Let’s also orient you to the columns. “StudyID” is the ID for each participant. Here we can see that in this screenshot we are looking just at participant ADL001, or participant 01 for short. The “Period” variable tells us whether the participant was eating an ultra-processed (PROC) or an unprocessed (UNPROC) diet on that day. Here we can see that participant 01 was part of the group who had an unprocessed diet for the first two weeks, before switching to the ultra-processed diet for the last two weeks. “Day” tells us which day in the 28-day study the measurement is from. Here we show only the first 20 days for participant 01.
“BW” is the main variable of interest, as it is the participant’s measured weight, in kilograms, for that day of the study. “DayInPeriod” tells us which day they are on for that particular diet. Each participant goes 14 days on one diet then begins day 1 on the other diet. “BaseBW” is just their weight for day 1 on that period. Participant 01 was 94.87 kg on day one of the unprocessed diet, so this column holds that value as long as they’re on that diet. “DeltaBW” is the difference between their weight on that day and the weight they were at the beginning of that period. For example, participant 01 weighed 94.87 kg on day one and 94.07 kg on day nine, so the DeltaBW value for day nine is -0.80.
Finally, “DeltaDaily” is a variable that we added, which is just a simple calculation of how much the participant’s weight changed each day. If someone weighed 82.85 kg yesterday and they weigh 82.95 kg today, the DeltaDaily would be 0.10, because they gained 0.10 kg in the last 24 hours.
To begin with, we were able to replicate the authors’ main findings. When we don’t round to one decimal place, we see that participants on the ultra-processed diet gained an average of 0.9380 (± 0.3219) kg, and participants on the unprocessed diet lost an average of 0.9085 (± 0.3006) kg. That’s only a difference of 0.0295 kg in absolute values in the means, and 0.0213 kg for the standard errors, which we still find quite surprising. Note that this is different from the concern about standard errors raised by Drs. Mackerras and Blizzard. Many of the standard errors in this paper come from GLM analysis, which assumes homogeneity of variances and often leads to identical standard errors. But these are independently calculated standard errors of the mean for each condition, so it is still somewhat surprising that they are so similar (though not identical).
On average these participants gained and lost impressive, but not shocking amounts of weight. A few of the participants, however, saw weight loss that was very concerning. One woman lost 4.3 kg in 14 days which, to quote Nick Brown, “is what I would expect if she had dysentery” (evocative though perhaps a little excessive). In fact, according to the data, she lost 2.39 kg in the first five days alone. We also notice that this patient was only 67.12 kg (about 148 lbs) to begin with, so such a huge loss is proportionally even more concerning. This is the most extreme case, of course, but not the only case of such intense weight change over such a short period.
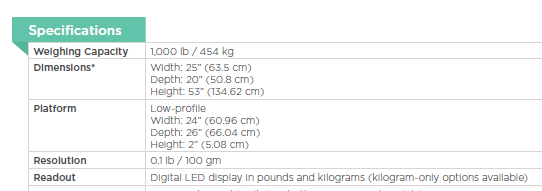
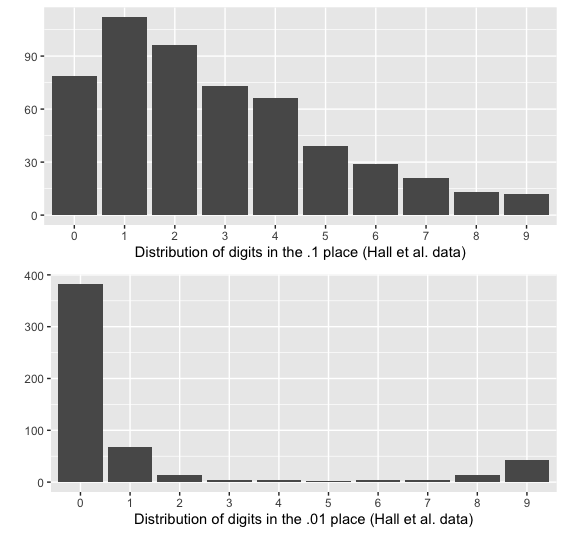
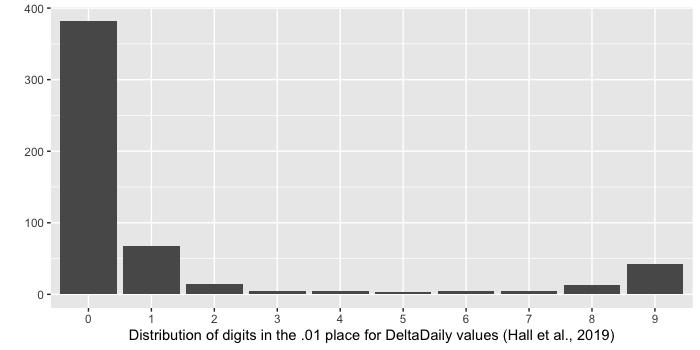
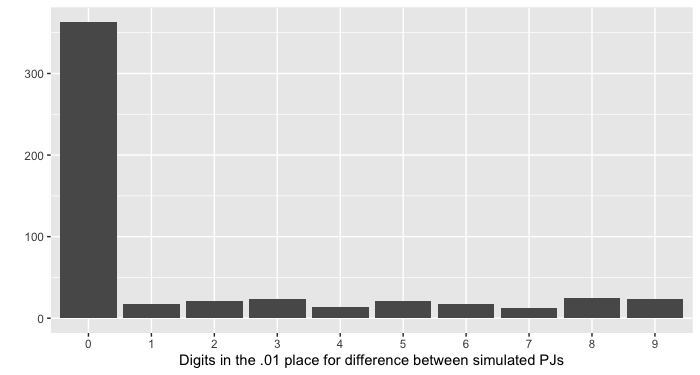
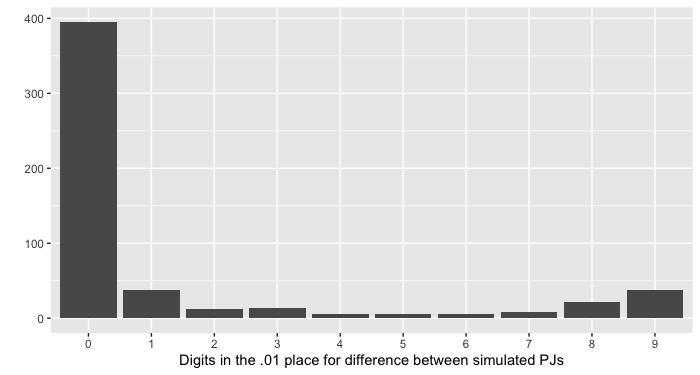
The article tells us that participants were weighed on a Welch Allyn Scale-Tronix 5702 scale, which has a resolution of 0.1 lb or 100 grams (0.1 kg). This means it should only display data to one decimal place. Here’s the manufacturer’s specification sheet for that model. But participant weights in the file deltabw are all reported to two decimal places; that is, with a precision of 0.01 kg, as you can clearly see from the screenshot above. Of the 560 weight readings in the data file, only 55 end in zero. It is not clear how this is possible, since the scale apparently doesn’t display this much precision.
To confirm this, we wrote to Welch Allyn’s customer support department, who confirmed that the model 5702 has 0.1 kg resolution.
We also considered the possibility that the researchers measured people’s weight in pounds and then converted to kilograms, in order to use the scale’s better precision of 0.1 pounds (45.4 grams) rather than 100 grams. However, in this case, one would expect to see that all of the changes in weight were multiples of (approximately) 0.045 kg, which is not what we observe.
III.
As we look closer at the numbers, things get even more confusing.
As we noted, Hall et al. report participant weight to two decimal places in kilograms for every participant on every day. Kilograms to two decimal places should be pretty sensitive, but there are many cases where the exact same weight appears two or even three times in a row. For example, participant 21 is listed as having a weight of exactly 59.32 kg on days 12, 13, and 14, participant 13 is listed as having a weight of exactly 96.43 kg on days 10, 11, and 12, and participant 06 is listed as having a weight of exactly 49.54 kg on days 23, 24, and 25.
Having the same weight for two or even three days in a row may not seem that strange, but it is very remarkable when the measurement is in kilograms precise to two decimal places. After all, 0.01 kg (10 grams) is not very much weight at all. A standard egg weighs about 0.05 kg (50 grams). A shot of liquor is a little less, usually a bit more than 0.03 kg (30 grams). A tablespoon of water is about 0.015 kg (15 grams). This suggests that people’s weights are varying by less than the weight of a tablespoon of water over the course of entire days, and sometimes over multiple days. This uncanny precision seems even more unusual when we note that body weight measurements were taken at 6 am every morning “after the first void”, which suggests that participants’ bodily functions were precise to 0.01 kg on certain days as well.
The case of participant 06 is particularly confusing, as 49.54 kg is exactly one kilogram less, to two decimal places, than the baseline for this participant’s weight when they started, 50.54 kg. Furthermore, in the “unprocessed” period, participant 06 only ever seems to lose or gain weight in full increments of 0.10 kilograms.
We see similar patterns in the data from other participants. Let’s take a look at the DeltaDaily variable. As a reminder, this variable is just the difference between a person’s weight on one day and the day before. These are nothing more than daily changes in weight.
Because these numbers are calculated from the difference between two weight measurements, both of which are reported to two decimal places of accuracy, these numbers should have two places of accuracy as well. But surprisingly, we see that many of these weight changes are in full increments of 0.10.
Take a look at the histograms below. The top histogram is the distribution of weight changes by day. For example, a person might gain 0.10 kg between days 15 and 16, and that would be one of the observations in this histogram.
You’ll see that these data have an extremely unnatural hair-comb pattern of spikes, with only a few observations in between. This is because the vast majority (~71%) of the weight changes are in exact multiples of 0.10, despite the fact that weights and weight changes are reported to two decimal places. That is to say, participants’ weights usually changed in increments like 0.20 kg, -0.10 kg, or 0.40 kg, and almost never in increments like -0.03 kg, 0.12 kg, or 0.28 kg.
For comparison, on the bottom is a sample from a simulated normal distribution with identical n, mean, and standard deviation. You’ll see that there is no hair-comb pattern for these data.
As we mentioned earlier, there are several cases where a participant stays at the exact same weight for two or three days in a row. The distribution we see here is the cause. As you can see, the most common daily change is exactly zero. Now, it’s certainly possible to imagine why some values might end up being zero in a study like this. There might be a technical incident with the scale, a clerical error, or a mistake when recording handwritten data on the computer. A lazy lab assistant might lose their notes, resulting in the previous day’s value being used as the reasonable best estimate. But since a change of exactly zero is the modal response, a full 9% of all measurements, it’s hard to imagine that these are all omissions or technical errors.
In addition, there’s something very strange going on with the trailing digits:
On the top here we have the distribution of digits in the 0.1 place. For example, a measurement of 0.29 kg would appear as a 2 here. This follows about the distribution we would expect, though there are a few more 1’s and fewer 0’s than usual.
The bottom histogram is where things get weird. Here we have the distribution of digits in the 0.01 place. For example, a measurement of 0.29 kg would appear as a 9 here. As you can see, 382/540 of these observations have a 0 in their 0.01’s place — this is the same as that figure of 71% of measured changes being in full increments of 0.10 kg that we mentioned earlier.
The rest of the distribution is also very strange. When the trailing digit is not a zero, it is almost certainly a 1 or a 9, possibly a 2 or an 8, and almost never anything else. Of 540 observed weight changes, only 3 have a trailing digit of 5.
We can see that this is not what we would expect from (simulated) normally distributed data:
It’s also not what we would expect to see if they were measuring to one decimal place most of the time (~70%), but to two decimal places on occasion (~30%). As we’ve already mentioned, this doesn’t make sense from a methodological standpoint, because all daily weights are to two decimal places. But even it somehow were a measurement accuracy issue, we would expect an equal distribution across all the other digits besides zero, like this:
This is certainly not what we see in the reported data. The fact that 1 and 9 are the most likely trailing digit after 0, and that 2 and 8 are most likely after that, is especially strange.
IV.
When we first started looking into this paper, we approached Retraction Watch, who said they considered it a potential story. After completing the analyses above, we shared an early version of this post with Retraction Watch, and with our permission they approached the authors for comment. The authors were kind enough to offer feedback on what we had found, and when we examined their explanation, we found that it clarified a number of our points of confusion.
The first thing they shared with us was this erratum from October 2020, which we hadn’t seen before. The erratum reports that they noticed an error in the documented diet order of one participant. This is an important note but doesn’t affect the analyses we present here, which have very little to do with diet conditions.
Kevin Hall, the first author on this paper, also shared a clarification on how body weights were calculated:
I think I just discovered the likely explanation about the distribution of high-precision digits in the body weight measurements that are the main subject of one of the blogs. It’s kind of illustrative of how difficult it is to fully report experimental methods! It turns out that the body weight measurements were recorded to the 0.1 kg according to the scale precision. However, we subtracted the weight of the subject’s pajamas that were measured using a more precise balance at a single time point. We repeated subtracting the mass of the pajamas on all occasions when the subject wore those pajamas. See the example excerpted below from the original form from one subject who wore the same pajamas (PJs) for three days and then switched to a new set. Obviously, the repeating high precision digits are due to the constant PJs! 😉
This matches what is reported in the paper, where they state, “Subjects wore hospital-issued top and bottom pajamas which were pre-weighed and deducted from scale weight.”
Kevin also included the following image, which shows part of how the data was recorded for one participant:
If we understand this correctly, the first time a participant wore a set of pajamas, the pajamas were weighed to three decimals of precision. Then, that measurement was subtracted from the participant’s weight on the scale (“Patient Weight”) on every consecutive morning, to calculate the participant’s body weight. For an unclear reason, this was recorded to two decimals of precision, rather than the one decimal of precision given by the scale, or the three decimals of precision given by the PJ weights. When the participant switched to a new set of pajamas, the new set was weighed to three decimals of precision, and that number was used to calculate participant body weight until they switched to yet another new set of pajamas, etc.
We assume that the measurement for the pajamas is given in kilograms, even though they write “g” and “gm” (“qm”?) in the column. I wish my undergraduate lab TAs were as forgiving as the editors at Cell Metabolism.
This method does account for the fact that participant body weights were reported to two decimal places of precision, despite the fact that the scale only measures weight to one decimal place of precision. Even so, there were a couple of things that we still found confusing.
The variable that interests us the most is the DeltaDaily variable. We can easily calculate that variable for the provided example, like so:
We can see that whenever a participant doesn’t change their pajamas on consecutive days, there’s a trailing zero. In this way, the pajamas can account for the fact that 71% of the time, the trailing digits in the DeltaDaily variable were zeros.
We also see that whenever the trailing digit is not zero, that lets us identify when a participant has changed their pajamas. Note of course that about ten percent of the time, a change in pajamas will also lead to a trailing digit of zero. So every trailing digit that isn’t zero is a pajama change, though a small number of the zeros will also be “hidden” pajama changes.
In any case, we can use this to make inferences about how often participants change their pajamas, which we find rather confusing. Participants often change their pajamas every day for multiple days in a row, or go long stretches without apparently changing their pajamas at all, and sometimes these are the same participants. It’s possible that these long stretches without any apparent change of pajamas are the result of the “hidden” changes we mentioned, because about 10% of the time changes would happen without the trailing digit changing, but it’s still surprising.
For example, participant 05 changes their pajamas on day 2, day 5, and day 10, and then apparently doesn’t change their pajamas again until day 28, going more than two weeks without a change in PJs. Participant 20, in contrast, changes pajamas at least 16 times over 28 days, including every day for the last four days of the study. The record for this, however, has to go to participant 03, who at one point appears to have switched pajamas every day for at least seven days in a row. Participant 03 then goes eight days in a row without changing pajamas before switching pajamas every day for three days in a row.
Participant 08 (the participant from the image above) seems to change their pajamas only twice during the entire 28-day study, once on day 4 and again on day 28. Certainly this is possible, but it doesn’t look like the pajama-wearing habits we would expect. It’s true that some people probably want to change their pajamas more than others, but this doesn’t seem like it can be entirely attributed to personality, as some people don’t change pajamas at all for a long time, and then start to change them nearly every day, or vice-versa.
We were also unclear on whether the pajamas adjustment could account for the most confusing pattern we saw in the data for this article, the distribution of digits in the .01 place for the DeltaDaily variable:
The pajamas method can explain why there are so many zeros — any day a participant didn’t change their pajamas, there would be a zero, and it’s conceivable that participants only changed their pajamas on 30% of the days they were in the study.
We weren’t sure if the pajamas method could explain the distribution of the other digits. For the trailing digits that aren’t zero, 42% of them are 1’s, 27% of them are 9’s, 9% of them are 2’s, 8% of them are 8’s, and the remaining digits account for only about 3% each. This seems very strange.
You’ll recall that the DeltaDaily values record the changes in participant weights between consecutive days. Because the weight of the scale is only precise to 0.1 kg, the data in the 0.01 place records information about the difference between two different pairs of pajamas. For illustration, in the example Kevin Hall provided, the participant switched between a pair of pajamas weighing 0.418 kg and a pair weighing 0.376 kg. These are different by 0.042 kg, so when they rounded it to two digits, the difference we see in the DeltaDaily has a trailing digit of 4.
We wanted to know if the pajama adjustment could explain why the difference (for the digit in the 0.01’s place) between the weights of two pairs of pajamas are 14x more likely to be a 1 than a 6, or 9x more likely to be a 9 than a 3.
Verbal arguments quickly got very confusing, so we decided to run some simulations. We simulated 20 participants, for 28 days each, just like the actual study. On day one, simulated participants were assigned a starting weight, which was a random integer between 40 and 100. Every day, their weight changed by an amount between -1.5 and 1.5 by increments of 0.1 (-1.5, -1.4, -1.3 … 1.4, 1.5), with each increment having an equal chance of occuring.
The important part of the simulation were the pajamas, of course. Participants were assigned a pajama weight on day 1, and each day they had a 35% chance of changing pajamas, and being assigned a new pajama weight. The real question was how to generate a reasonable distribution of pajama weights. We didn’t have much to go off of, just the two values in the image that Kevin Hall shared with us. But we decided to give it a shot with just that information. Weights of 418 g and 376 g have a mean of just under 400 g and a standard deviation of 30 g, so we decided to sample our pajama weights from a normal distribution with those parameters.
When we ran this simulation, we found a distribution of digits in the 0.01 place that didn’t show the same saddle-shaped distribution as in the data from the paper:
We decided to run some additional simulations, just to be sure. To our surprise, when the SD of the pajamas is smaller, in the range of 10-20 g, you can sometimes get saddle-shaped distributions just like the ones we saw in data from the paper. Here’s an example of what the digits can look like when the SD of the pajamas is 15 g:
It’s hard for us to say whether a standard deviation of 15 g or of 30 g is more realistic for hospital pajamas, but it’s clear that under certain circumstances, pajama adjustments can create this kind of distribution (we propose calling it the “pajama distribution”).
While we find this distribution surprising, we conclude that it is possible given what we know about these data and how the weights were calculated.
V.
When we took a close look at these data, we originally found a number of patterns that we were unable to explain. Having communicated with the authors, we now think that while there are some strange choices in their analysis, most of these patterns can be explained when we take into account the fact that pajama weights were deducted from scale weights, and the two weights had different levels of precision.
While these patterns can be explained by the pajama adjustment described by Kevin Hall, there are some important lessons here. The first, as Kevin notes in his comment, is that it can be very difficult to fully record one’s methods. It would have been better to include the full history of this variable in the data files, including the pajama weights, instead of recording the weights and performing the relevant comparisons by hand.
The second is a lesson about combining data of different levels of precision. The hair-comb pattern that we observed in the distribution of DeltaDaily scores was truly bizarre, and was reason for serious concern. It turns out that this kind of distribution can occur when a measure with one decimal of precision is combined with another measure with three decimals of precision, with the result being rounded to two decimals of precision. In the future researchers should try to avoid combining data in this way to avoid creating such artifacts. While it may not affect their conclusions, it is strange for the authors to claim that someone’s weight changed by (for example) 1.27 kg, when they have no way to measure the change to that level of precision.
There are some more minor points that this explanation does not address, however. We still find it surprising how consistent the weight change was in this study, and how extreme some of the weight changes were. We also remain somewhat confused by how often participants changed (or didn’t change) their pajamas.
This post continues in Part Two over at Nick Brown’s blog, where he covers several other aspects of the study design and data.
Thanks again to Nick Brown for comparing notes with us on this analysis, to James Heathers for helpful comments, and to a couple of early readers who asked to remain anonymous. Special thanks to Kevin Hall and the other authors of the original paper, who have been extremely forthcoming and polite in their correspondence. We look forward to ongoing public discussion of these analyses, as we believe the open exchange of ideas can benefit the scientific community.
Imagine a universe where every cognitive scientist receives extensive training in how to deal with demand characteristics.
(Demand characteristics describe any situation in a study where a participant either figures out what a study is about, or thinks they have, and changes what they do in response. If the participant is friendly and helpful, they may try to give answers that will make the researchers happy; if they have the opposite disposition, they might intentionally give nonsense answers to ruin the experiment. This is a big part of why most studies don’t tell participants what condition they’re in, and why some studies are run double-blind.)
In the real world, most students get one or two lessons about demand characteristics when they take their undergrad methods class. When researchers are talking about a study design, sometimes we mention demand, but only if it seems relevant.
Let’s return to our imaginary universe. Here, things are very different. Demand characteristics are no longer covered in undergraduate methods courses — instead, entire classes are exclusively dedicated to demand characteristics and how to deal with them. If you major in a cognitive science, you’re required to take two whole courses on demand — Introduction to Demand for the Psychological Sciences and Advanced Demand Characteristics.
Often there are advanced courses on specific forms of demand. You might take a course that spends a whole semester looking at the negative-participant role (also known as the “screw-you effect”), or a course on how to use deception to avoid various types of demand.
If you apply to graduate school, how you did in these undergraduate courses will be a major factor determining whether they let you in. If you do get in, you still have to take graduate-level demand courses. These are pretty much the same as the undergrad courses, except they make you read some of the original papers and work through the reasoning for yourself.
When presenting your research in a talk or conference, you can usually expect to get a couple of questions about how you accounted for demand in your design. Students are evaluated based on how well they can talk about demand and how advanced the techniques they use are.
Every journal requires you to include a section on demand characteristics in every paper you submit, and reviewers will often criticize your manuscript because you didn’t account for demand in the way they expected. When you go up for a job, people want to know that you’re qualified to deal with all kinds of demand characteristics. If you have training in dealing with an obscure subtype of demand, it will help you get hired.
It would be pretty crazy to devote such a laser focus to this one tiny aspect of the research process. Yet this is exactly what we do with statistics.
II.
Science is all about alternative explanations. We design studies to rule out as many stories as we can. Whatever stories remain are possible explanations for our observations. Over time, we whittle this down to a small number of well-supported theories.
There’s one alternative explanation that is always a concern. For any relationship we observe, there’s a chance that what we’re seeing is just noise. Statistics is a set of tools designed to deal with this problem. This holds a special place in science because “it was noise” is a concern for every study in every field, so we always want to make sure to rule it out.
But of course, there are many alternative explanations that we need to be concerned with. Whenever you’re dealing with human participants, demand characteristics will also be a possible alternative. Despite this, we don’t jump down people’s throats about demand. We only bring up these issues when we have a reason to suspect that it is a problem for the design we’re looking at.
There will always be more than one way to look at any set of results. We can never rule out every alternative explanation — the best we can do is account for the most important and most likely alternatives. We decide which ones to account for by using our judgement, by taking some time to think about what alternatives we (and our readers) will be most concerned about.
The right answer will look different for different experiments. But the wrong answer is to blindly throw statistics at every single study.
Statistics is useful when a finding looks like it could be the result of noise, but you’re not sure. For example, let’s say we’re testing a new treatment for a disease. We have a group of 100 patients who get the treatment and a control group of 100 people who don’t get the treatment. If 52/100 people recover when they get the treatment, compared to 42/100 recovering in the control group, does that mean the treatment helped? Or is the difference just noise? I can’t tell with just a glance, but a simple chi-squared test can tell me that p = .013, meaning there’s only a 1.3% chance that we would see something like this from noise alone.
That’s helpful, but it would be pointless to run a statistical test if we saw 43/100 people recover with the treatment, compared to 42/100 in the control group. I can tell that this is very consistent with noise (p > .50) just by looking at it. And it would be pointless to run a statistical test if we saw 98/100 people recover with the treatment, compared to 42/100 in the control group. I can tell that this is very inconsistent with noise (p < .00000000000001) just by looking at it. If something passes the interocular trauma test (the conclusion hits you between the eyes), you don’t need to pull out another test.
This might sound outlandish today, but you can do perfectly good science without any statistics at all. After all, statistics is barely more than a hundred years old. Sir Francis Galton came up with the concept of the standard deviation in the 1860s, and the story with the ox didn’t happen until 1907. It took until the 1880s to dream up correlation. Karl Pearson was born in 1857 but didn’t do most of his statistics work until around the turn of the century. Fisher wasn’t even born until 1890. He introduced the term variance for the first time in 1918, but both that term and the ANOVA didn’t gain popularity until the publication of his book in 1925.
This means that Galileo, Newton, Kepler, Hooke, Pasteur, Mendel, Lavoisier, Maxwell, von Helmholtz, Mendeleev, etc. did their work without anything that resembled modern statistics, and that Einstein, Curie, Fermi, Bohr, Heisenberg, etc. etc. did their work in an age when statistics was still extremely rudimentary. We don’t need statistics to do good research.
This isn’t an original idea, or even a particularly new one. When statistics was young, people understood this point better. For an example, we can turn to Sir Austin Bradford Hill. He was trained by Karl Pearson (who, among other things, invented the chi-squared test we used earlier), was briefly president of the Royal Statistical Society, and was sometimes referred to as the world’s leading medical statistician. As early as the 1920s, he was pioneering the introduction of the randomized clinical trial in medicine. As far as opinions on statistics go, the man was pretty qualified.
While you may not know his name, you’re probably familiar with his work. He was one of the researchers who demonstrated the connection between cigarette smoking and lung cancer, and in 1965 he gave a speech about his work on the topic. Most of the speech was a discussion of how one can infer a causal relationship from largely correlational data, as he had done with the smoking-lung cancer connection, a set of considerations that came to be known as the Bradford Hill criteria.
But near the end of the speech, he turns to a discussion of tests of significance, as he calls them, and their limitations:
No formal tests of significance can answer [questions of cause and effect]. Such tests can, and should, remind us of the effects that the play of chance can create, and they will instruct us in the likely magnitude of those effects. Beyond that they contribute nothing to the ‘proof’ of our hypothesis.
Nearly forty years ago, amongst the studies of occupational health that I made for the Industrial Health Research Board of the Medical Research Council was one that concerned the workers in the cotton-spinning mills of Lancashire (Hill 1930). … All this has rightly passed into the limbo of forgotten things. What interests me today is this: My results were set out for men and women separately and for half a dozen age groups in 36 tables. So there were plenty of sums. Yet I cannot find that anywhere I thought it necessary to use a test of significance. The evidence was so clear cut, the differences between the groups were mainly so large, the contrast between respiratory and non-respiratory causes of illness so specific, that no formal tests could really contribute anything of value to the argument. So why use them?
Would we think or act that way today? I rather doubt it. Between the two world wars there was a strong case for emphasizing to the clinician and other research workers the importance of not overlooking the effects of the play of chance upon their data. Perhaps too often generalities were based upon two men and a laboratory dog while the treatment of choice was deducted from a difference between two bedfuls of patients and might easily have no true meaning. It was therefore a useful corrective for statisticians to stress, and to teach the needs for, tests of significance merely to serve as guides to caution before drawing a conclusion, before inflating the particular to the general.
I wonder whether the pendulum has not swung too far – not only with the attentive pupils but even with the statisticians themselves. To decline to draw conclusions without standard errors can surely be just as silly? Fortunately I believe we have not yet gone so far as our friends in the USA where, I am told, some editors of journals will return an article because tests of significance have not been applied. Yet there are innumerable situations in which they are totally unnecessary – because the difference is grotesquely obvious, because it is negligible, or because, whether it be formally significant or not, it is too small to be of any practical importance. What is worse, the glitter of the t-table diverts attention from the inadequacies of the fare. Only a tithe, and an unknown tithe, of the factory personnel volunteer for some procedure or interview, 20% of patients treated in some particular way are lost to sight, 30% of a randomly-drawn sample are never contacted. The sample may, indeed, be akin to that of the man who, according to Swift, ‘had a mind to sell his house and carried a piece of brick in his pocket, which he showed as a pattern to encourage purchasers.’ The writer, the editor and the reader are unmoved. The magic formulae are there.
Of course I exaggerate. Yet too often I suspect we waste a deal of time, we grasp the shadow and lose the substance, we weaken our capacity to interpret the data and to take reasonable decisions whatever the value of P. And far too often we deduce ‘no difference’ from ‘no significant difference.’ Like fire, the chi-squared test is an excellent servant and a bad master.
III.
We grasp the shadow and lose the substance.
As Dr. Hill notes, the blind use of statistical tests is a huge waste of time. Many designs don’t need them; many arguments don’t benefit from them. Despite this, we have long disagreements about which of two tests is most appropriate (even when both of them will be highly significant), we spend time crunching numbers when we already know what we will find, and we demand that manuscripts have their statistics arranged just so — even when it doesn’t matter.
This is an institutional waste of time as well as a personal one. It’s weird that students get so much training in statistics. Methods are almost certainly more important, but most students are forced to take multiple stats classes, while only one or two methods classes are even offered. This is also true at the graduate level. Methods and theory courses are rare in graduate course catalogs, but there is always plenty of statistics.
Some will say that this is because statistics is so much harder to learn than methods. Because it is a more difficult subject, it takes more time to master. Now, it’s true that students tend to take several courses in statistics and come out of them remembering nothing at all about statistics. But this isn’t because statistics is so much more difficult.
We agree that statistical thinking is very important. What we take issue with is the neurotic focus on statistical tests, which are of minor use at best. The problem is that our statistics training spends multiple semesters on tests, while spending little to no time at all on statistical thinking.
This also explains why students don’t learn anything in their statistics classes. Students can tell, even if only unconsciously, that the tests are unimportant, so they have a hard time taking them seriously. They would also do poorly if we asked them to memorize a phone book — so much more so if we asked them to memorize the same phone book for three semesters in a row.
The understanding of these tests is based on statistical thinking, but we don’t teach them that. We’ve become anxious around the tests, and so we devote more and more of the semester to them. But this is like becoming anxious about planes crashing and devoting more of your pilot training time to the procedure for making an emergency landing. If the pilots get less training in the basics, there will be more emergency landings, leading to more anxiety and more training, etc. — it’s a vicious cycle. If you just teach students statistical thinking to begin with, they can see why it’s useful and will be able to easily pick up the less-important tests later on, which is exactly what I found when I taught statistics this way.
The bigger problem is turning our thinking over to machines, especially ones as simple as statistical tests.
Your new overlord.
Sometimes a test is useful, sometimes it is not. We can have discussions about when a test is the right choice and when it is the wrong one. Researchers aren’t perfect, but we have our judgement and damn it, we should be expected to use it. We may be wrong sometimes, but that is better than letting the p-values call all the shots.
We need to stop taking tests so seriously as a criterion for evaluating papers. There’s a reason, of course, that we are on such high alert about these tests — the concept of p-hacking is only a decade old, and questionable statistical practices are still being discovered all the time.
But this focus on statistical issues tends to obscure deeper problems. We know that p-hacking is bad, but a paper with perfect statistics isn’t necessarily good — the methods and theory, even the basic logic, can be total garbage. In fact, this is part of how we got in the p-hacking situation in the first place: by using statistics as the main way of telling if a paper is any good or not!
Putting statistics first is how we end up with studies with beautifully preregistered protocols and immaculate statistics, but deeply confounded methods, on topics that are unimportant and frankly uninteresting. This is what Hill meant when he said that “the glitter of the t-table diverts attention from the inadequacies of the fare”. Confounded methods can produce highly significant p-values without any p-hacking, but that doesn’t mean the results of such a study are of any value at all.
This is why I find proposals to save science by revising statistics so laughable. Surrendering our judgement to Bayes factors instead of p-values won’t do anything to solve our problems. Changing the threshold of significance from .05 to .01, or .005, or even .001 won’t make for better research. We shouldn’t try to revise statistics, we should use it less often.
Thanks to Adam Mastroianni, Grace Rosen, and Alexa Hubbard for reading drafts of this piece.
“Catastrophic failure [of the unhelmeted skull] during testing…experiencing a maximum load of 520 pounds of force,” says the Journal of Neurosurgery: Pediatrics.
According to NASA, the average push strength of an adult male is about 220 lbs of force, with a standard deviation of 68 lbs. If Gregor Clegane were three standard deviations from the mean (the top 0.1%), he would be able to produce about 424 lbs of force, which is not quite enough. He would need to be about 4.5 standard deviations above average to crush a skull with his bare hands.
This is pretty extreme, but if strength is normally distributed in Westeros, Gregor would only be about 1 in 147,160. Another way of saying this is that if one baby were born every day, a man as strong as this would come around about every 403 years. Since birth rates are much higher than that, it’s not impossible.
This is also consistent with what we know about Gregor in general. He’s described as being nearly eight feet tall, or 96 inches. The average height of men in the United States is about 70 inches, with a standard deviation of 4 inches. This means that Gregor is about 6.5 standard deviations taller than average. It seems likely that he would be similarly above average in terms of his strength.
Verdict – it is statistically possible that someone strong enough to crush a skull with their hands exists in Westeros, and Ser Gregor is a good candidate for the role.